-
-
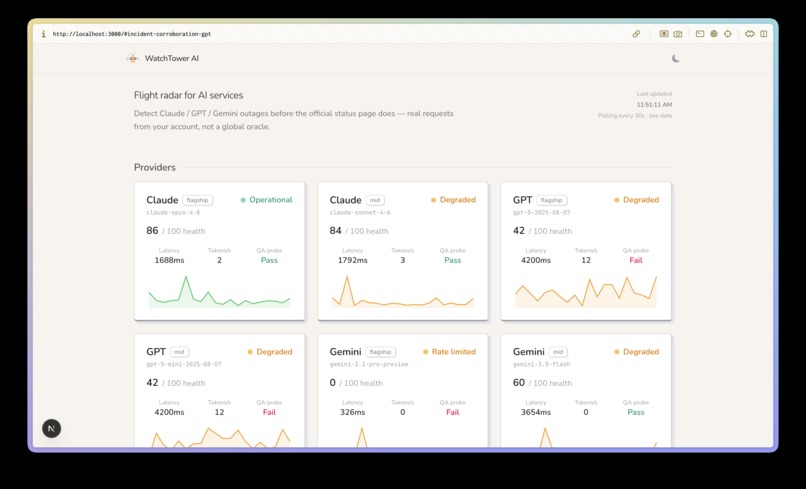
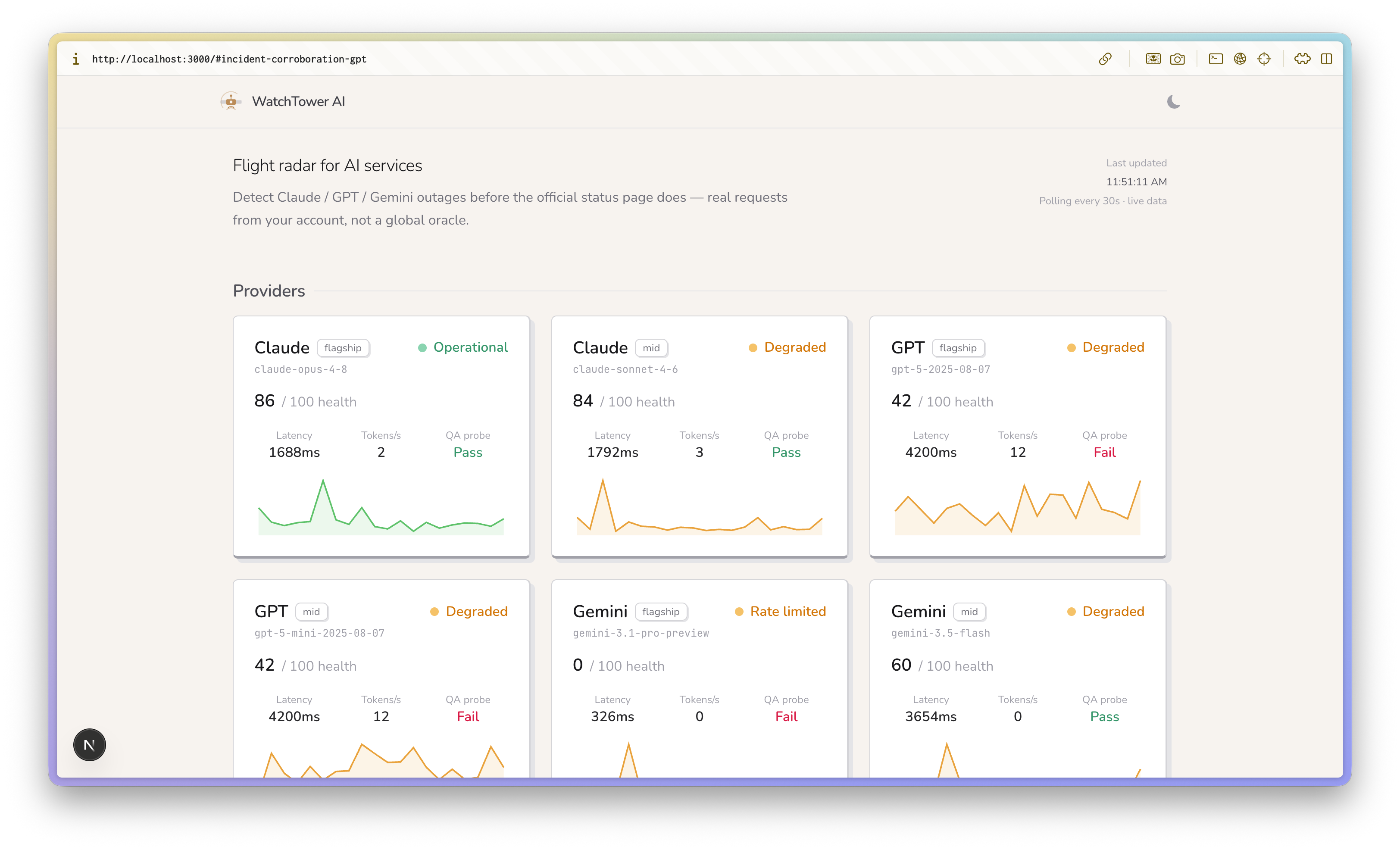
Live status for your own model accesses
-
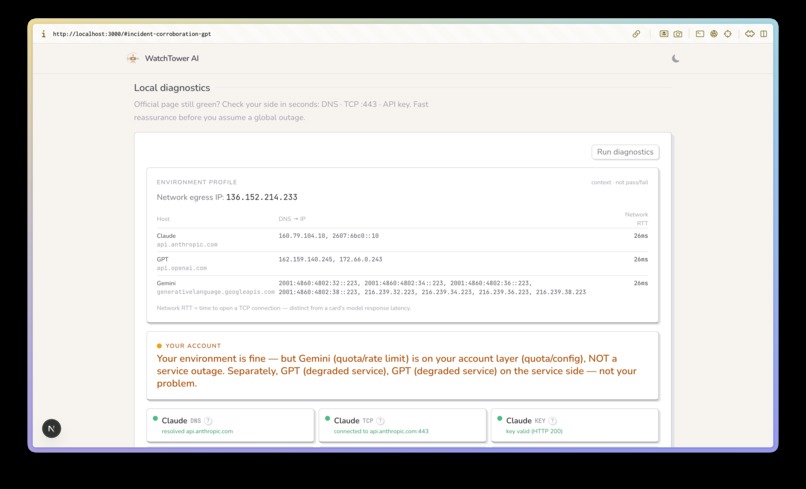
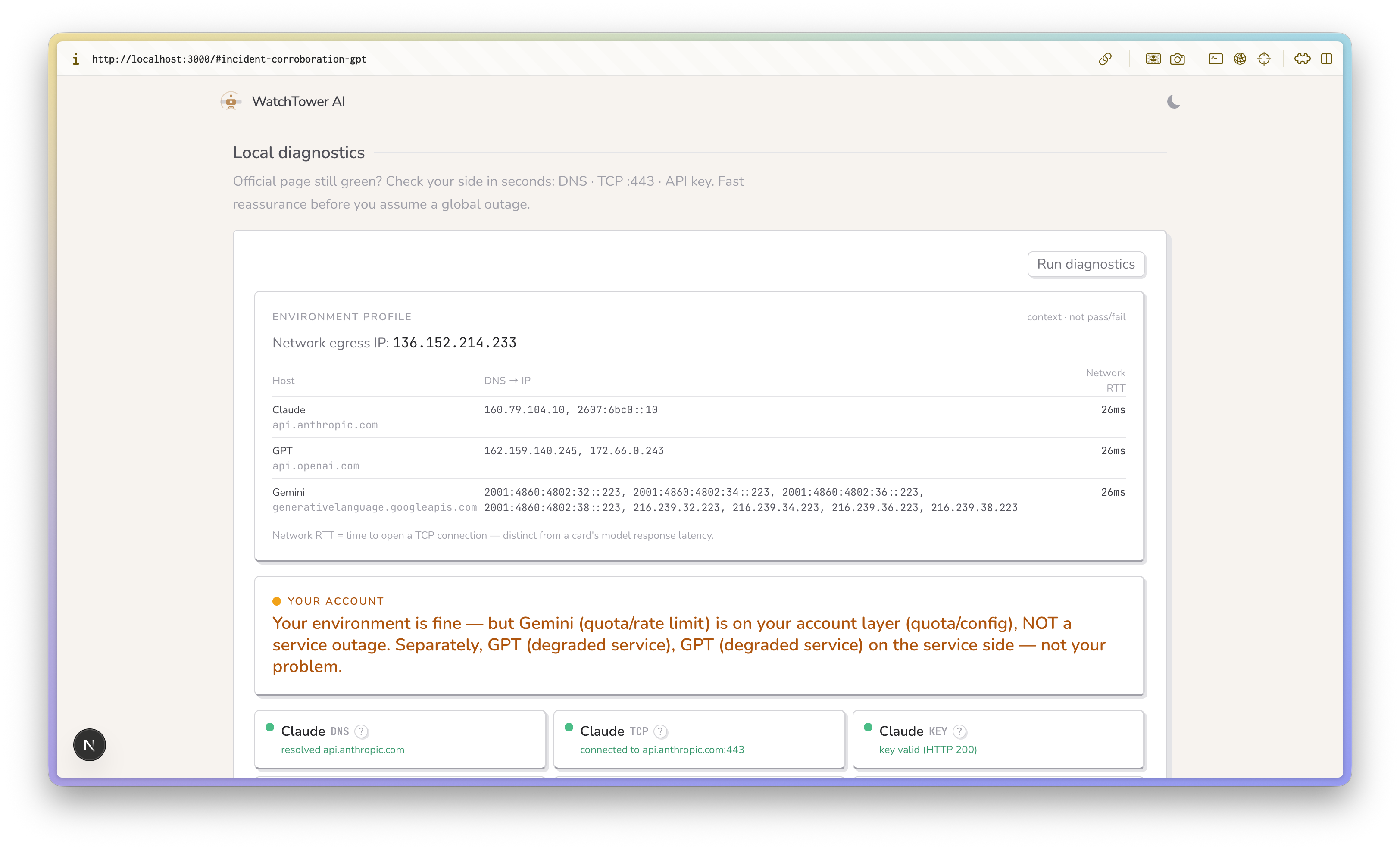
Local diagnostics for checking your environment
-
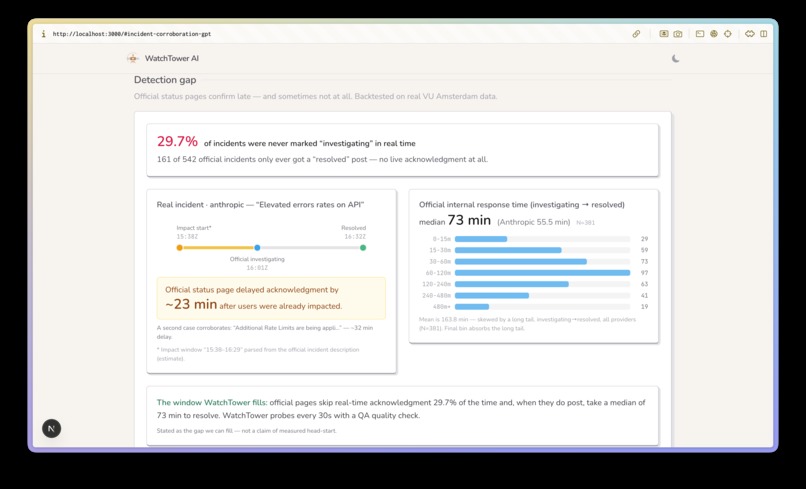
