-
-
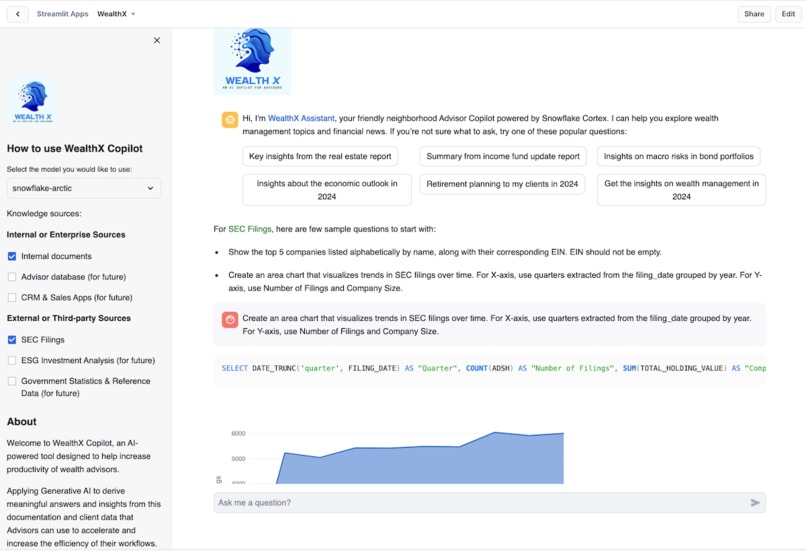
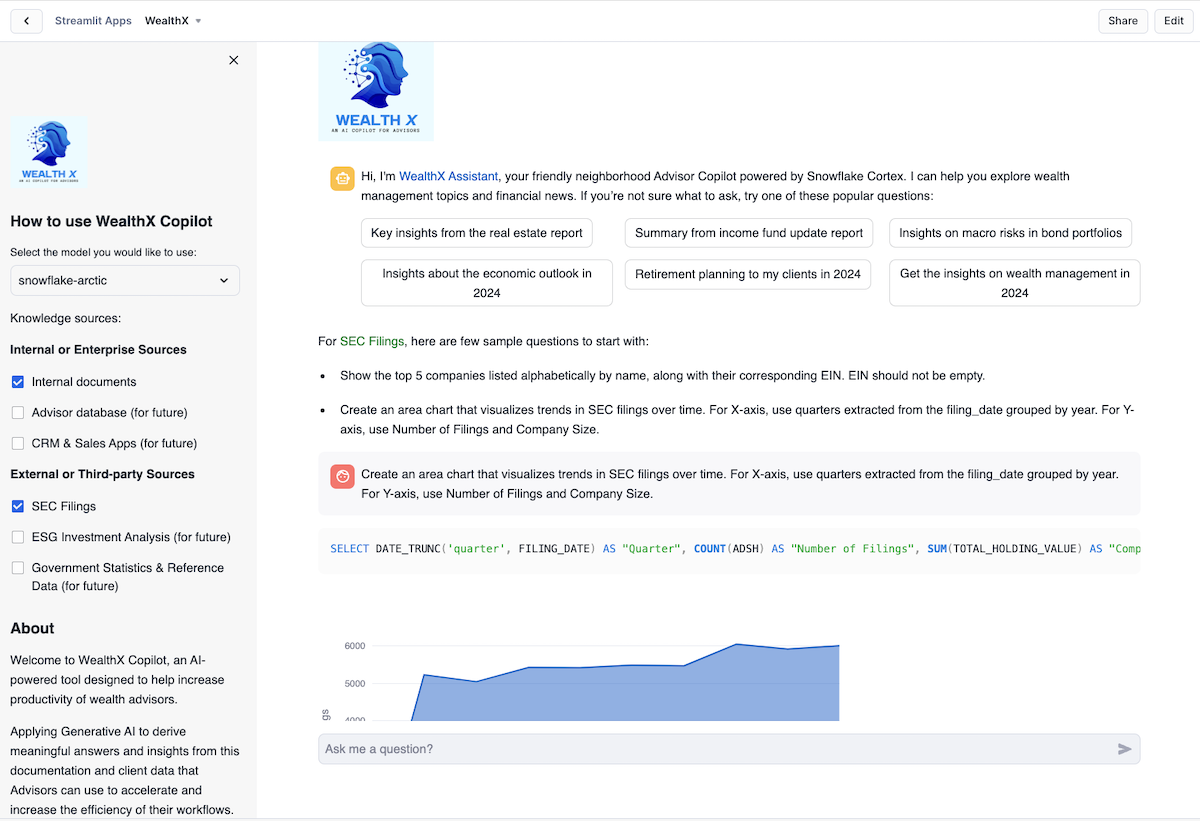
WealthX Dashboard Experience for SQL Query for SEC Filings Information and Graph Generation
-
