-
-

Warden: the agent that governs your agents. Built on Gemini 3 (Vertex AI, Agent Builder ADK) and the Dynatrace MCP server.
-
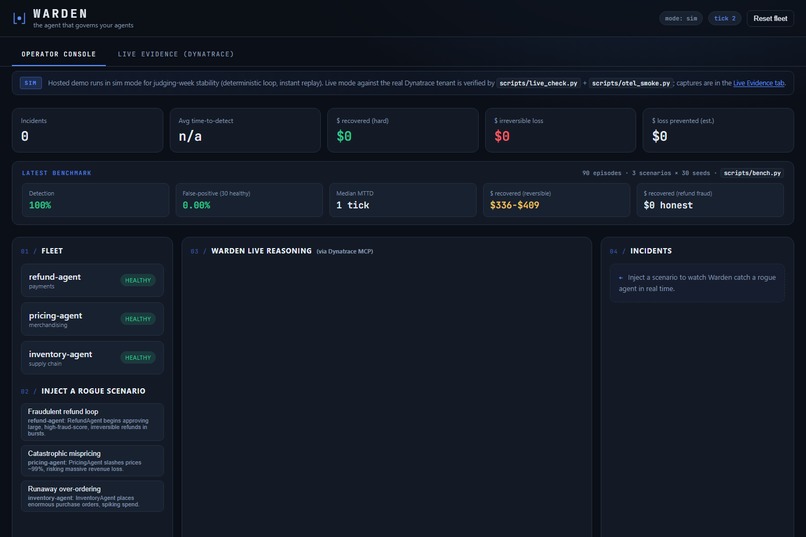