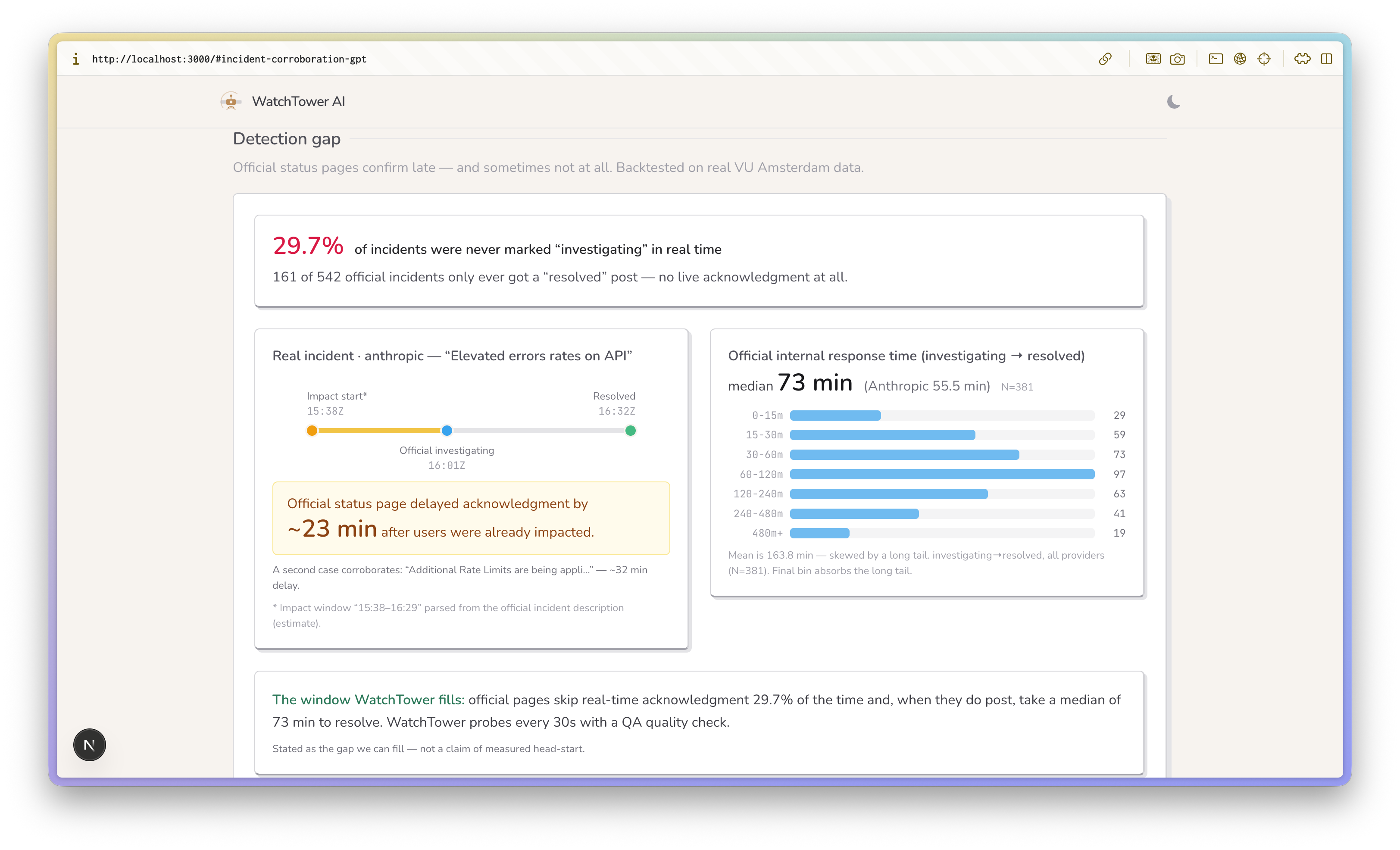
Backed up by real research about the pain point
-
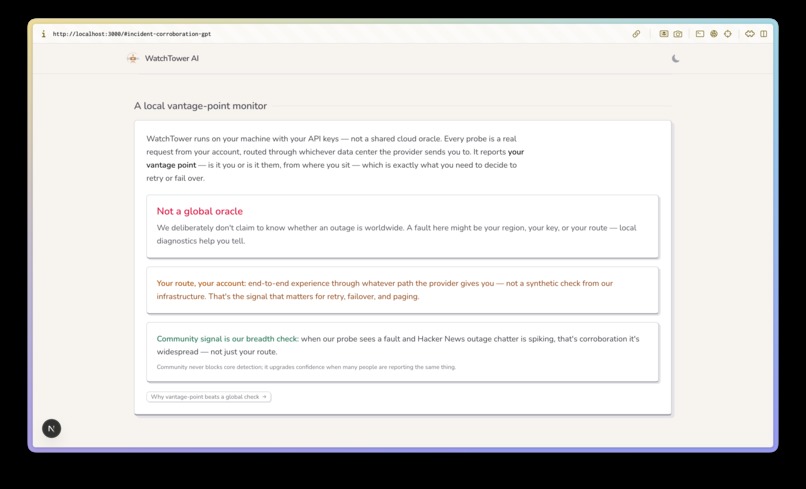
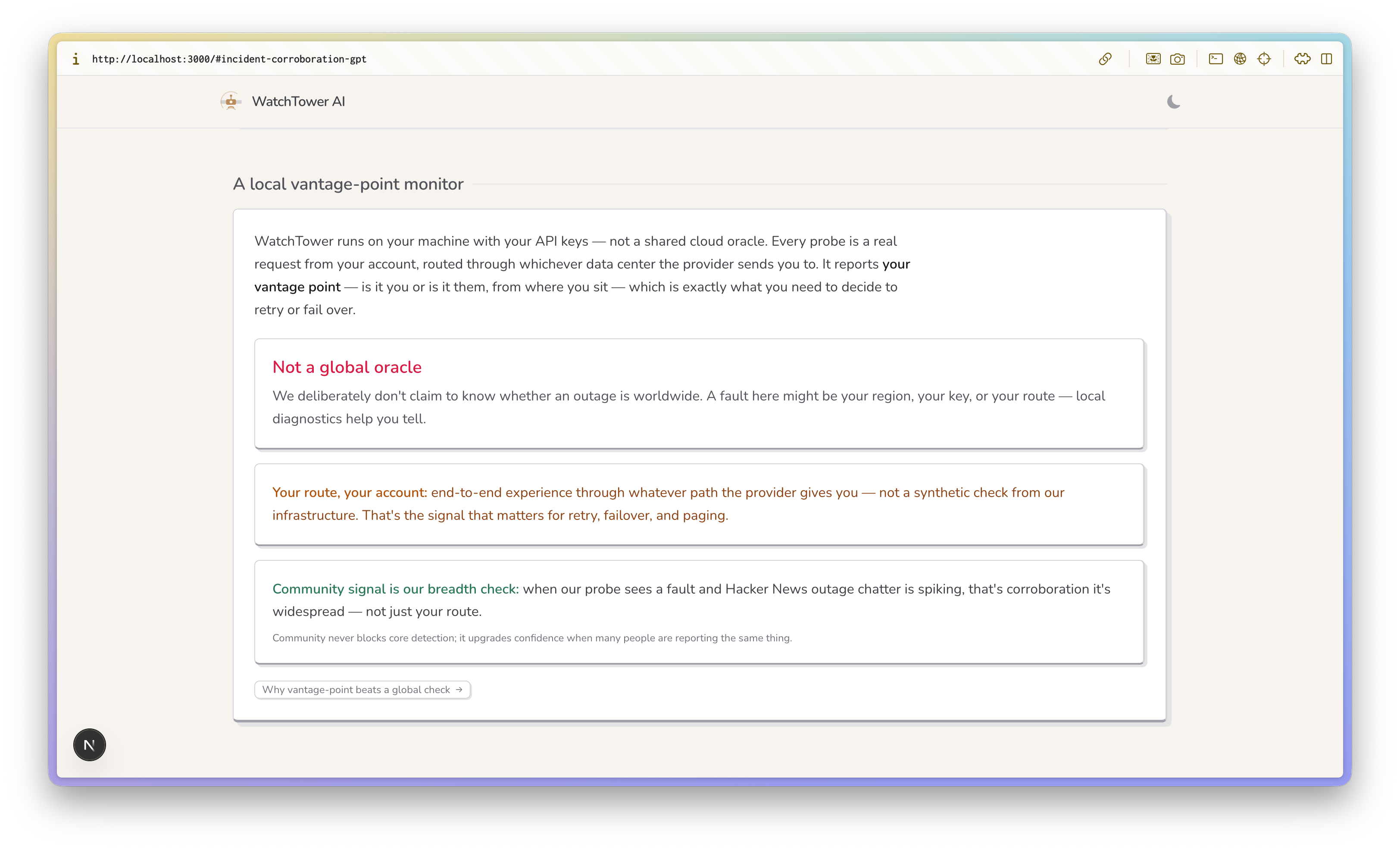
It runs locally -- your keys, your machine
Inspiration
It was past midnight, and a Claude API call had just failed. I did what every developer does at that hour — I assumed it was me. I checked my code. I checked my network. I regenerated my API key. I re-read my own request three times.
Then I opened the official status page — green, "all systems operational" — while my requests kept failing. I'd lost twenty minutes to a problem that was never mine. The provider was degraded; the status page just hadn't admitted it yet.
That gap — the stretch where a service is already down but nothing official says so, and you're left debugging perfectly fine code — is the entire reason Watchtower AI exists. I wanted a tool that collapses those twenty minutes into a few seconds and answers the only question that matters at midnight: is it down, or is it me — and if it's down, whose fault is it, really?
This was my first hackathon, done solo, in 24 hours.