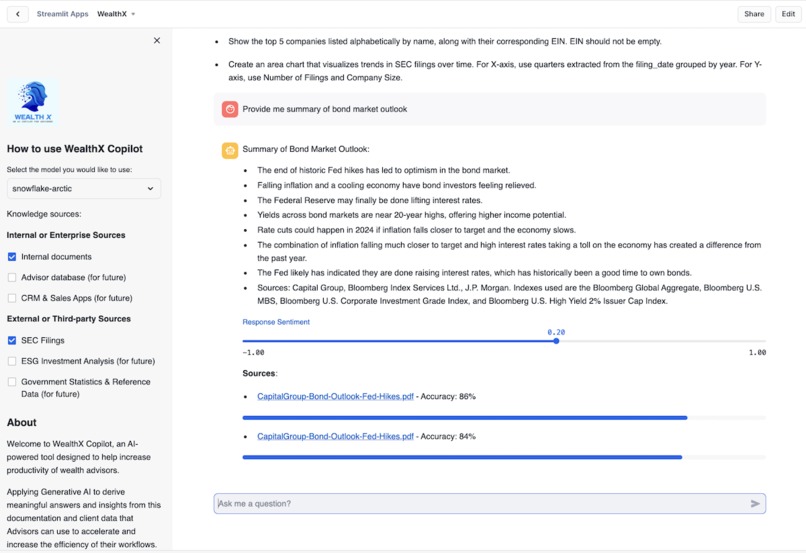
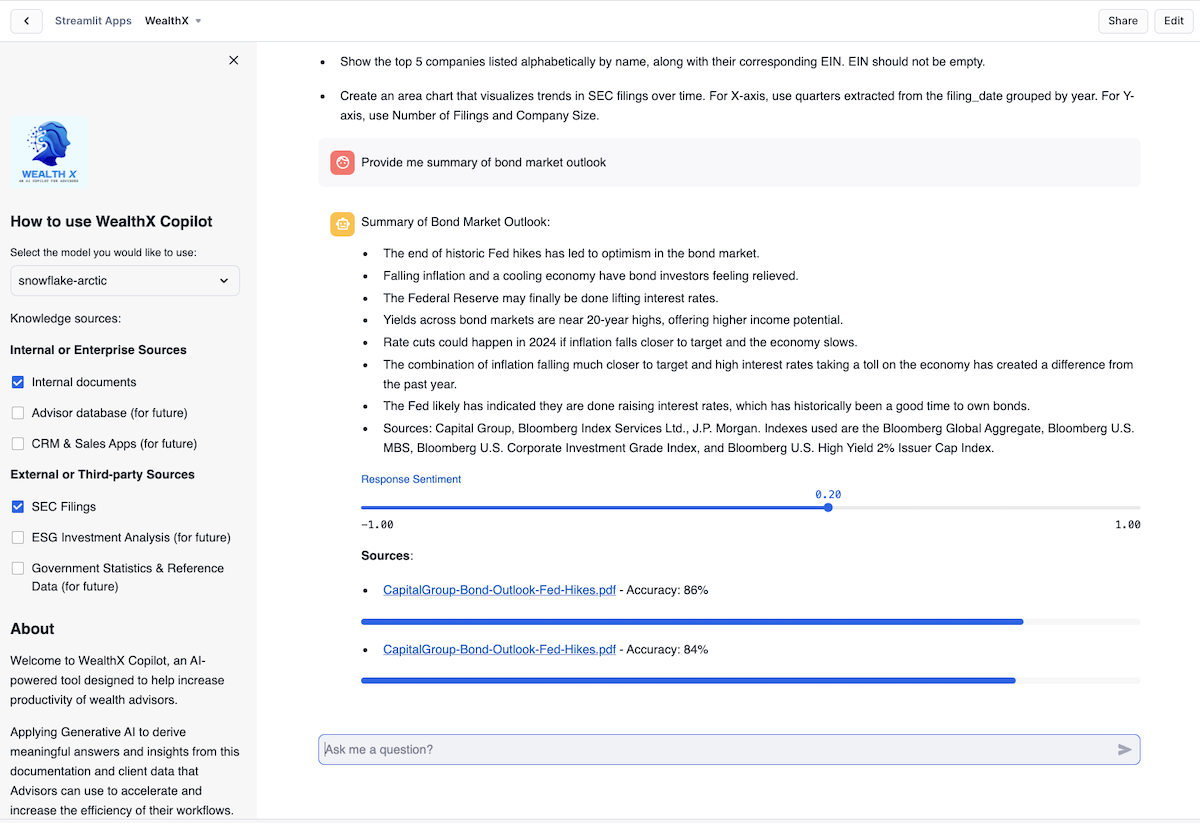
WealthX Search Experience with Sentiment and Accuracy Information
-
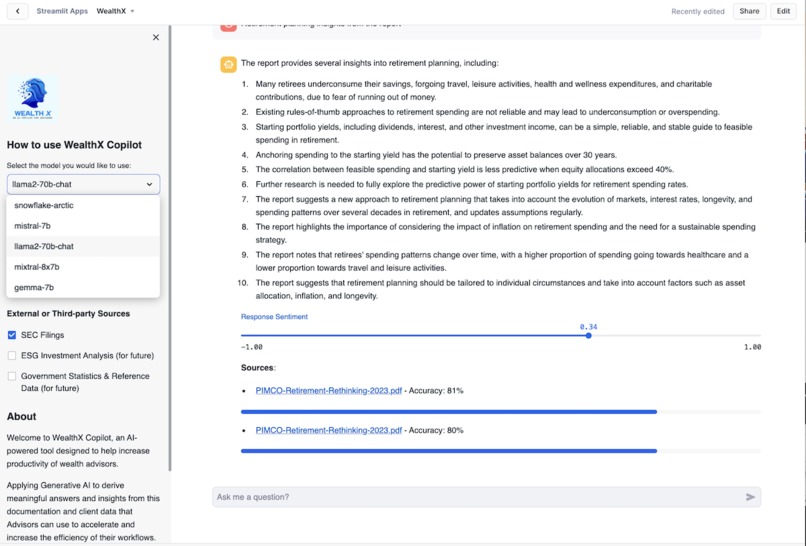
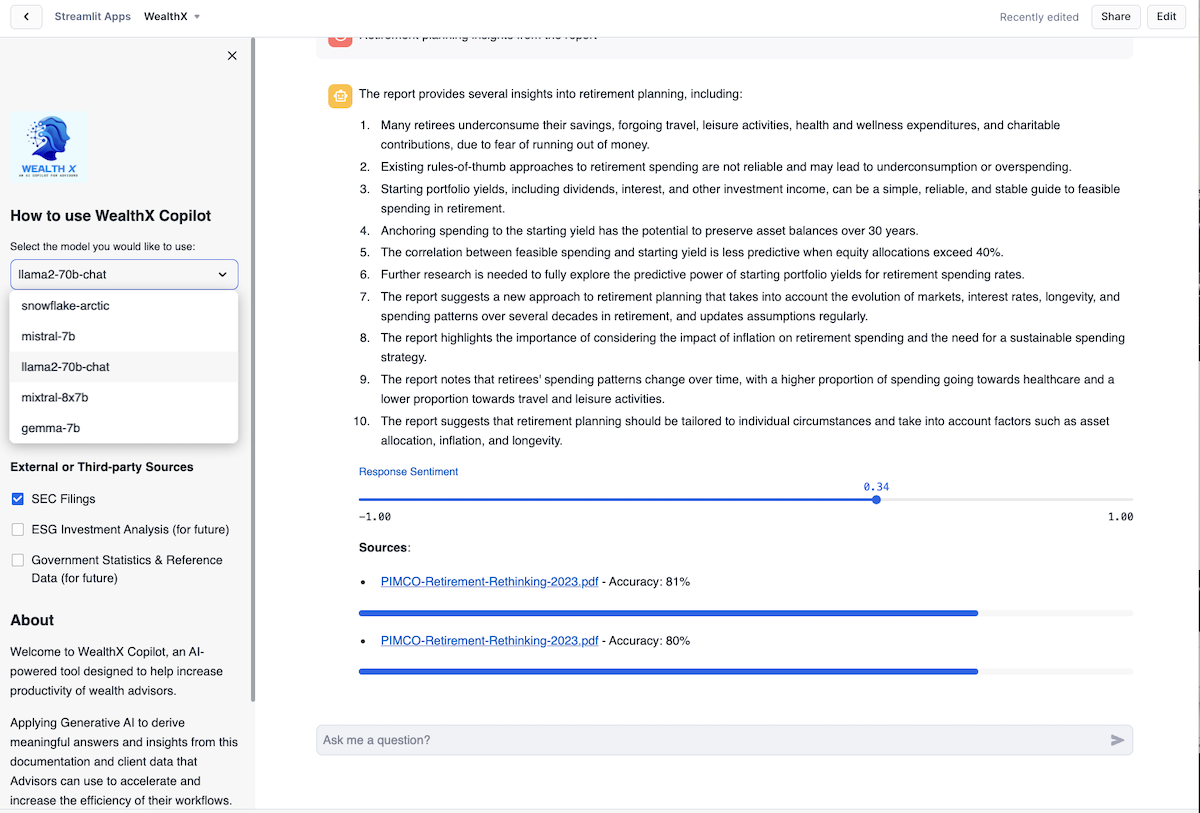