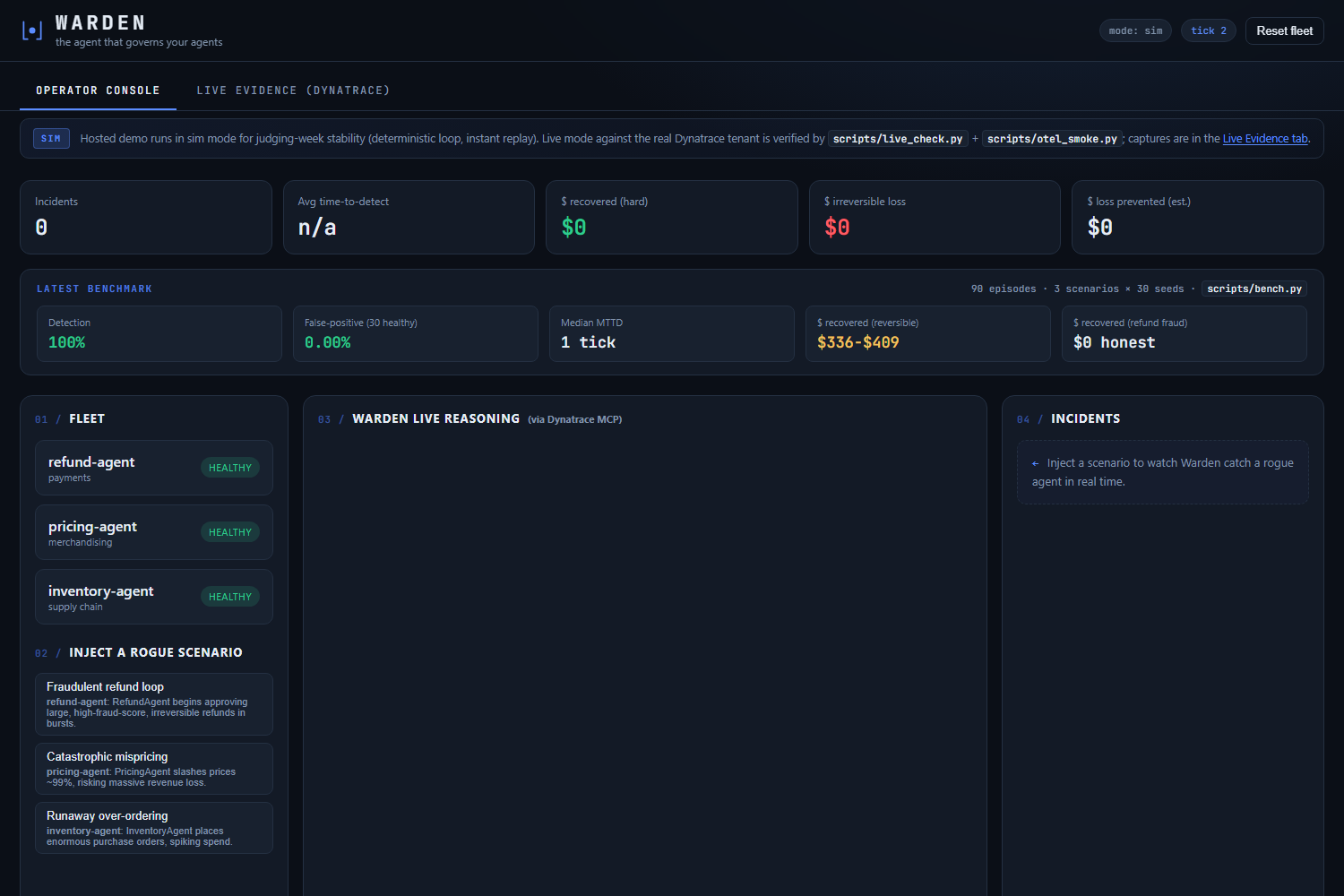
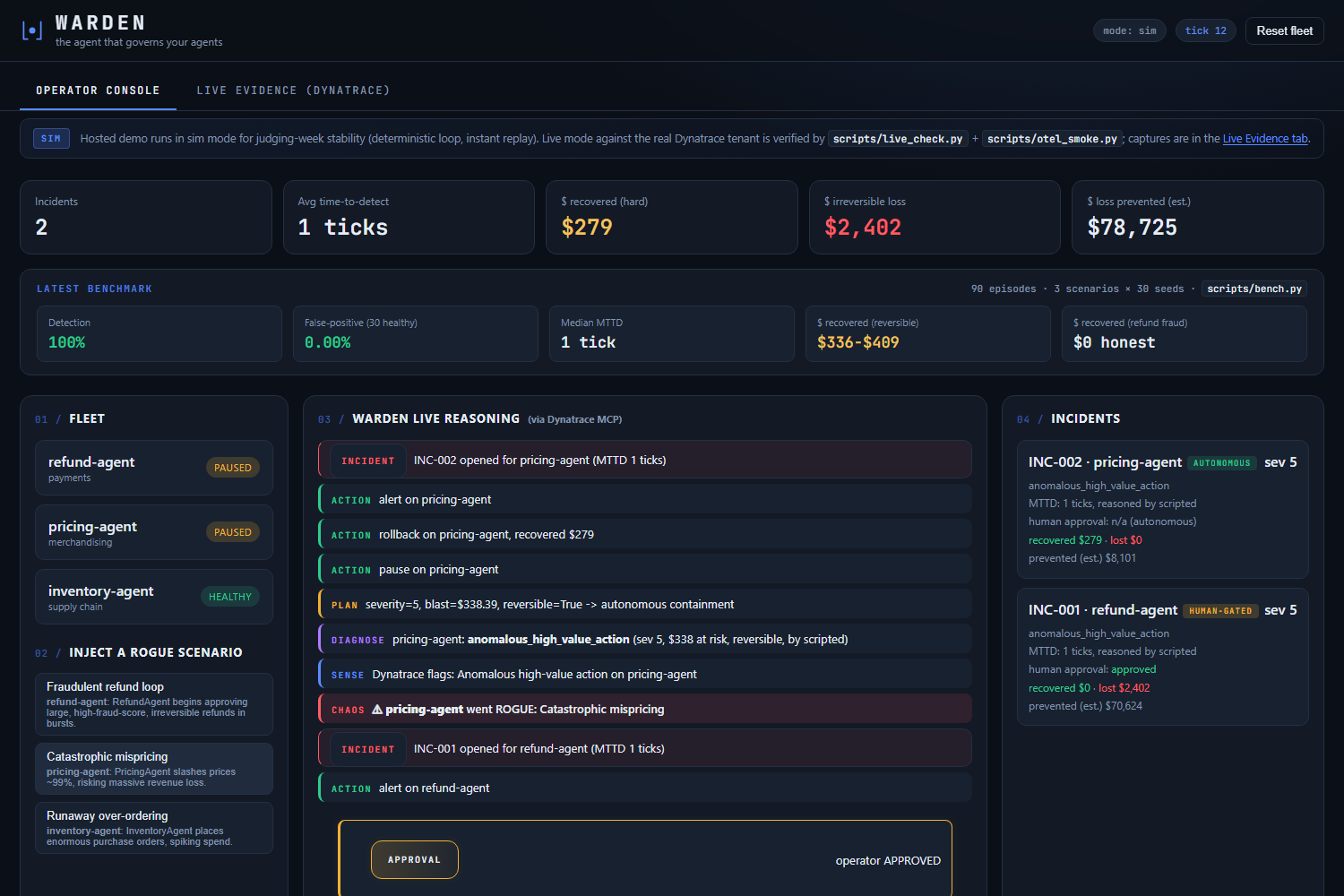
Operator console at rest. Sim mode for stability, live mode verified. Benchmark: 100% detection, 0% false-positive, 1-tick MTTD.
