-
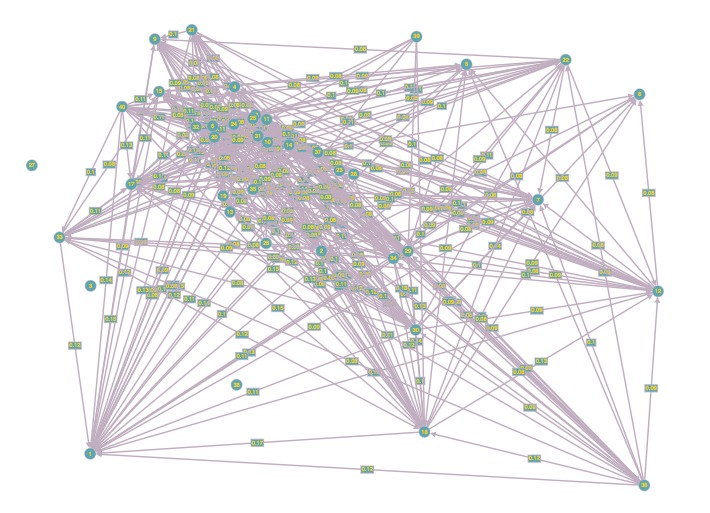
Similarity Graph with threshold
Technologies Used
- pandas
- nltk
- Feature vectorization (pseudo labelling)
- Two stage modeling
- Similarity graph
- BERT
- sklearn
- pytorch
- numpy
Challenges Faced
The transcription data presented a challenge of classifying transcriptions into 40 highly imbalanced medical specialty labels. Due to imbalanced nature of the dataset, our initial model, without addressing this issue classified all transcriptions as 'Surgery' which is the most frequent category in the dataset.
To address this issue, we applied a mapping technique that reduced the 40 categories into 8 broader categories, each of which includes 5 sub-labels with similar characteristics. Our updated approach first classifies each transcription into one of the 8 broad categories using a primary model. Then, 8 distinct secondary models are used to categorize each transcription within their respective label.
Discovering Similar Characteristics - Similarity Graph, Pseudo Labelling
To ensure code run-ability, we randomly selected around 3 to 35 transcriptions from each label. Using cosine-similarity, we computed the degree of similarity between each transcription, with a score of 1 indicating perfect similarity. Afterwards, we calculated the mean similarity between each label by creating a 2-dimensional adjacency matrix where each value represented the mean similarity between two labels. Using this matrix, we generated a graph where each node represents a label, and the weight of each edge represents the mean similarity between the two connected labels. We then selected 5 labels from the graph with the highest summation of similarities within a 5-sub-graph and removing those nodes. This process was repeated until all the 40 labels were assigned to one of the 8 broader categories, each of which contains 5 sub-labels.
Overall Outcomes
We realized there was a great impact of data bias while training the model so we proposed a solution that could potentially address the issue. Our model may not be able to classify transcriptions on a medical specialty level accurately but it can classify on a department(broader) level.


Log in or sign up for Devpost to join the conversation.