WealthX - Choose LLM Provider for Your Search
-
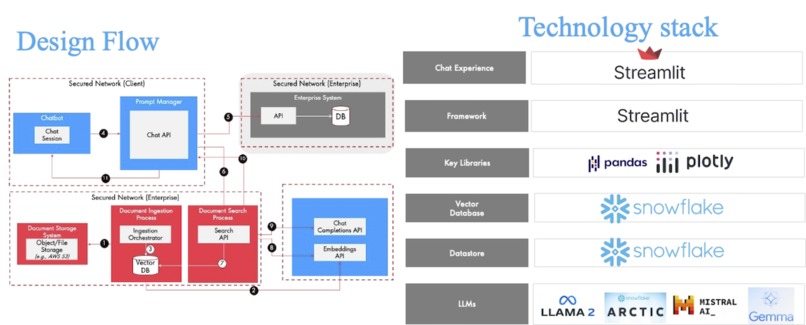
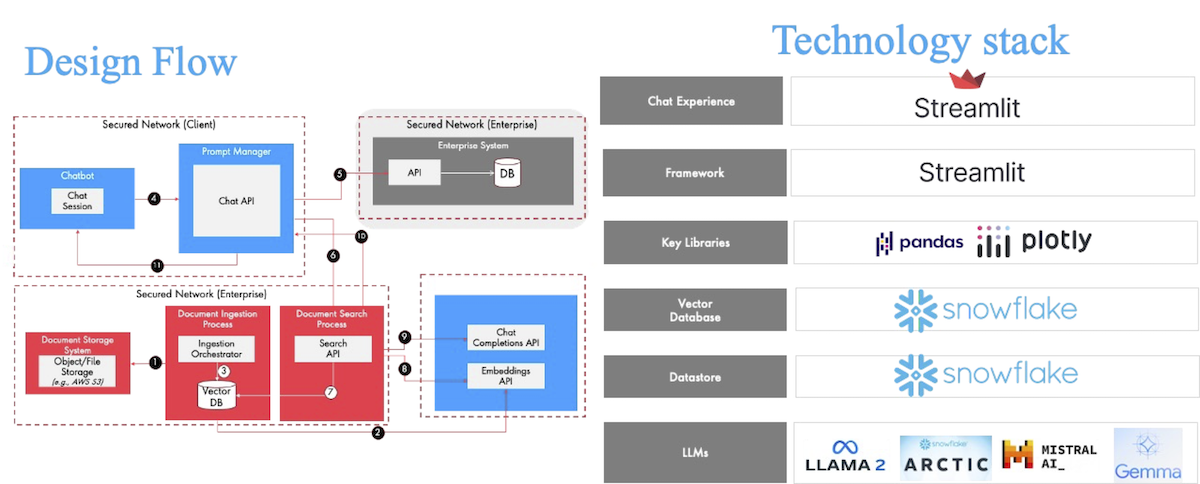
WealthX Architecture & Design Flow
Inspiration
- In Wealth Management, advisors struggle to keep up with a large number of research reports, internal documents, legal and compliance policies, disclaimers, and additional information that they have access to.