What it does
Watchtower AI is a local "flight radar" for AI services. It runs on your machine, with your keys, and answers two questions:
- Is the provider okay right now? It fires concurrent probes at Claude, GPT, and Gemini every 30 seconds — and it doesn't just ping. It sends a real QA prompt and grades the answer, measures tokens-per-second, and tracks flagship and mid tiers separately, auto-selecting valid models so it never 404s on a renamed endpoint.
- If something's wrong, whose problem is it? A four-way attribution engine sorts every failure into your environment / your account / the provider / all-clear, and recommends a concrete fallback (e.g. route to Claude mid).
When a provider degrades, Watchtower corroborates with live community signal and official status feeds, then states — honestly — how confident it can be from where you sit.
How we built it
The probe engine is a FastAPI + asyncio backend that runs concurrent health checks with httpx. Results persist to SQLite, so the trend sparklines survive a restart instead of resetting to zero — a small detail, but it's the difference between a toy and a tool you'd actually leave running.
The attribution layer turns raw probe results into a verdict. Local diagnostics (DNS, TCP :443, API-key check) rule out your side in seconds; if every model on your account is impaired, it's likely the provider — but Watchtower deliberately frames this as "provider-wide from your vantage point," not as global truth (more on that below).
Community corroboration went through a complete redesign mid-hackathon. We pull live Hacker News chatter through the Algolia Search API (free, no auth, works behind campus firewalls) and parse each provider's official status-page JSON. The most interesting source is Downdetector: it has no public API and hides behind Cloudflare, so we drive a real browser session through Browserbase (Playwright over CDP), auto-clear the Cloudflare challenge, wait for content, and scrape the headline and user comments. Then Claude Haiku reads the actual comments and returns a structured {problems_found, summary, comments[]}, which feeds back into spike detection. The payoff: Downdetector's own headline said "no current problems," but our LLM read the comments and surfaced connection failures and safety-routing degradation — more honest than the crowd-sourced top line.
The research backbone is a backtest against the VU Amsterdam dataset from the ICPE 2025 paper An Empirical Characterization of Outages and Incidents in Public Services for LLMs (Chu et al.). On 542 real incidents, 29.7% (161) were never marked "investigating" in real time — they only ever got a "resolved" post. Median time from investigating to resolved was 73 minutes (Anthropic: 55.5, N=381). That's the documented blind window Watchtower is built to fill.
The observability layer is Sentry, three layers deep — structured events, fingerprinting that groups every probe cycle, and performance traces. Then we closed the loop: we let Sentry's Seer agent do root-cause analysis on a real TypeError in our own backend and open a pull request to fix it. A tool that monitors AI, monitored and repaired by AI.
The build pipeline leaned on agents at every stage. The initial probe engine and the early large-scale rewrites were built with Claude Code, with Sentry wired in alongside development for live observability from day one. Cursor handled later code generation. Simular's Sai drove a hands-off UI/UX redesign pass, and Devin (Cognition) ran whole-project syntax and security/vulnerability sweeps with up to five cloud agents in parallel. Frontend is Next.js + Tailwind; everything ships via Docker / docker-compose, running locally on your keys.
How we used each tool
We didn't bolt these on for the prizes — each tool does real work in the product or the build, which is exactly why we leaned into the sponsor tracks. Here's the honest, tool-by-tool breakdown:
- Claude (Best Use of Claude) — In-product, Claude Haiku reads the raw user comments we scrape from Downdetector and returns structured
{problems_found, summary, comments[]}, which feeds straight into spike detection. That's the engine behind our sharpest line: Downdetector's headline says "no current problems," but the comments say image generation is down. Under the hood, Claude Code built the initial probe engine and the early rewrites. And across the whole 24 hours, Claude was the architecture-and-judgment partner — including talking me out of over-claiming on the research narrative. - Sentry (Best Use of Sentry API) — Three layers in production: structured events, fingerprinting that groups every probe cycle, and performance traces — wired in alongside development from day one. Then Seer closed the loop, root-causing a real
TypeErrorin our backend and opening a PR to fix it. A monitoring tool for AI, itself monitored and repaired by AI. - Browserbase (Best Use of Browserbase) — Downdetector has no public API and sits behind Cloudflare. We run a real remote browser (Playwright over CDP) that auto-clears the challenge and pulls live user reports — 100+ sessions over the build. Browserbase's exact promise (give agents the web that has no API), used for a genuine need rather than a staged demo.
- Simular (Sai) (Best Use of Simular) — We used Sai, Simular's autonomous computer-use agent, to drive a hands-off UI/UX redesign — clicking through every screen and reshaping layout and copy. An AI redesigning the interface of an AI-monitoring tool.
