
Inspiration
I am working on a intelligent bots that will help people do more through natural language. Imagine a world where you can chat with an AMC bot and book your movies or a 49ers bot to learn about the latest game. These bots with need a corpus of knowledge to make sense of what the user is saying. HTMs seem like a natural fit due to their strong biological concepts and the highly connected nature of the HTM memory.
What it does
Meet
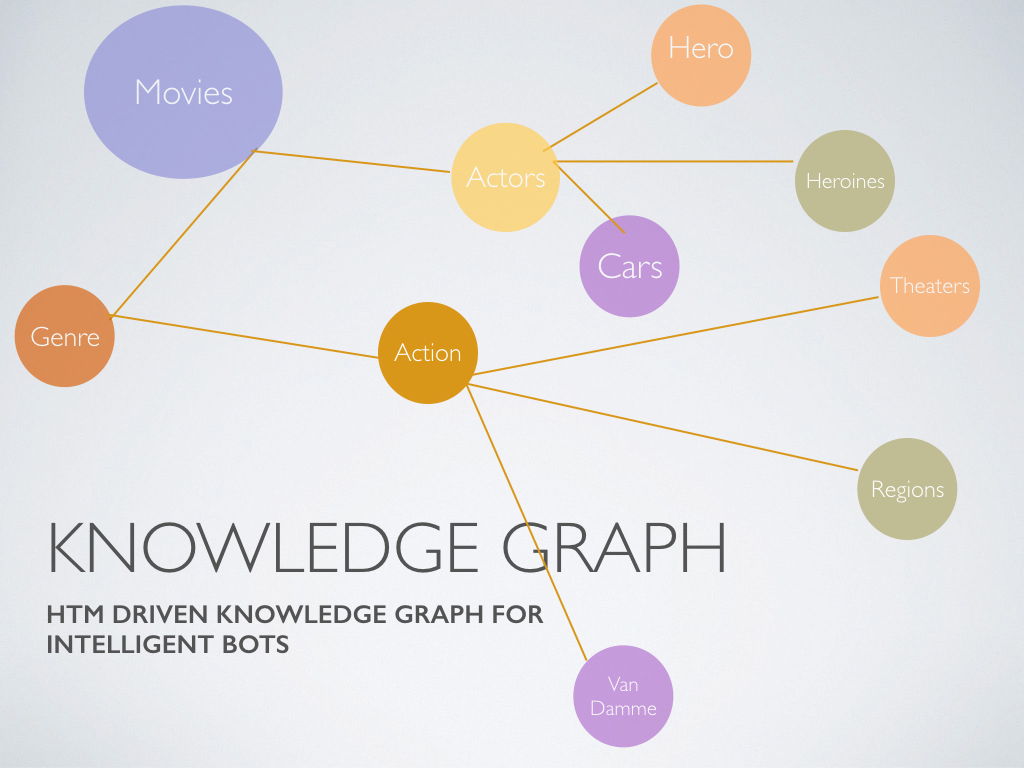
Hollybot is a bot, he lives in Slack [the popular messaging platform] and your phone. Hollybot knows about movies and uses his knowledge to help you with questions you have about movies. A user can ask about a movie, about a genre or anything in the world of movies. As long as Hollybot has seen it before in its corpus it will retrieve not just what you asked for but a knowledge graph of all other concepts that are related to that word .
A few sample interactions with Holly Bot:
User Text: "#hollybot help"
HollyBot response:
User Text: "#hollybot Toy Story"
HollyBot response:
The top section of movie related information is retrieved from an open movie database in realtime
The bottom section , the knowledge graph is retrieved from a HTM server.
Mobile Interface
Hollybot is available on you mobile phone. See Hollybot in action here. Requires slack mobile app. Supported on IOS and Android phones.
