-
-

-

-

-

-

-

-
-

-
-

-
-

-

Technical Memo










Inspiration
Modern surveillance systems share one goal: detect and respond to threats before they escalate. Yet, today’s solutions split into two fundamentally flawed approaches.
First, AI-driven surveillance offers speed and scale. Major cities have invested $25 billion into automated systems, but these models are inherently brittle. Relying on static, biased datasets and limited camera perspectives, they frequently misclassify behavior, fail to generalize, and erode public trust.
Second, traditional security teams provide the context and intuition that AI lacks. However, they are fundamentally constrained by scale. Human investigations are manual, slow, and fragmented across parallel camera feeds, resulting in missed or delayed critical signals.
The industry is stuck in a tradeoff: speed without understanding, or understanding without speed.
We built Siqur to eliminate this tradeoff.
Siqur introduces a Digital Twin layer that reconstructs environments in 3D. By generating synthetic scenarios, we train models across diverse conditions, perspectives, and populations. This enables the system to learn from the exact viewpoint of every camera, entirely bypassing biased historical data.
By grounding AI in spatial-temporal context, Siqur turns fragmented feeds into a unified engine that interprets, explains, and acts in real time.
The result: Fast, context-aware AI without the blind spots of existing approaches.
What it does
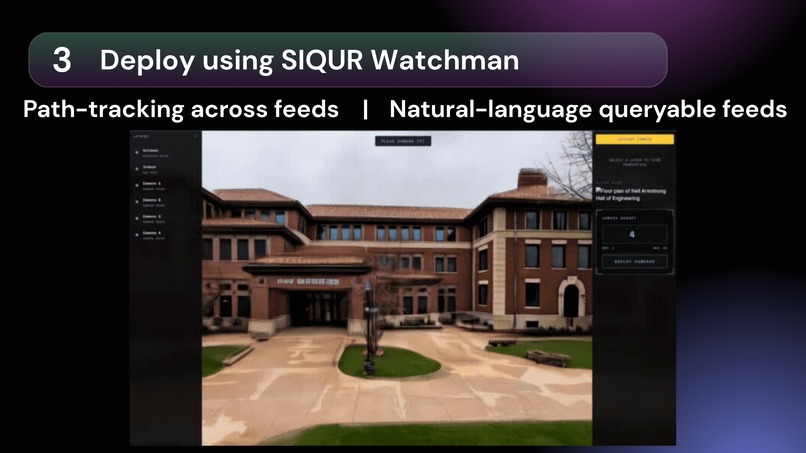
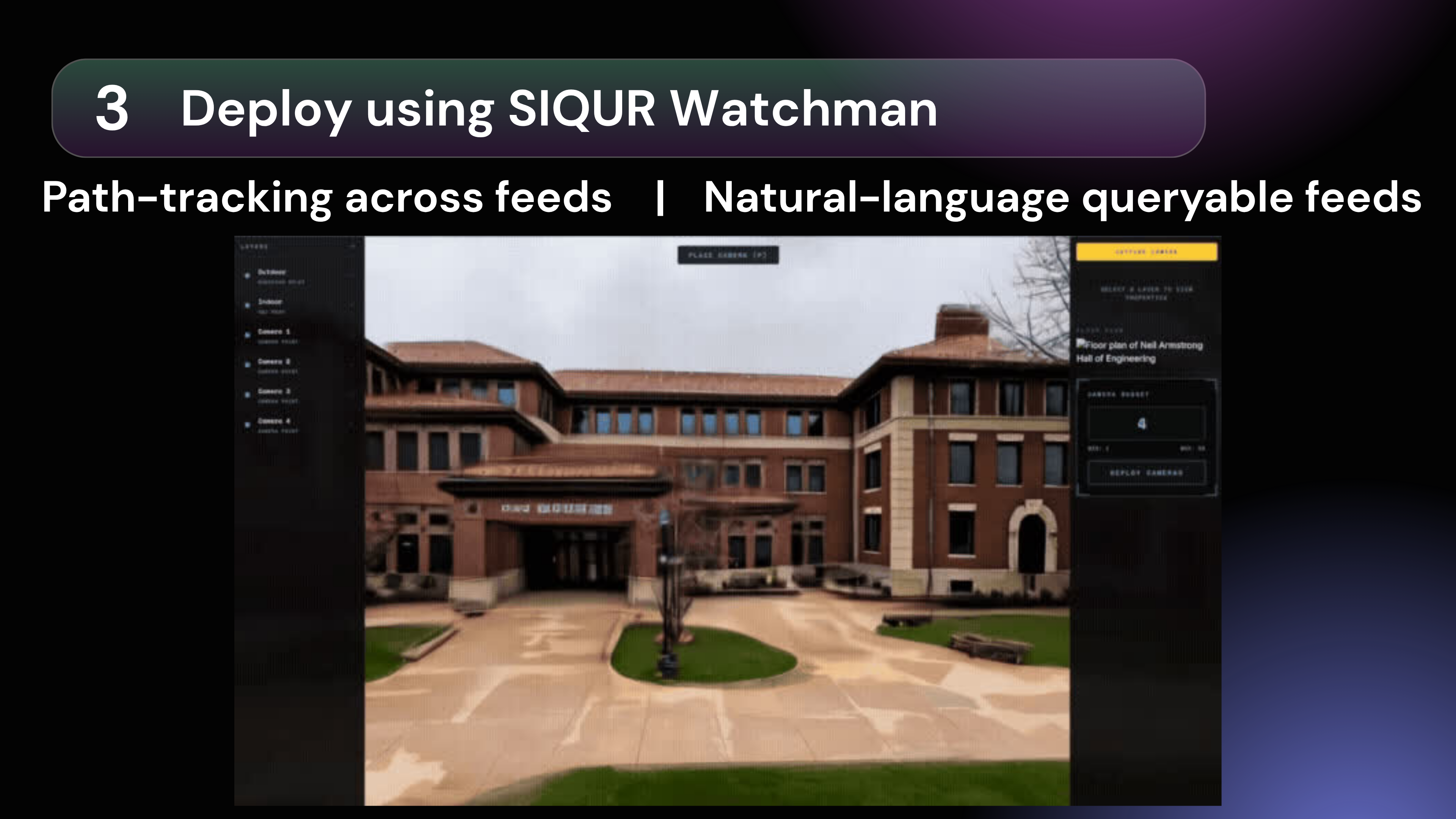
Our person path tracking tool: Watchman Watchman, transforms fragmented security infrastructure into a unified, proactive intelligence engine, replacing manual monitoring and biased automation with a streamlined pipeline: Reconstruct, Simulate, and Deploy.
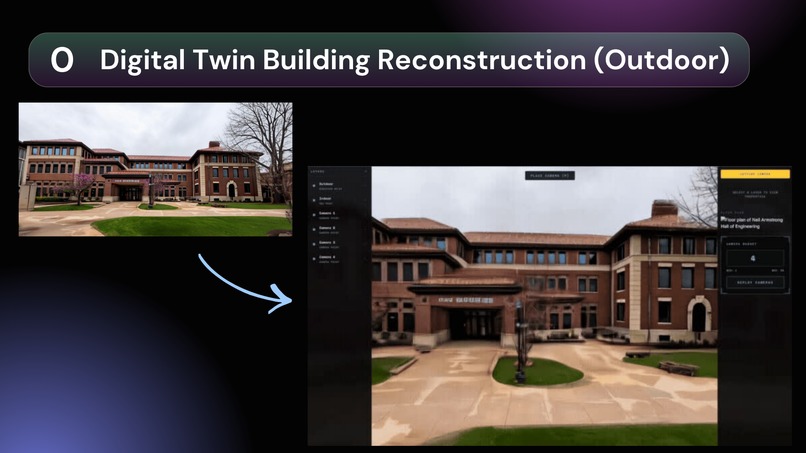
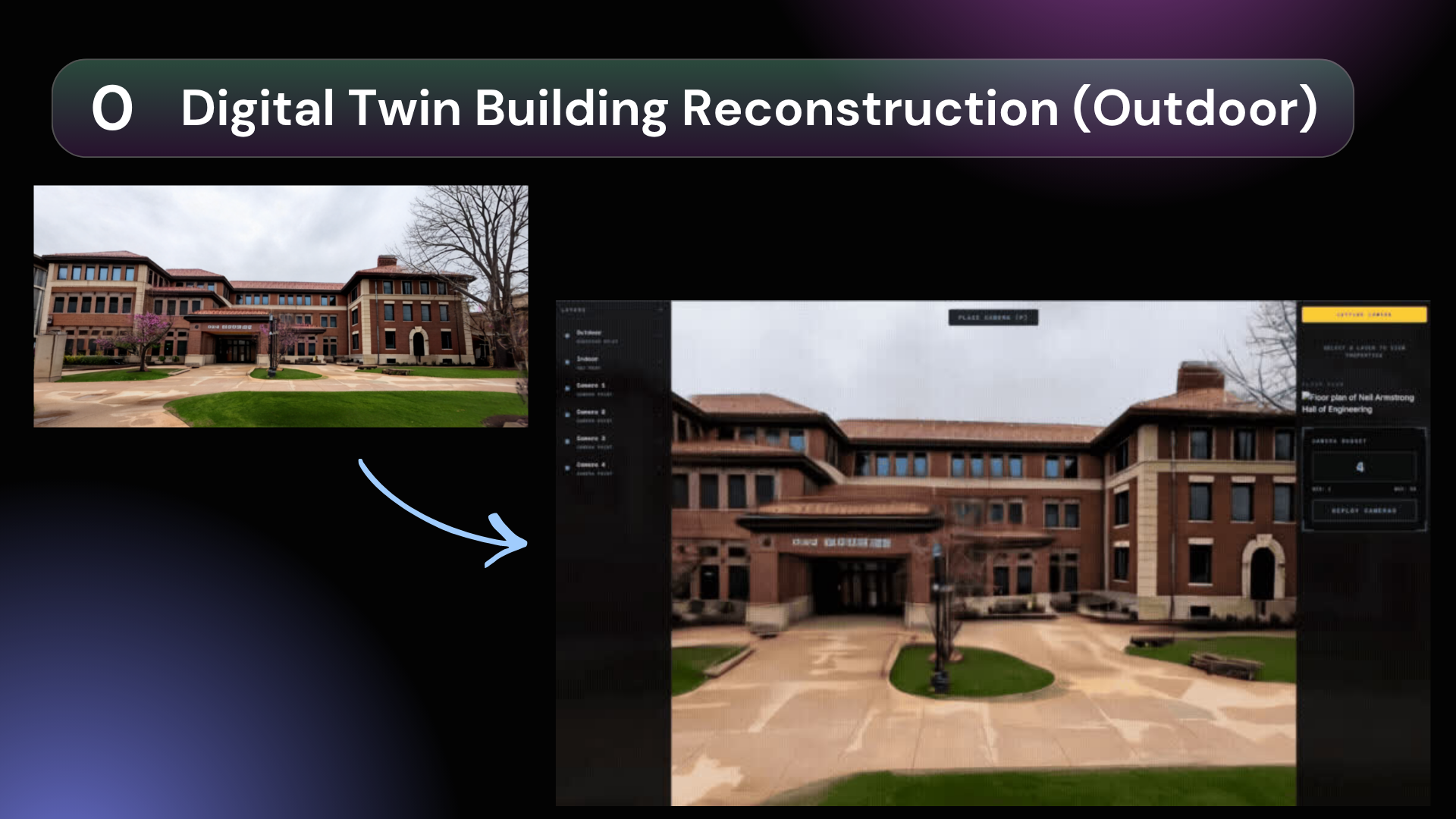
Instant Digital Twin Generation We digitize your environment instantly. Our world model engine pulls Google Maps data to reconstruct building exteriors into 500,000 gaussian splats. For interiors, users generate high-fidelity 3D environments in minutes using LiDAR scans.
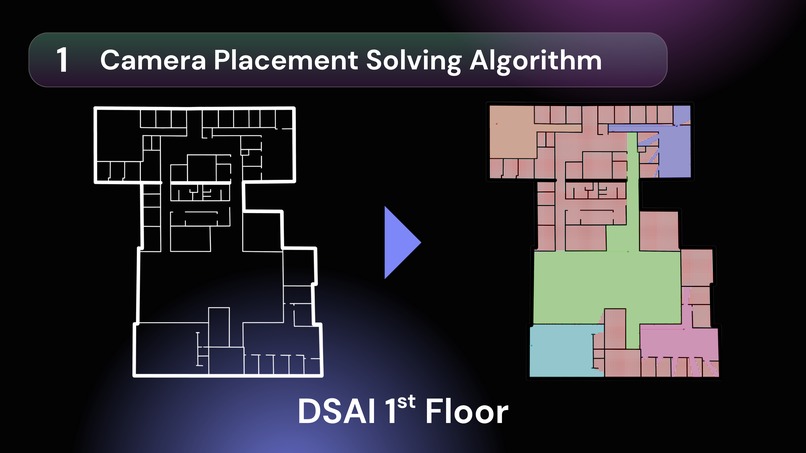
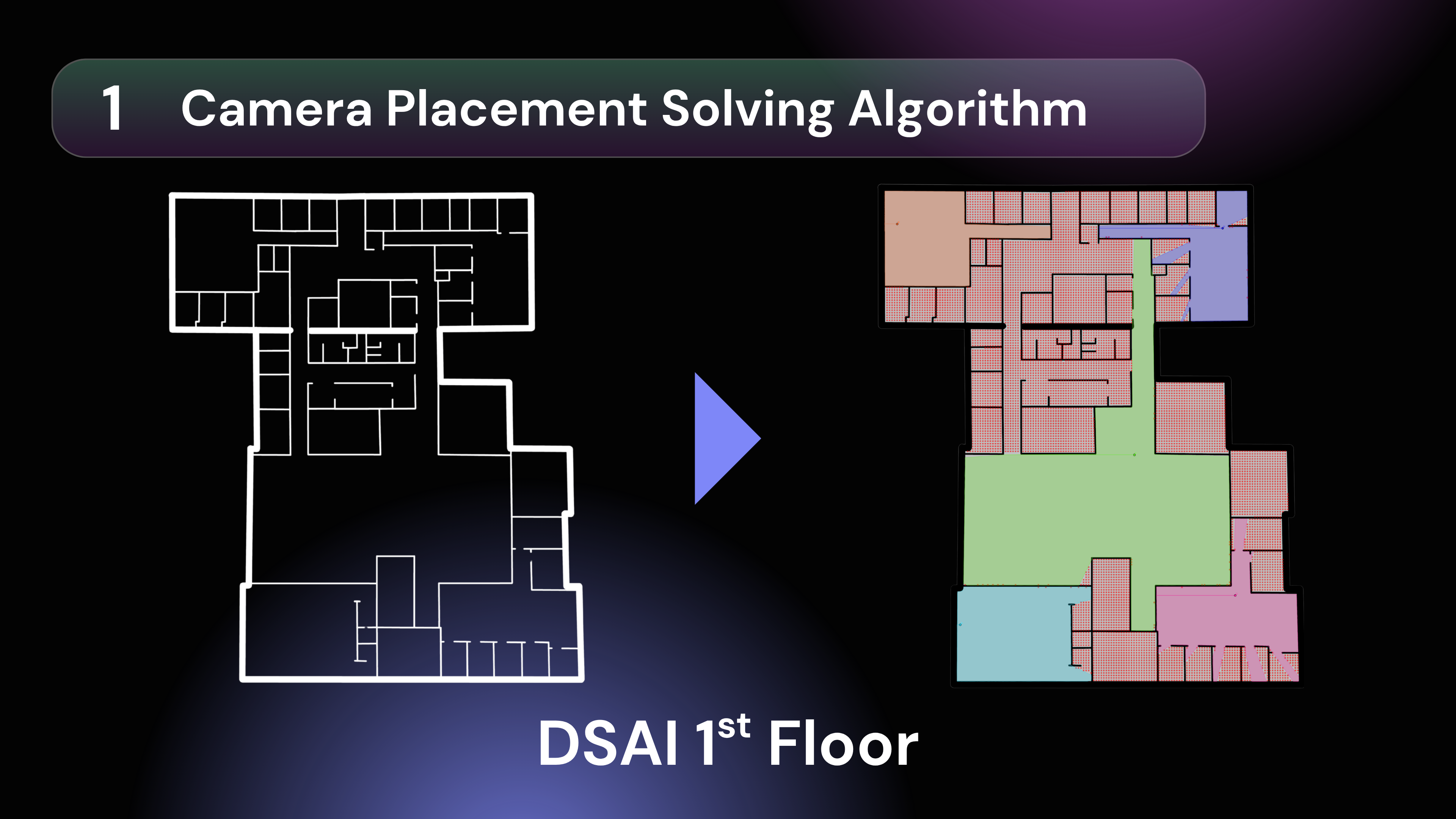
Algorithmic Coverage & Synthetic Training Our Camera Placement Solver calculates optimal configurations to maximize coverage and minimize hardware costs. From these virtual vantage points, Siqur generates thousands of synthetic scenarios to train on nuanced behavioral triggers (like body language) rather than biased demographic profiles. Users can even create custom scenarios to stress-test the model's predictive accuracy before deployment.