- There is no easy way to review and pull meaningful insights from the increasing source of information sources.
- Additionally, there are multiple sources of information such as SEC filings to make informed decisions about buying, selling, or holding a company's securities.
What it does
- Ability to find information quickly and provide meaningful insights to wealth advisors is what inspired building WealthX.
- WealthX provides a unified interface to access information from multiple sources and generate insights for advisors to help advisors focus on financial planning activities for their clients.
How we built it
- WealthX consolidates information from different sources such as research insights and SEC filings information available in Snowflake. Using the power of Snowflake, the platform generates embeddings from unstructured data (e.g. PDFs) and stores them in the Snowflake table for semantic search.
- Additionally, for SEC filings - it uses Cybersyn data from the Snowflake Marketplace for the Financial statements, press releases, & fiscal calendars for US public companies; fund manager holdings.
- WealthX uses Snowflake Cortex and other LLMs to generate meaningful insights from the data sources based on the advisor's query in natural language. It also uses Text-to-Sql capabilities to generate queries for the Cybersyn database to query SEC filings.
- Finally, it uses Streamlit to render the user experience, which is configurable and provides the ability to choose the LLM and indicate the currently implemented data sources for search.
Challenges we ran into
There were multiple challenges faced during the implementation:
- Initially, the PDF search was not accurate and hence Prompt Engineering techniques were applied to refine the search results. That's why the search accuracy and response sentiment are getting displayed as well to ensure minimal hallunication and transparency.
- Text-to-SQL has been another major challenge as if the SQL queries were not generated correctly, then it does not help. I applied additional technique to generate the embedding for multiple tables' schema and store it in Snowflake table.
- Furthermore, the semantic search was used to find the context to Snowflake Cortex or chosen LLM to generate the LLM.
Accomplishments that we're proud of
Initially, the whole solution became too complex as an individual contributor but finally managed to get multiple features implemented, and proud of the following accomplishments:
- single, unified conversational interface to query internal documents, research reports, and client data using natural language
- derive meaningful insights from the knowledge base for advisors to accelerate and increase the efficiency of their workflows
- using multiple SQL-based LLM functions for different purposes such as: snowflake.cortex.complete(), CORTEX.SENTIMENT, etc.
- user-intent classification to figure out what advisor is trying to figure out
- render chart from the dataframe was one of the most interesting areas, used LLM to figure out what type of chart to be displayed
What we learned
There were multiple areas of learning and entire Snowflake experience has been insightful particularly:
- How to design an LLM-powered application and challenges to handle for prompt engineering
- How to apply Snowflake Cortex to address LLM-specific requirements
- Using different types of capabilities such as sentiment analysis, completion, SQL-query generation, user intent classification, figuring out chart type based on Panda dataframe's schema, etc.
What's next for Wealth X: A Wealth Insights Generator for Financial Advisors
The journey has just started - it has given the motivation to extend the idea further to add many more capabilities wealth advisors need in their day-to-day life based on my financial services' domain experience.
- Features in pipeline: add additional datasets including advisor data, data from custodians, data from CRM systems, dynamic context based on scenarios, client segmentation, and targeted information retrieval, suggestive call-to-action, multi-agent architecture for automated review of proposal generation, etc.
- Technical features: semantic chunking, RBAC security for embeddings, multi-query and reranking of documents for increased accuracy/hallucination prevention, security guardrails for pre/post processing of LLM response, etc.


Log in or sign up for Devpost to join the conversation.