Flu seasons are unpredictable and can be severe. According to the Centers for Disease Control and Prevention (CDC), it is estimated that more than 200,000 people are hospitalized from seasonal flu-related complications in the United States each year. In our project, we attempt to monitor and predict flu trends in real time, using query-based flu estimates as well as social media data. Our analysis is done at big data scale and empowered by IBM’s analytics for Hadoop.
A flu surveillance system can make enormous social impact. According to CDC, between 1976 and 2006, estimates of flu-associated deaths in the United States range from a low of about 3,000 to a high of about 49,000 people. Seniors, young children, pregnant women, and people with certain health conditions can be more susceptible to the flu virus. Our project aims to help people who are at high risk for serious flu complications by keeping them informed when there is high flu activity at places where they live or plan to go. Furthermore, our goal is to make the information as accessible as possible so they can stay constantly vigilant.
During the process of our project we gained insight to the factors that influence the spread of flu as well as some preconceived assumptions that did not contain correlations. In addition to the insights gained from the research of our chosen domain, we discovered a coding issue within the Node-RED platform that needed to be resolved in order for it to work with scaled HDFS data. By identifying this issue we were able to improve this system for our use in the Big Data for Social Good Challenge as well as future users of this service.
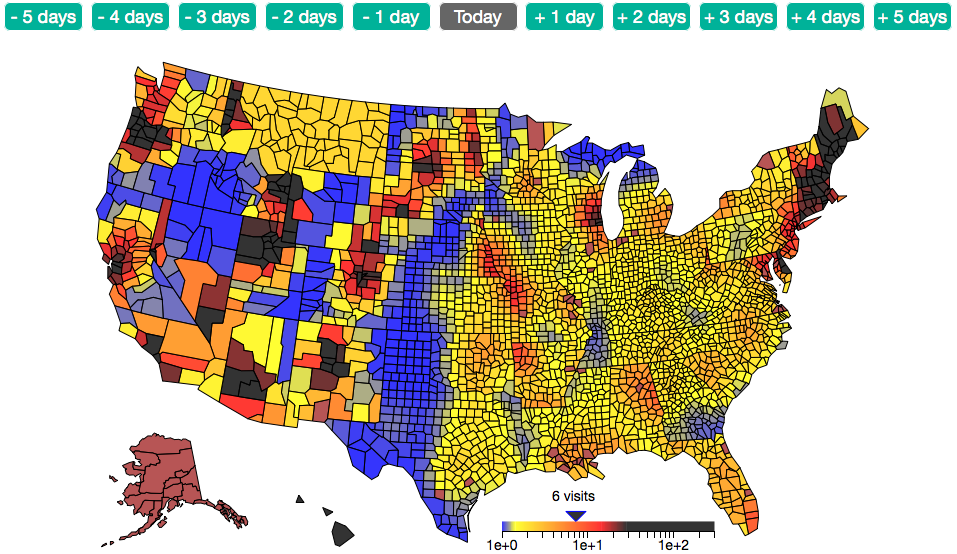
Our motivation for this project was to create a visualization of the flu that could be displayed on a map of the US in a way that relates to a weather map. By doing this the end user can benefit in seeing both the historic and forecasted dispersion of flu incidents in the US to gain a better understanding of risk in their area. An additional motivation was to improve upon current models of flu prediction in identifying the weakness in variables and diversify that risk by including additional variables.
Built With
- afinn-111
- bluemix
- census.gov
- css
- daily-global-weather-measurements
- hdfs
- javascript
- national-household-travel-survey
- node-red
- r
- sas
- weather-underground






Log in or sign up for Devpost to join the conversation.