- Cognition (Devin) (Best Use of Cognition) — Devin ran whole-project syntax and security/vulnerability sweeps with up to five cloud agents in parallel, catching issues across the codebase far faster than one solo builder could under a 24-hour clock.
- Claude Code & Cursor — The initial probe engine and the early big rewrites were built with Claude Code; Cursor handled later code generation.
Tracks we're aiming for
- Ddoski's Toolbox (Grand Prize) — Watchtower is a developer utility in the purest sense: a local tool that erases the 20 minutes of "is it me?" at midnight. Useful, usable, and actually running — not just an idea.
- Best UI/UX — A clean provider dashboard with live sparklines, a plain-language "whose problem?" verdict, and an honesty-first design voice ("not a global oracle"), refined through the Sai-driven redesign.
- Best Solo Hack & Best Beginner Hack — Built solo, in 24 hours, as my first hackathon — where the judgment to cut 16 of 41 directions mattered more than any single feature.
Challenges we ran into
Reddit collapsed on us. Community signal was originally Reddit-based. Mid-build we hit Reddit's 2025 Responsible Builder Policy, which now requires pre-approval for all app access and explicitly bans scraping — impossible on a hackathon timeline. We killed it and revived Hacker News as the live source instead. Conditions changed; the judgment changed with them.
Cloudflare vs. Downdetector. A plain fetch can't run JS or pass an interactive challenge. That's exactly why Browserbase fit — a real remote browser session clears the challenge, and we wait on actual content rather than a fixed sleep.
A git crisis at hour ~20. Parallel AI-assisted branches, cherry-pick failures, and a broken SQLite wiring chain left main in pieces. Untangling it cost real time and taught me to stop running parallel code-gen on overlapping files.
The hardest discipline was honesty, not code. The premise of a status-monitoring tool is "we catch what they miss" — and it's tempting to dress that up. We didn't. We pulled a spurious +1,140-minute case out of the backtest the moment it looked too good. We labeled every estimated value as an estimate. When the temptation came to borrow the paper's claim that outages are periodic and predictable, I cut it — our early-warning is real-time latency-trend extrapolation, not historical-cycle prediction, and conflating the two would have been dishonest. We state the detection gap as "the window we can fill," never as a measured head-start we never instrumented. For the demo, the GPT outage is triggered by a DEMO_FORCE_DOWN flag (disclosed on screen) — but the Downdetector and Hacker News corroboration around it is real.
What we learned
The thing I'm proudest of isn't how much I built — it's how much I cut. I proposed roughly 41 directions and shipped about 22, deliberately killing 16 (SLA loss tracking, a crowdsource button, public signal service, ML classifier, periodicity prediction…) because they either fought the local-tool positioning, couldn't be done honestly in the time, or just weren't worth it. The fastest way to die in a solo hackathon is to want everything and finish nothing at half quality. Saying no, correctly and repeatedly, turned out to be the most valuable skill of the whole 24 hours.
I also learned that honesty is a feature, not a constraint. A monitor that's candid about its own blind spots ("not a global oracle") is more trustworthy than one that pretends to omniscience — and that candor is the differentiator, not a liability.
And I learned to build with a swarm of agents without letting them trip over each other — Claude Code and Cursor writing code, Devin's five cloud agents sweeping for bugs, Sai redesigning the UI, Seer fixing what broke. The hour-20 git crisis taught me the hard way that parallel agents on overlapping files collide; the fix was clearer boundaries, not fewer agents.
What's next
- Multi-vantage probing (multiple regions/keys) to move from "your route" toward genuine breadth.
- A real classifier on the VU dataset to put calibrated confidence behind anomaly calls.
- Optional, privacy-preserving aggregation so users can opt in to a shared signal without giving up the local-first model.
Built with
Next.js · Tailwind · FastAPI · asyncio · httpx · SQLite · Playwright · Browserbase · Sentry · Sentry Seer · Claude (Haiku) · Hacker News Algolia API · VU Amsterdam / ICPE 2025 dataset · Docker · Claude Code · Cursor · Devin (Cognition) · Simular Sai
Built With
- browserbase
- claude
- cursor
- docker
- fastapi
- next.js
- python
- react
- sai
- sentry
- sqlite
- tailwind-css
- typescript

Log in or sign up for Devpost to join the conversation.