-
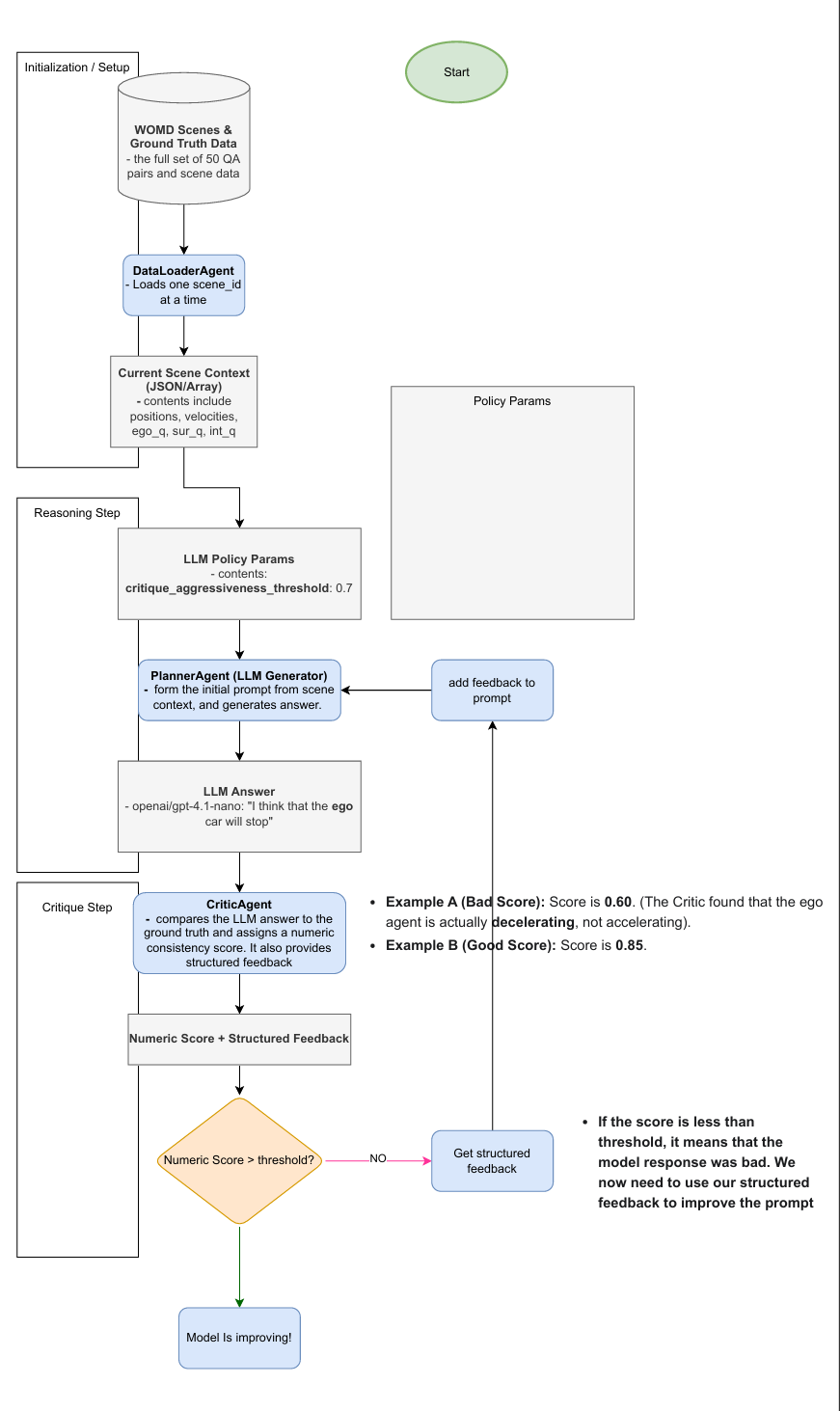
Workflow flowchart
Developed by Team WeaveWay: Dani Thi Graviet, Roddsi Sarkar, Srinethe Sharavanan, Bek
TL;DR One driving scene → one reasoning agent → one critic → full explainability. Next, those same agents start talking to each other — learning collaboratively through shared language and feedback. That’s the future of self-improving, cooperative AI systems.
Inspiration
Autonomous vehicles today operate in isolation. Each system processes sensor data, predicts motion, and executes — but there’s no shared reasoning layer or self-critique between agents. We wanted to build a foundation where autonomous agents could not only reason about their environment, but also reflect, self-evaluate, and even communicate insights to one another.
The result is Waymo-Agent, a Weave-powered reasoning pipeline that turns scene Q&A data from the Waymo Open Motion Dataset into structured reasoning loops — complete with planning, critique, and score-based self-assessment. It’s a step toward cars that don’t just act — they think out loud and get better together
What it does
Autonomous vehicles today operate in isolation. Each system processes sensor data, predicts motion, and executes — but there’s no shared reasoning layer or self-critique between agents. We wanted to build a foundation where autonomous agents could not only reason about their environment, but also reflect, self-evaluate, and even communicate insights to one another.
The result is Waymo-Agent, a Weave-powered reasoning pipeline that turns scene Q&A data from the Waymo Open Motion Dataset into structured reasoning loops — complete with planning, critique, and score-based self-assessment. It’s a step toward cars that don’t just act — they think out loud and get better together
How we built it
- Started with unstructured reasoning data from the Waymo Open Motion Dataset (WOMD).
- Defined a QARecord schema to represent symbolic knowledge from each scene (environment, ego, and neighbor states).
- Implemented MartianAgent (planner) and CriticAgent (reviewer) using the OpenAI API.
- Built a structured pipeline in Python that runs these agents sequentially, records reasoning steps, and visualizes them through Weave.
- Tested it locally via a single-record loop before scaling to full datasets.
Challenges we ran into
- Adapting the Waymo dataset from motion vectors to symbolic Q&A format.
- Keeping model outputs deterministic and schema-consistent for Weave.
- Handling long-context reasoning while maintaining structured JSON compatibility.
- Managing OpenAI rate limits during iterative experiments.
Accomplishments that we're proud of
- A fully functional reasoning-and-critique loop that runs on real Waymo data.
- End-to-end Weave visualization, letting us inspect every agent’s decision and score.
- Modular architecture: planners, critics, and data handlers can be swapped independently.
- Clear path toward adaptive and collaborative AI agents.
What we learned
- Visibility beats complexity. Many “AI bugs” aren’t algorithmic — they’re about not seeing what the model was thinking.
- Weave’s tracing made the reasoning pipeline interpretable for humans.
- Lightweight contextual feedback can mimic early self-improvement even without full RL.
- Defining strict data schemas helps language models behave like reliable subroutines.
What's next for Waymo Agent
- Adaptive prompt memory: Use critic feedback to refine planner prompts dynamically across iterations.
- Vehicle-to-Vehicle communication: Two cars exchange summarized scene context (“Crosswalk ahead — slowing down”) → parse → adjust motion → log → critique each other. This will test early cooperative reasoning between autonomous agents.
- Scale to multi-agent simulations: Use this same reasoning loop for swarms of agents in shared environments.
Log in or sign up for Devpost to join the conversation.