
Inspiration
We are two aspiring entrepreneurs who want to positively change the world by providing resources to disadvantaged communities in third-world countries. We want to leverage artificial intelligence, especially deep learning and machine learning, to increase social equity in the world. We plan to do this by creating data-driven tools to solve real-world problems and provide resources to those around the world who need them most. We decided to create a water classification system after researching real-world problems and discovering the lack of inexpensive, accurate resources to classify water as drinkable or non-drinkable.
What it does
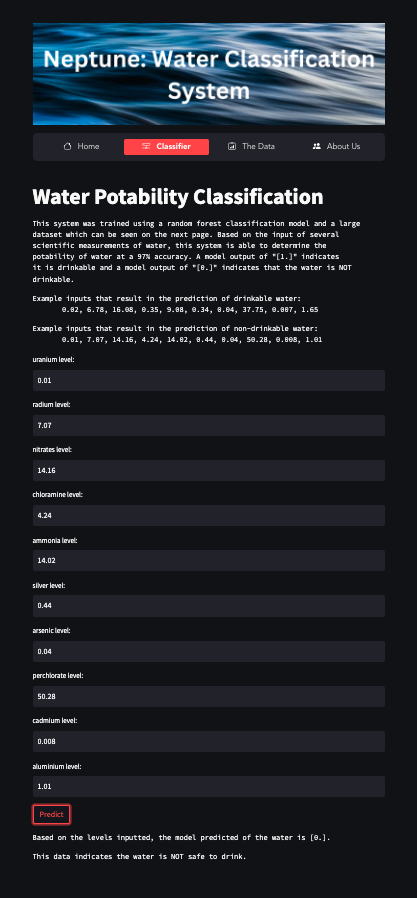
Neptune classifies a water source as potable or non-potable based on scientific measurements such as the aluminum level and ammonia level of a water sample. Anyone with an internet connection and the data can use our system (97% accuracy). If the system returns “[0.]” then the water is predicted to be drinkable and if it returns “[1.]” then the water is predicted to be non-drinkable. Paired with hardware that can measure the levels of elements in water sources, this system can have major impacts on communities in third-world countries that suffer from dirty water sources and lack of drinkable water sources.
How we built it
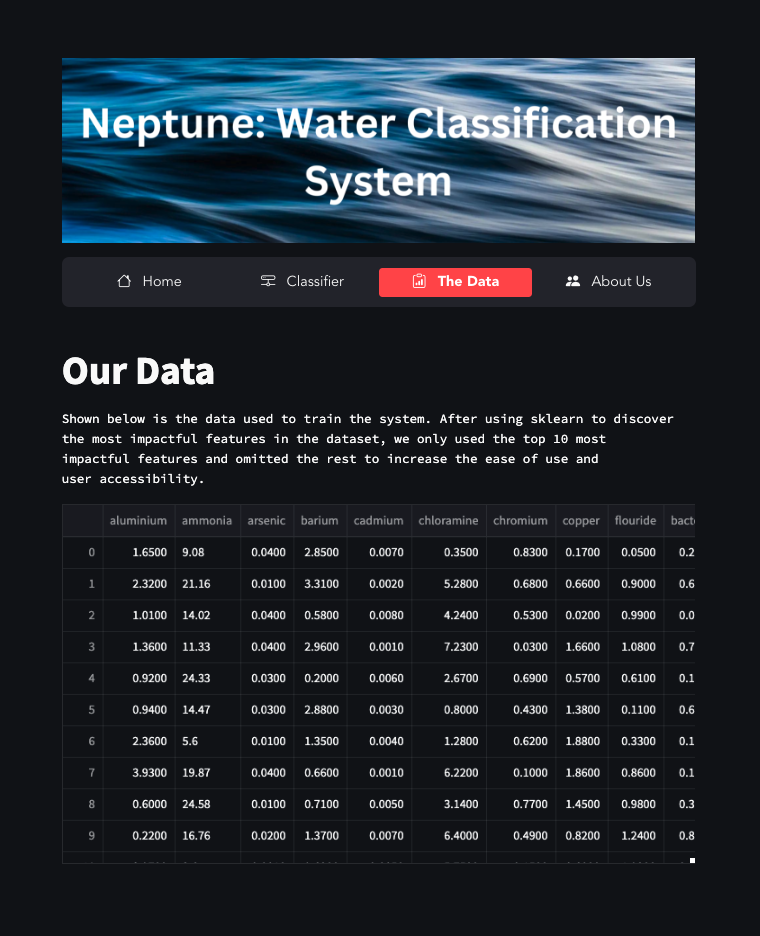
We built the backend of Neptune in Google Colaboratory using a random forest classifier model from Sklearn and a water quality dataset with about 8000 entries. We also used Matplotlib, Numpy, and Pandas for developing the backend of our project. For frontend development, we used Streamlit and Pickle in Visual Studio Code to create our web application. We used Streamlit Cloud, Git, and Github for website deployment.
Challenges we ran into
We ran into challenges with getting our accuracy to 97%. When we first trained a model, the model was only 65% accurate. We also had challenges with data processing at first, but soon learned how to remove empty values from a dataset and change the value type of columns in the dataset. We also faced challenges in designing the user interface of the website. The biggest challenge was deploying the application, as we have never done this before until now.
Accomplishments that we're proud of
We are proud of the classifier’s 97% accuracy, detecting the importance of the features in the dataset, our data processing, the input function we created, linking the machine learning model to our website, and our front-end development. This was our first time using Streamlit so we are proud that we were able to create a useful, well-designed web application that genuinely has the chance to make an impact on the world. We are most proud of the user accessibility of Neptune and deploying the website, as it was very hard and it was our first time ever doing it.
What we learned
We learned how to detect the importance of features in a dataset in order to limit the number of features used in our app to increase user accessibility. Additionally, we learned how to drop empty values in a dataset, change the value type of dataset columns, and pickle a Python machine-learning model. We also learned how to create a multi-page website in Python and Visual Studio Code using Streamlit and how to deploy a website online using Streamlit Cloud.
What's next for Neptune: Water Classification System
We designed our project with the intent of easy accessibility for anyone who needs it. What’s next for our classifier is to continue researching this issue and optimizing this application. We can potentially partner with non-profit organizations to research this issue even more and maybe work with them to distribute resources and apply this system in disadvantaged areas.
Built With
- git
- github
- google-colaboratory
- matplotlib
- numpy
- pandas
- pickle
- sklearn
- streamlit
- visual-studio

Log in or sign up for Devpost to join the conversation.