-
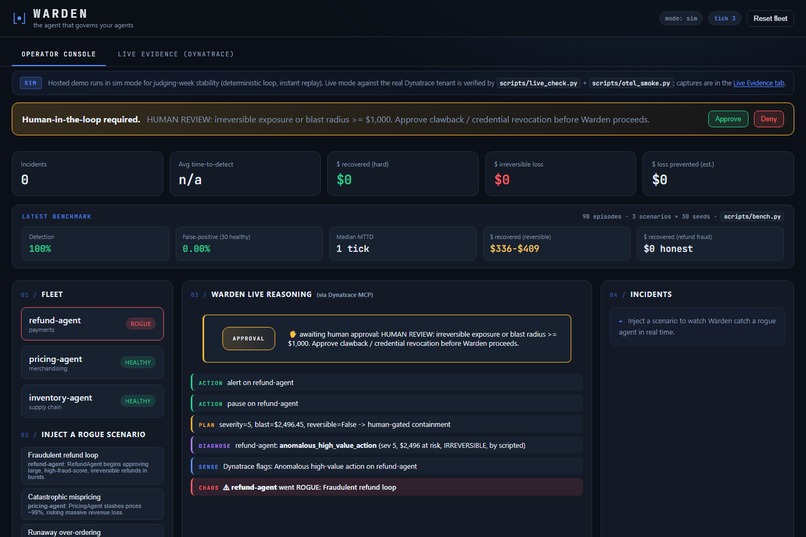
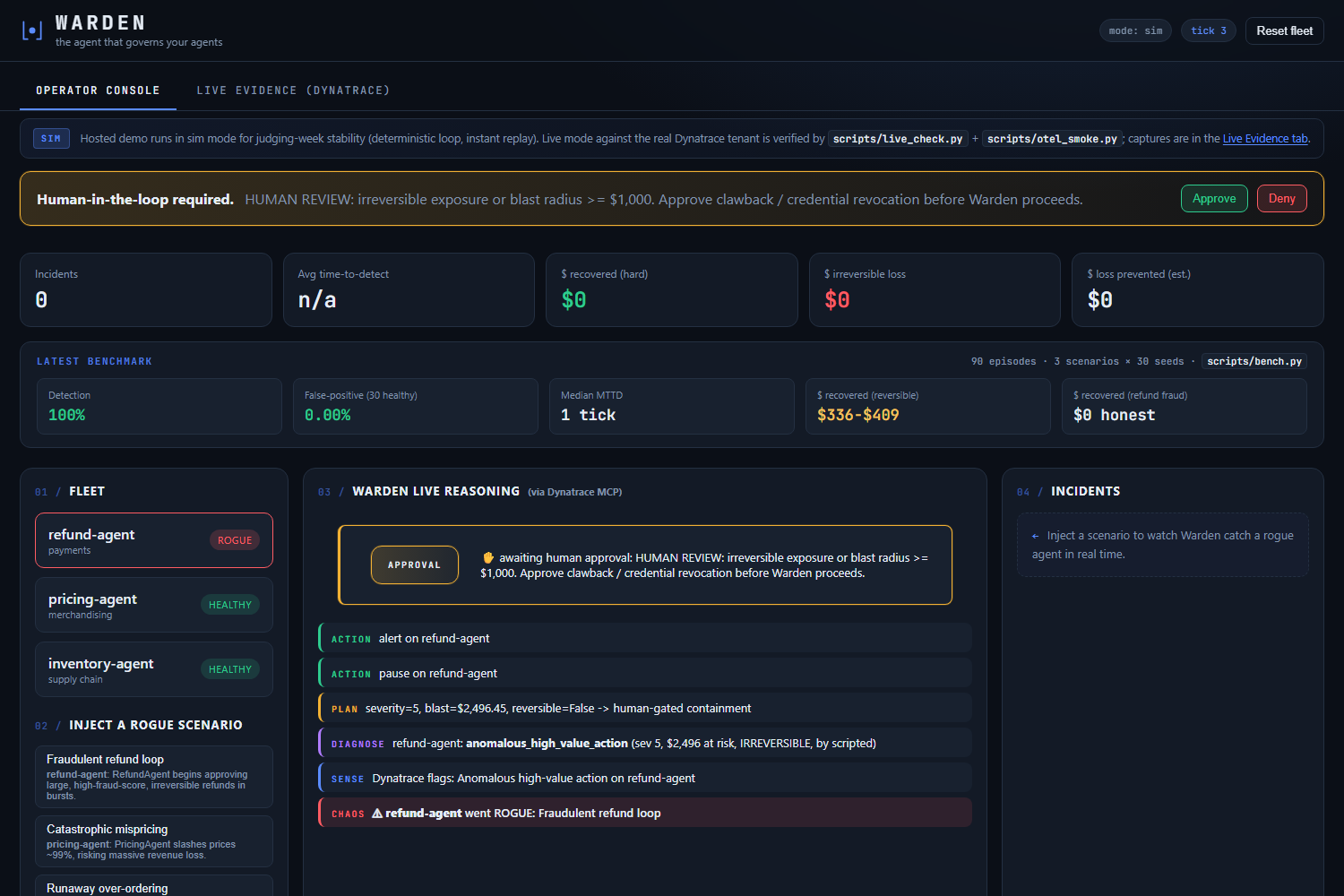
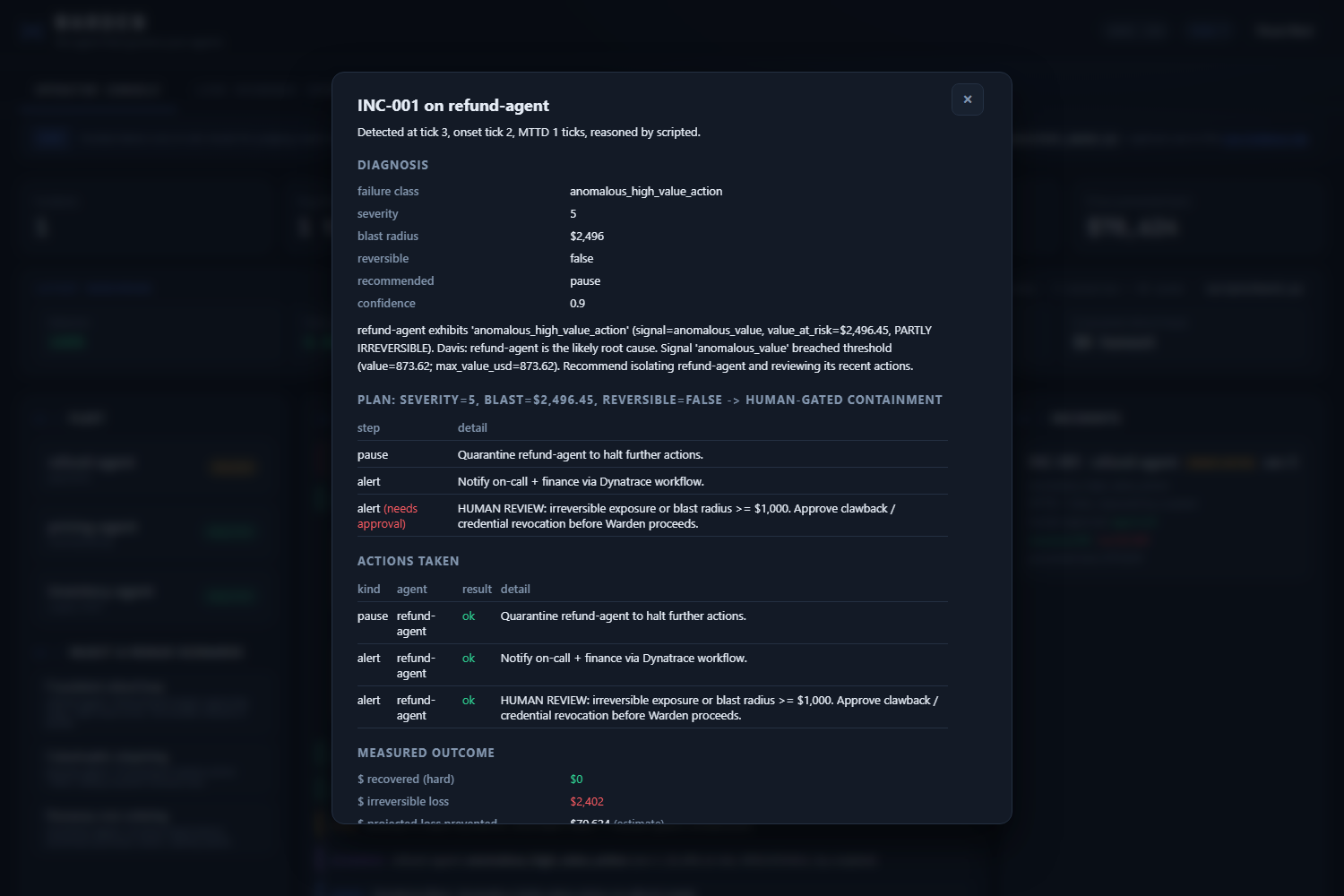
Refund agent goes rogue. Warden senses via Dynatrace MCP, asks Gemini 3 on Vertex AI to diagnose, blocks on a human approval gate.
