

Inspiration
Image recognition of camera trap photos is a promising technology for monitoring the abundance and distribution of rare animal species. There are many platforms that provide image recognition service, each with its own strengths and weaknesses. Large conservation projects that monitor diverse sets of species are in need of generalized image recognition tools that leverage multiple platforms.
What it does
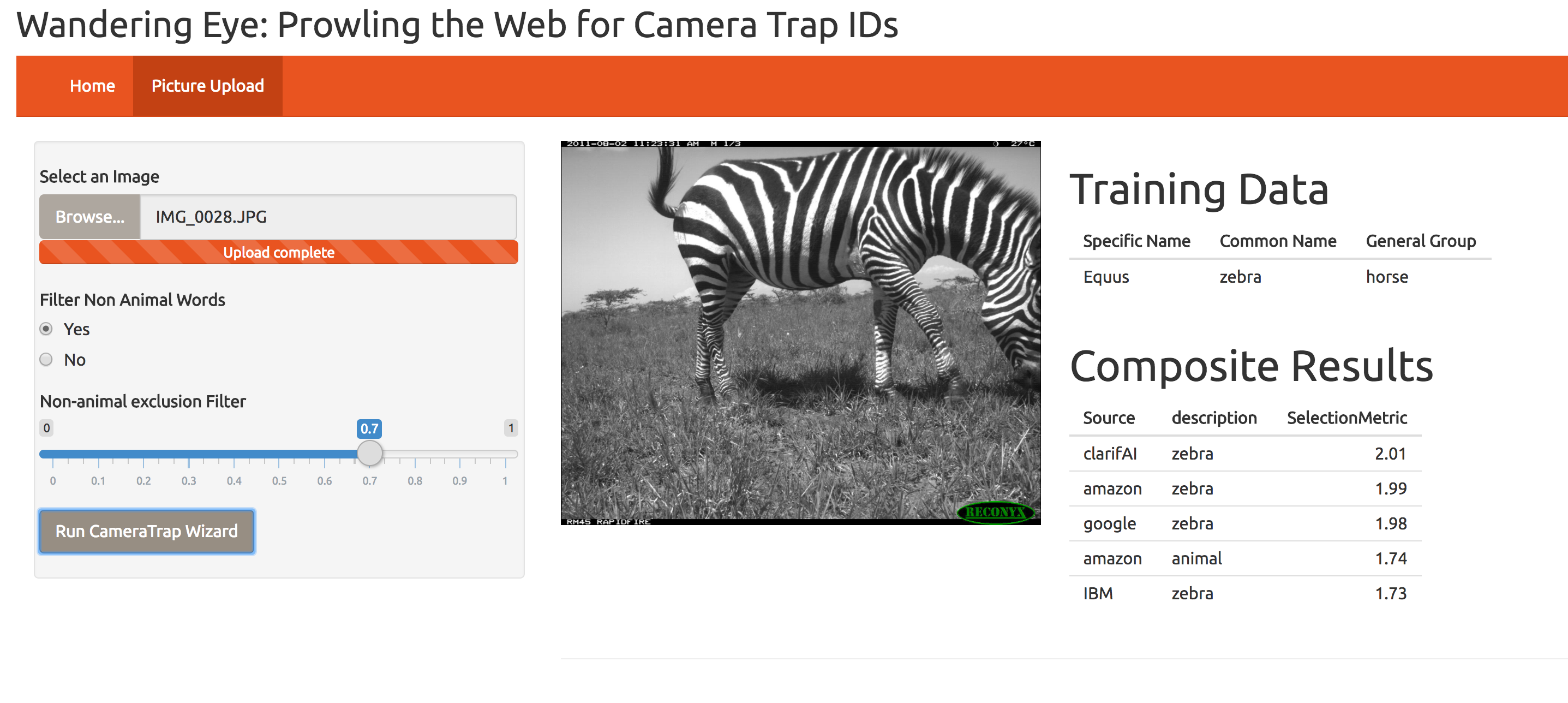
WanderEye is a universal service layer that compiles the output from four computer vision APIs: Google Cloud Vision, Amazon Rekognition, ClarifAI, and IBM Watson. The main end goal of this product is to create a code pipeline for camera trap users or existing camera trap analysis apps such as SMART to query four image recognition APIs to receive compiled species identification data for large file sets. We provide also "composite output" which ranks the results across the four engines based on the certainty of the ID and the specificity of the output. Today, we present a demo that allows side by comparison of these computer vision algorithms for pre-processed training images.
How we built it
Our team programmatically accessed the APIs for each of the four image recognition engines through either R or python. We standardized the output from each of the API to create a universal result for all images uploaded.
To remove non-animal words from the image recognition output, we used text mining analysis in R to determine the cosine similarity of each output word to the word "animal", and then used trial and error to filter this score. We also cross referenced our list against a list of common mammals to account for the fact that specific animal words aren't always present in the dictionaries used for the text mining analysis.
We ranked the ID terms across image platforms by creating an selection metric integrates the confidence of the image ID according to its engine and the specificity of the word relative to "animal" determined by calculating asymmetrical word similarity in R.
To test the effectiveness of our composite output, we manually identified the animals in a set of 140 camera trap training images to species and family and noted color scale, number of animals, and time of day of each image. We tested the the relative effectiveness of each engine in identifying images to species and family. We also evaluated if our composite data was better than use the best engine individually.
Challenges we ran into
- Removing non-animal ID terms from image recognition service outputs
- API limits and fees
- Ecology specific APIs were difficult to “crack” and attempts at manipulating Microsoft Computer Vision API were not fruitful
- Creating a Training Dataset (and hoping that we were accurate in our manual identification!!)
- Prioritizing more specific animal terms over others (like “leopard” vs. “cat”)
- Had teammates using multiple platforms
Accomplishments that we're proud of
- Hacking 4 different APIs!
- Addressing the specificity of narrowing down word choices to animal-related terms
- Getting a demo up with only a 4 person team in less than 36 hours!
What we learned
That looking at photos and trying to identify species is hard!
What's next for WanderingEye
- Adding more APIs like iNaturalist, Microsoft Computer Vision, Extract Compare, Wild-ID and Camelot
- Creating a larger animal-related dictionary of terms to help better exclude irrelevant output words
- Conduct user interface research to learn which end user features are most valued Data Visualization features
- Implementing a real time pipeline for batch camera trap images
- Identifying images with partial limbs or blurry images is HARD!
NOTE: All camera trap images are copyrights of the Wildlife Conservation Society (WCS) and may only be accessed and used for the sole purpose of this challenge.





Log in or sign up for Devpost to join the conversation.