Natural Language Search: Security teams can query footage effortlessly (e.g., "Show me anyone entering the north exit with a package"), eliminating hours of manual scrubbing.
Proactive Intervention: Upon threat detection, Siqur maps the perpetrator's real-time path and triggers instant alerts, equipping responders with actionable context to intercept situations before they escalate.
The Sique Advantage: We move security from reaction to prediction, turning every camera into an expert observer operating with human intuition at AI scale.
How we built it
Two-Stage Camera Placement Engine (Python)
We discretize floor plans and cast 360 rays per candidate to compute visibility polygons with line-of-sight constraints. A 90° FOV sweep determines optimal yaw.
Phase 1: Fast greedy algorithm yields a log-optimal approximation. Phase 2: For <50 cameras, a Google OR-Tools CP-SAT ILP solver runs 4 parallel workers to find the provably minimal layout.
GPU-Accelerated Video Generation
An isolated worker loads the Wan I2V 14B diffusion model into GPU memory. WebSockets stream per-step previews. On Nvidia DGX Hopper, we use: • VAE tiling to avoid OOM • TF32 matmul (~3× faster) • PyTorch Flash SDPA attention
Frames pipe to FFmpeg and encode to H.264 MP4 (faststart) for instant playback.
World Model → Gaussian Splat Generation