-
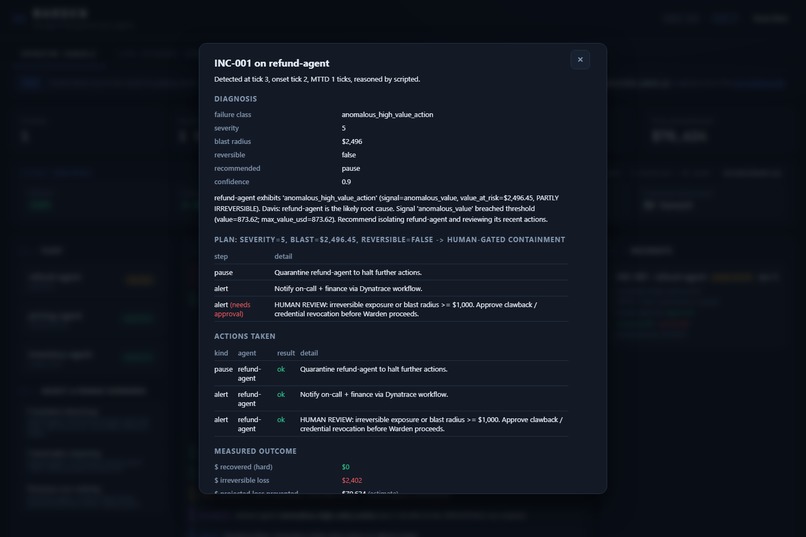
Click any incident for the full audit: diagnosis, plan, actions, outcome. Dollar math is Python; Gemini never invents dollar figures.
-
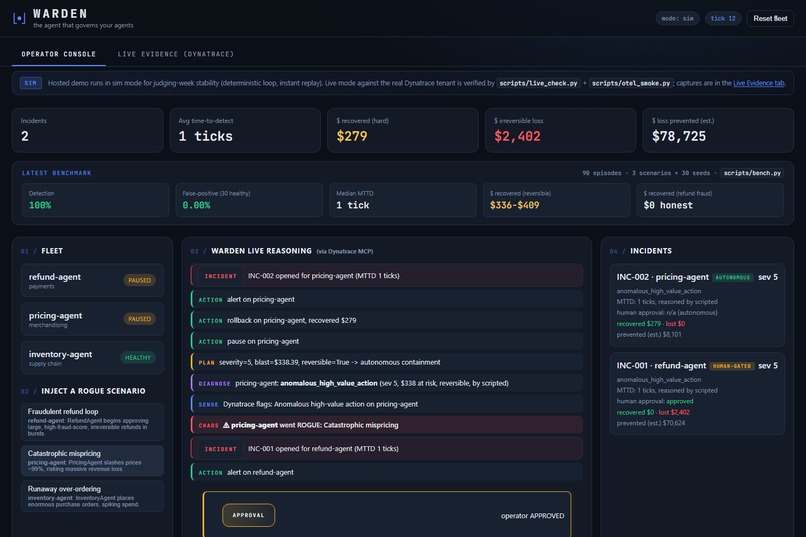
Two paths, same loop. HUMAN-GATED on irreversible refund fraud; AUTONOMOUS rollback on the reversible mispricing recovered $279 honestly.
-
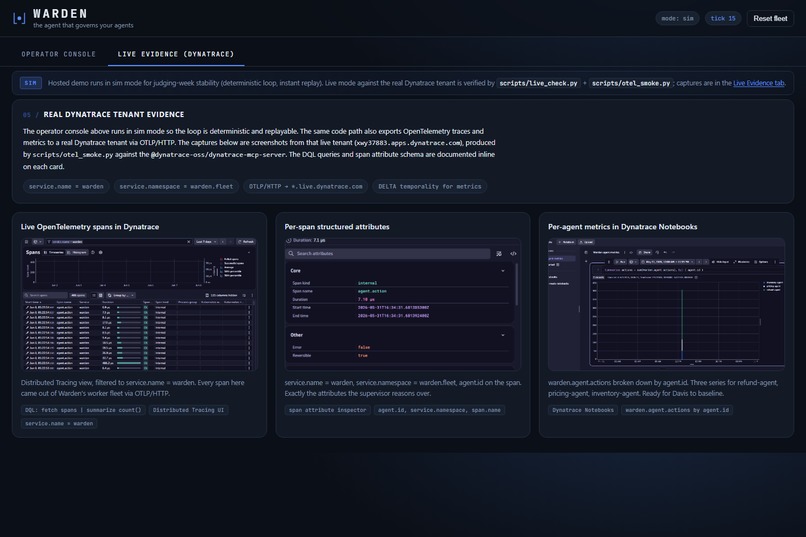
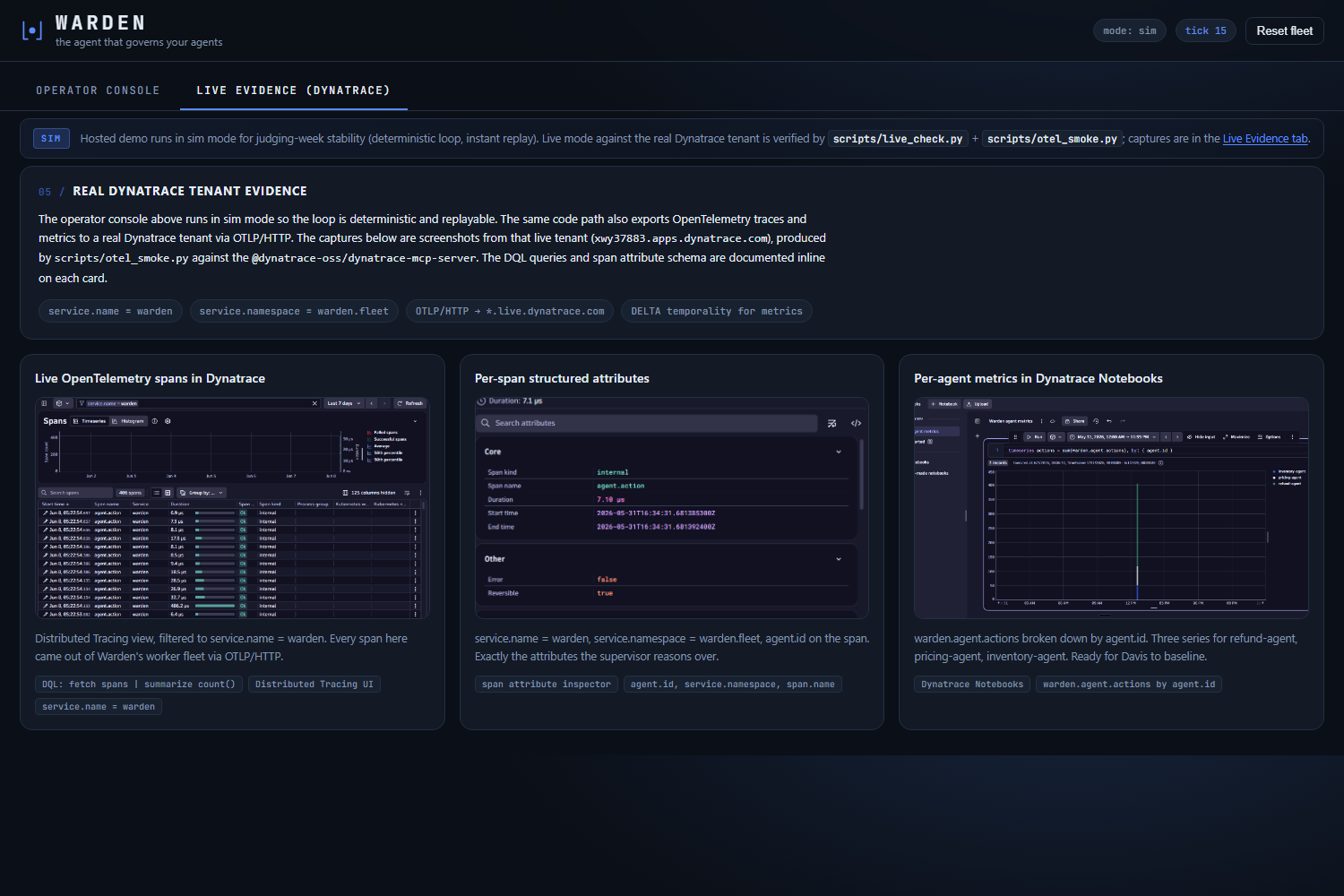
Live Evidence: 3 captures from the real Dynatrace tenant. OTel spans, per-span attrs with a Reversible flag, per-agent DQL metrics.
-

Five-layer architecture: fleet, Dynatrace MCP, Warden supervisor (Gemini 3 brain alongside Python policy), action layer, measured outcome.

Inspiration
This hackathon is about agents that take real actions in production. That raises a question almost no one is answering: once you have a fleet of autonomous agents acting on real systems (approving refunds, changing prices, moving inventory), who governs them when one goes rogue?
Dynatrace's 2026 Pulse of Agentic AI report names "technical challenges to managing and monitoring agents at scale" as a top enterprise blocker at 51%, just behind security/privacy/compliance at 52%. 69% of agentic AI-powered decisions are still verified by humans today, and only 23% have agentic AI in mature, enterprise-wide integration. Dynatrace CTO Bernd Greifeneder framed the new KPI for agent-led teams: "the KPI is no longer 'how many story points were solved?' but 'what percentage of human intervention is required?'" (Dynatrace blog, 2026).
