

Inspiration
What inspired us to make this project is our excitement about building a better user experience for online shoppers. In an era where efficiency in web navigation is crucial to the success of a company, we decided to take on the task of creating a search engine using web scraping techniques off of the Walmart.com website.
What it does
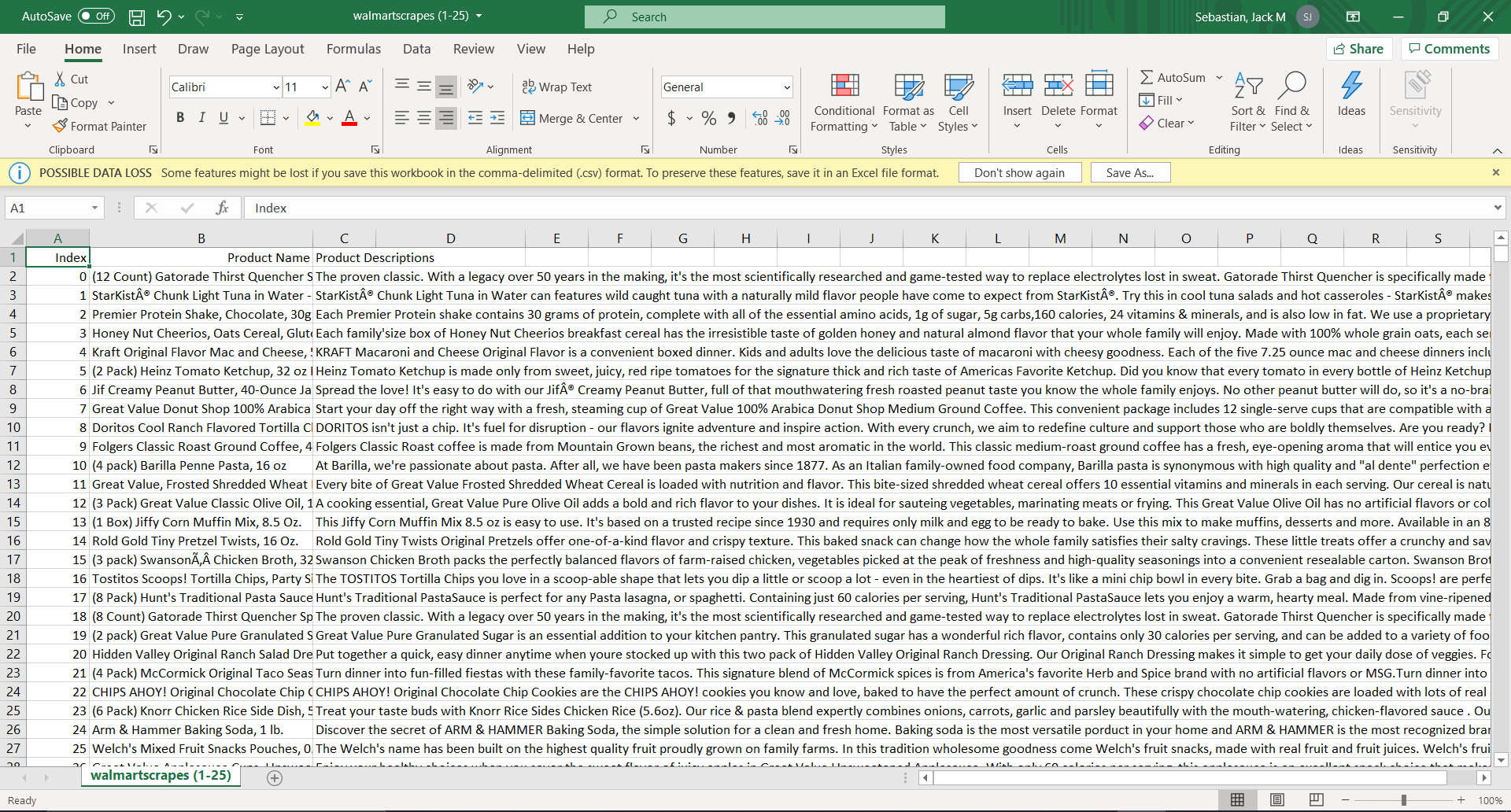
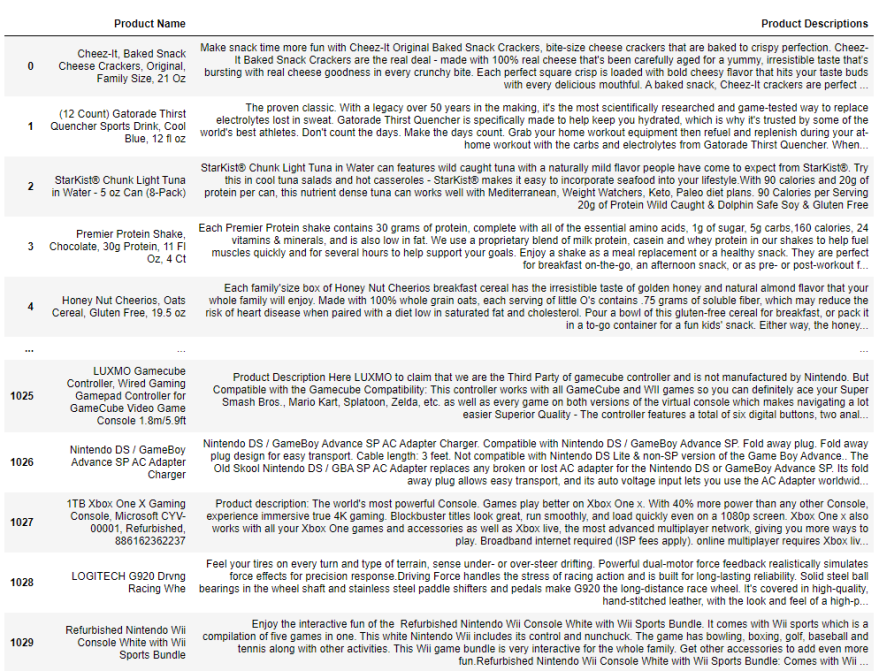
Our search engine will web scrape thousands of products off of Walmart.com and store information on the product name as well as its description. We then use this information to help generate similar products on the website based off of what a user types in as a query for the search engine.