How I built it
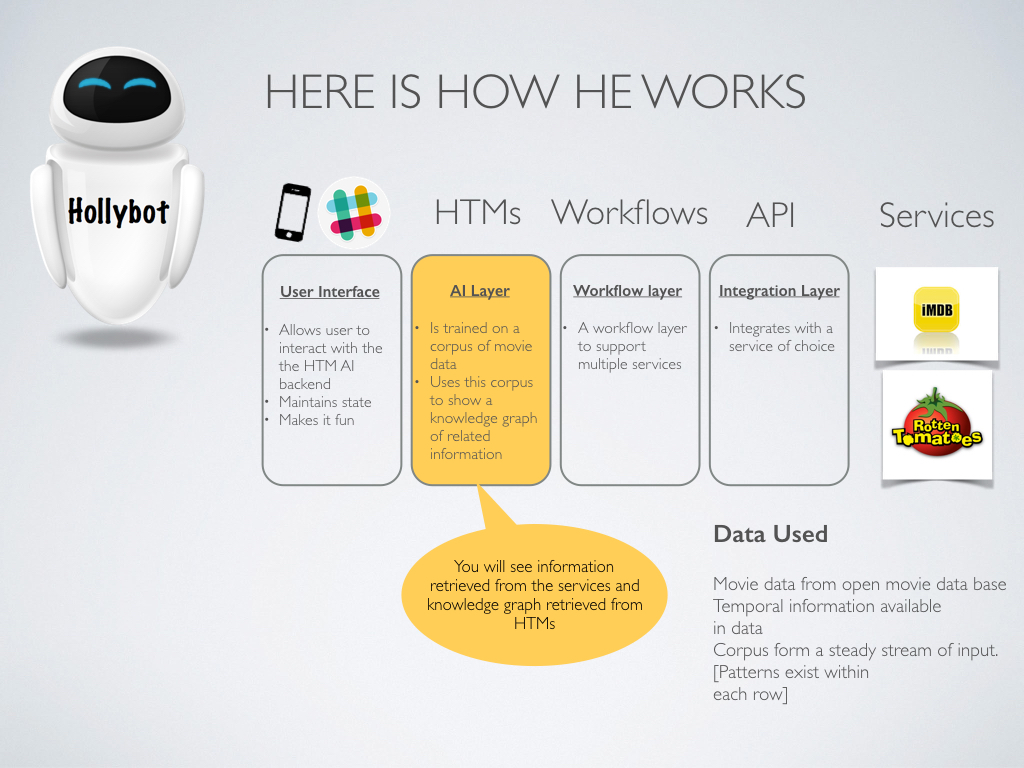
** Client Layer ** This is a slack client, It is hosted on a server and listens to chat messages in the #general channel of Slack. It looks for certain keywords being spoken. When it finds keywords it is looking for it takes an action
*AI Layer - HTMS * For this layer I have built and HTM server, the server is always on an allows for state being maintained in between interactions from the client layer. There is also a HTM client , that connects with the HTM server . This way the client may start and stop any number of times while the server in always on. The server is has a model defined via xml. This specifies the design of the HTM model. It has encoder, spatial pooler and temporal memory . There is also a new generic encoder which was built. The generic encoder is able to extract topological information from text. This allows for a robust representation of natural language which can be high in noise and error rates.
Data is fed in the form of CSV files, The model trains itself on each line of data in the CSV file and tries to make synapses with information it seen in each frame of data represented in a line. All of this data is stored in the HTM model which maintains the state in the form of synaptic connections between columns of cells in the HTM memory. Below is a picture of the training process. See the Raw value, Encoded value, and the predictions .
Technology Stack
Nupic, Python, Django , Custom Encoder, Json etc
*New Resources Developed *
- New encoder that captures information about textual data
- Nupic server and client that can maintain state in between calls from the user
- Hollybot for interaction and visualize the knowledge graph
- Integration with data from IMDB and OMDB about movies and movie related information
Challenges I ran into
While low level concepts are being captured and represented , I see that I may need a hierarchy of layers to capture higher level patterns. This is going to part of the next phase of this project
Accomplishments that I'm proud of
Being able to complete the project in time. Many of the concepts I am working on here are quite early stage. This required a lot of experimentation and discovery.
What I learned
The HTM theory can work for creating a robust knowledge graph. Also intelligent bots will have to depend on knowledge graphs if they are going to be useful for a common use cases
What's next for Walnut.Ai
Create a multi layer hierarchy to capture higher level concepts of the movie knowledge graph. Train the model with a very large corpus of data Create a test environment to continuously test the knowledge graph and introduce inhibitory connections











Log in or sign up for Devpost to join the conversation.