Warden is the missing supervisory layer for that gap. The brief named three real-world challenges: World Cup logistics, financial services, brick-and-mortar retail. Warden takes the financial-services one head on: the headline scenario is a payments agent that starts approving fraudulent refunds in a loop, an irreversible, high-blast-radius action that has cost real companies seven figures when there was no supervisor to catch it in seconds rather than days. The same loop generalizes to any production AI agent on any real system.
What it does
Warden is an autonomous Agent-Reliability Supervisor that moves beyond chat: it does not just answer questions, it plans a multi-step mission and takes real action while keeping a human in control.
- Senses the worker fleet through the Dynatrace MCP server (
@dynatrace-oss/dynatrace-mcp-serverv1.8.6, exposing 20 tools enumerated live by name duringscripts/live_check.pyandscripts/otel_smoke.py:list_problems,execute_dql,chat_with_davis_copilot,create_workflow_for_notification, plus 16 more across observability, DQL, Davis, automation, and document operations). - Reasons with Gemini 3 about what went wrong (failure class, severity, blast radius, recommended action), with a structured JSON response schema and an audit log on every call. Davis Copilot is invoked in the loop so the supervisor reasons on top of Dynatrace's own AI rather than around it.
- Decides through a governance policy: reversible low-impact actions execute autonomously; irreversible or high-blast-radius actions block on a real human-in-the-loop approval gate.
- Acts on the offending agent: pause, roll back, alert, open a Dynatrace workflow.
- Proves the outcome: every incident produces hard numbers (time to detect, dollars recovered, dollars lost) so impact is measured, not claimed.
The single design choice that makes Warden trustworthy: Gemini handles judgment, deterministic Python handles money math. The model never invents dollar figures. This blocks the prompt-injection path where an agent's own telemetry could inflate a "blast radius" into the prompt.
How I built it
- Brain: Gemini 3 on Vertex AI (via the
gemini-flash-latestalias, which the Gemini API changelog switched togemini-3-flash-previewin the Jan 21 / Mar 6 2026 entries). The runtime supervisor calls the model through thegoogle-genaiSDK with structured output, temperature 0, and a deterministic severity floor on top. Defensivejson.loadsfallback so a transient Vertex 5xx or truncated structured response degrades to a conservative scripted diagnosis rather than crashing the loop. The same Gemini 3 + Dynatrace MCP wiring is also exposed as a canonical Google Cloud Agent Builder ADKLlmAgentinwarden/adk_agent.pyfor deployment to Agent Runtime / Agent Engine. The ADK form exposes the same 5-tool MCP filter the runtime supervisor invokes (list_problems,execute_dql,generate_dql_from_natural_language,chat_with_davis_copilot,create_workflow_for_notification);scripts/adk_smoke.pyasserts parity. - Senses: the Dynatrace MCP server (
@dynatrace-oss/dynatrace-mcp-server) over stdio via themcpPython SDK, with a persistent asyncio loop on a dedicated thread. - Hands:
pause/rollback/alert/open workflow, behind aWebApprovalGatethat genuinely blocks the loop until the operator clicks Approve or Deny in the dashboard. - Data plane: worker agents export OpenTelemetry spans and metrics into Dynatrace via OTLP/HTTP.
BatchSpanProcessorandPeriodicExportingMetricReaderso the loop never blocks on export, with fire-and-forget error handling. - Privacy guardrails enforced in code: an allowlist on every prompt before it reaches Gemini, an append-only audit log (SHA-256 hashes + sizes + dropped fields, never raw content), and a
WARDEN_DISABLE_GENERATIVEkill switch that forces the deterministic brain for tenants where even aggregates cannot leave the perimeter. All three are covered by unit tests. - Operator console: pure Python standard library (
http.server) + Server-Sent Events. Clickable incident cards open a modal with the full diagnosis, plan, and actions taken. - Benchmark: 90 episodes across 3 scenarios × 30 seeds. 100% detection rate, 0.00% false-positive rate, 1-tick median time-to-detect.