How we built it
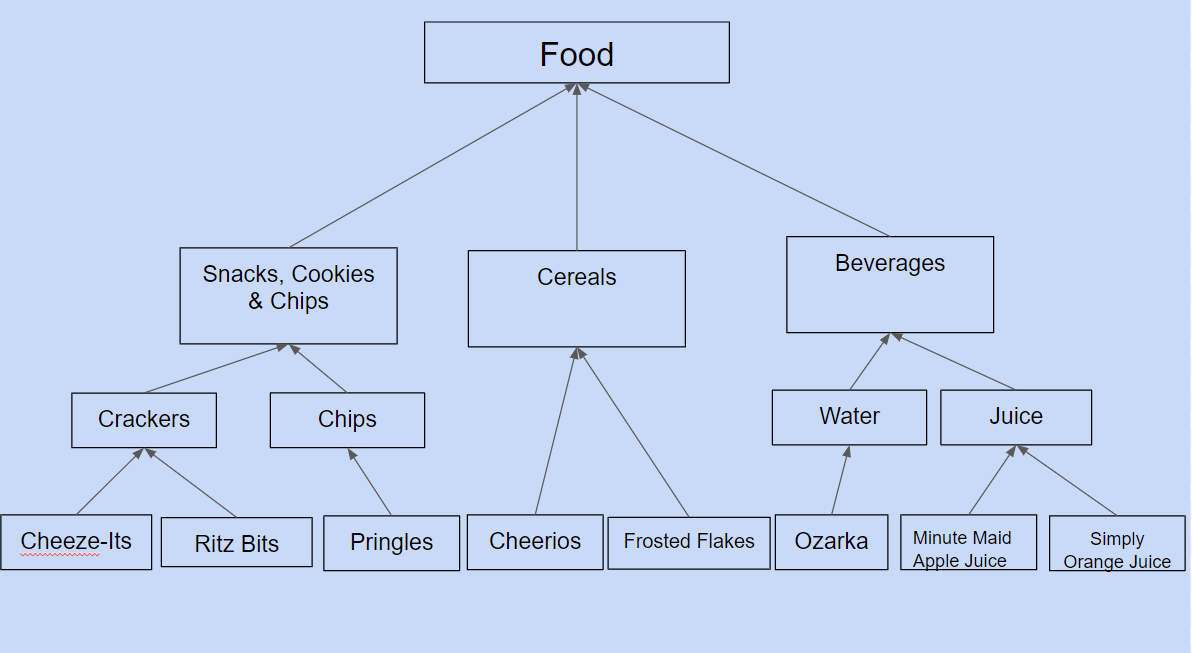
To build our web scraping algorithm, we used the BeautifulSoup package in Python. We then used Gensim library to implement natural language processing in determining how similar certain products were. Our two clustering criteria were the keywords in our product descriptions and the "bread crumb" lengths which are the navigation tabs used to access product web pages on Walmart.com. After that, we ran our Web graph against the user's query and outputted relevant products to them.
Challenges we ran into
None of our team members had experience doing any sort of data science and machine learning projects, so this was all extremely new to us. We had to take a ton of time during the hackathon to actually understand concepts and clustering models in order to carry out the task at hand.
Accomplishments that we're proud of
While this is nowhere close to a finished product, we are proud of the fact that the 3 of us managed to successfully scrape data off on thousands of product web pages on Walmart.com. Furthermore, we were also successful is using our natural language processing to compare the similarity/dissimilarity between products.
What we learned
We learned how to web scrape off an internet using the HTML source code on a website. We also learned about different clustering models, natural language processing, and principal components analysis.

Log in or sign up for Devpost to join the conversation.