We implemented a 3D world model from multi-view imagery. Outputting a Gaussian splat field—millions of anisotropic 3D Gaussians optimized for photorealistic reconstruction.
The digital twin enables real-time rendering and simulation.
Immersive Next.js Frontend
The UI transitions via framer-motion through: • Mapbox Globe: Select buildings • 2D Optimizer: Input budgets, watch real-time placement • 3D Gaussian Splatting: Powered by mkkellogg/GaussianSplats3D
High-Velocity FastAPI Backend
Built for hackathon speed, we use in-memory sessions. Decoupling FastAPI from the GPU worker via WebSockets keeps the API responsive during heavy diffusion workloads.
Watchman: Agentic Cross-Camera Motion Reconstruction
Watchman bridges blind spots across camera feeds. When a subject disappears and reappears, it correlates identity using temporal and spatial priors, reconstructing continuous trajectories through unseen space.
The system ingests synchronized feeds with learned offsets, runs per-frame detection via SAM2, and projects detections into 3D coordinates. A spline-based agentic solver interpolates smooth, physically plausible motion (walking, pausing, sprinting).
Multiple subjects are tracked simultaneously with color-coded trajectories rendered as Line2 progressive animations over the 3D interior.
What we learned
The Power of Hybrid Optimization Combining classical algorithms with modern generative AI is incredibly effective. We learned to orchestrate a two-phase camera placement engine: pairing a rapid, log-optimal greedy set-cover algorithm with a Google OR-Tools CP-SAT ILP solver for exactness.
2D Proxies for 3D Spatial Reasoning We discovered that 2D ray-casting is a highly accurate, performant proxy for 3D camera coverage. By casting 360 rays per candidate position to compute visibility polygons, then applying a sliding FOV window to optimize yaw, we achieved precise spatial reasoning without the overhead of a full 3D simulation.
Productionizing Large Diffusion Models Running a massive model like Wan I2V in production requires aggressive memory management. We learned the practical necessity of implementing VAE tiling, TF32 matmul, and Flash SDPA. Furthermore, architecturally isolating the model in a dedicated GPU worker—communicating via WebSockets—was critical to keeping our FastAPI web server responsive and restartable during intensive diffusion cycles.
What's next for SIQUR
Automated Photogrammetry for Global Scale Our highest-value next step is expanding beyond our initial Purdue environment by integrating photogrammetry workflows. By automatically sourcing images to generate interior and exterior 3D splats, we can deploy Siqur for any facility worldwide—shrinking enterprise onboarding time from days to mere hours per building.









Log in or sign up for Devpost to join the conversation.