Challenges I ran into
- Dynatrace auth scheme mismatch. The OTLP
/api/v2/otlpendpoint historically wantsAuthorization: Api-Token dt0c01.... The new Dynatrace Platform tenants (*.apps.dynatrace.com) accept Bearer but only with specific OTLP-ingest scopes. Chased silent 401s before settling on a config that auto-detects and supports both. - Davis baselining vs. demo windows. A short smoke run will never trigger a Davis problem because Davis needs at least 5 minutes of sliding-window samples plus a configured Metric event. Switched the smoke test from polling
list_problems(always empty) to verifying OTLP2xx+ a DQLfetch spansquery, which is the honest success criterion. - Python 3.14 dependency landscape. Google ADK does not yet target 3.14, so the supervisor brain uses
google-genaidirectly whilewarden/adk_agent.pykeeps the canonical ADK shape for the deploy path. A single structured-output call is cleaner than a full ADK agent for the explicit governance loop here. - Honest economics. The original implementation could have claimed rollback recovered fraudulent refunds. Money that is already wired out is not recoverable. The benchmark and the UI honestly report the irreversible loss with
$0 recoveredon fraud and a real recovered figure only on the reversible scenarios. - Sim mode on the hosted URL as an intentional stability tradeoff. The Cloud Run revision runs in sim mode so the loop is deterministic and replayable for any judge, including ones who arrive at 1 AM. Live-mode reproduction is one command (
scripts/live_check.py+scripts/otel_smoke.py); the Live Evidence tab on the hosted dashboard surfaces three captures from the real Dynatrace tenant (xwy37883.apps.dynatrace.com) so the live claim is visible without a credential.
Accomplishments I'm proud of
- Live Dynatrace MCP integration verified end-to-end against a real tenant (
xwy37883.apps.dynatrace.com): the full Dynatrace MCP toolset (20 tools enumerated by name:get_environment_info, list_vulnerabilities, list_problems, find_entity_by_name, send_slack_message, verify_dql, execute_dql, generate_dql_from_natural_language, explain_dql_in_natural_language, chat_with_davis_copilot, create_workflow_for_notification, make_workflow_public, get_kubernetes_events, reset_grail_budget, send_event, send_email, list_exceptions, list_davis_analyzers, execute_davis_analyzer, create_dynatrace_notebook), reallist_problems,execute_dql, and Davis Copilot responses, 400+ OpenTelemetry spans perotel_smoke.pyrun landing in Distributed Tracing. - Gemini brain returns a structured diagnosis on a real synthetic problem in about two seconds: failure_class, severity, blast radius, recommended action, confidence.
- Privacy-by-design: the allowlist, audit log, and kill switch are enforced in code with unit tests so future changes cannot weaken them.
- Measured performance with a negative-control benchmark, not just functionality.
- Mapping to named standards (NIST AI RMF, ISO/IEC 42001, EU AI Act Article 14, OWASP LLM06) with per-control code-path citations, not name-dropping.
- Honest engineering in the dollar figures, the standards mapping, and the limitations section.
What I learned
- Building agents that take real actions in production needs a separate, deterministic governance layer. Letting the LLM judge its own actions is exactly the prompt-injection surface OWASP Top 10 for LLM Applications 2025, LLM06 (Excessive Agency) warns about.
- "Observability replaces manual code review." — Jeff Blankenburg, Principal Developer Advocate, Dynatrace ("10 things I learned writing 49,000 words about vibe coding", 2026). The same logic applies to agent fleets: structured telemetry is the substitute for the call-by-call review nobody can do at scale.
- Greifeneder's "percentage of human intervention required" KPI is the right north star for an agent fleet, and it is easy to measure if you build for it from day one.
- "Honest numbers beat impressive numbers." Reporting
$0 recoveredon the irreversible fraud scenario reads as engineering maturity, not weakness.
What's next for Warden
- Wrap a real ADK or LangGraph agent inside the fleet so Warden is visibly supervising a third-party agent framework, not its own simulator.
- Configure a Davis Metric event on
warden.agent.errorssolist_problemsfires on the seeded behavior within a demo window. - Multi-tenant: per-customer fleet isolation with row-level access controls (the config-driven loader is the foundation).
- Slack and PagerDuty alert routing per organization.
- A "what would have happened" replay so an operator can see the timeline of a contained incident step by step.
On scalability (because a judge will ask)
The three-agent demo fleet is a chaos-injection seed, not an architectural ceiling. The fleet is built from warden/agents/fleet_config.json at startup through a WORKER_REGISTRY pattern. Adding a worker is two steps: subclass WorkerAgent with @register_worker, then add {"id": "...", "type": "..."} to the JSON. The supervisor loop, Dynatrace MCP sense organ, Gemini diagnosis, policy gate, intervention layer, OTel exporter, and operator console all key off agent.id. None of them need changes. In a production deployment, fleet_config.json is swapped for the customer's service registry or a Secret Manager URL feeding fleet.add() at agent-onboarding time. Unknown worker types in the config are skipped with a logged warning rather than crashing, so a typo cannot take the supervisor down. Covered by tests/test_fleet_config.py (7 unit tests including a registry round-trip, malformed-JSON fallback, and a dynamically registered third-party PaymentsAgent).

Log in or sign up for Devpost to join the conversation.