-
-

CSV Data File Containing 47,000+ Scraped Products
-
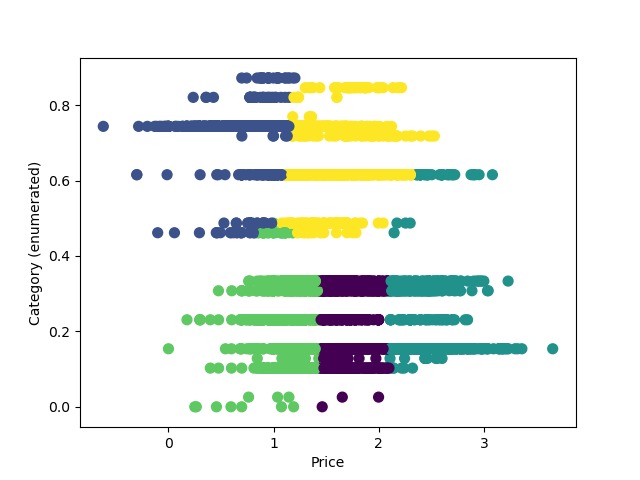
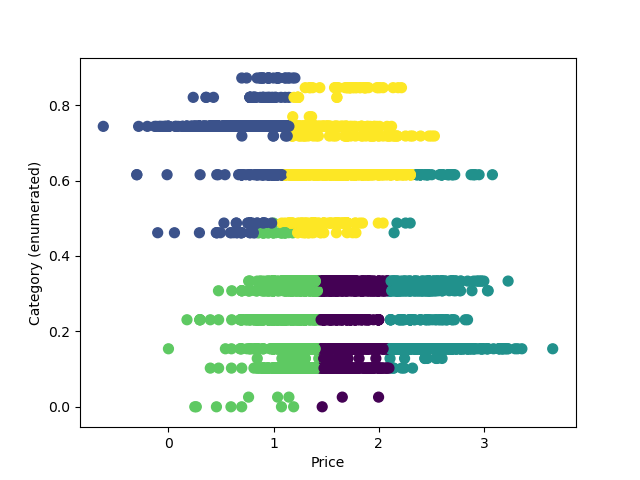
An illustration of K-means clustering by price and category
-
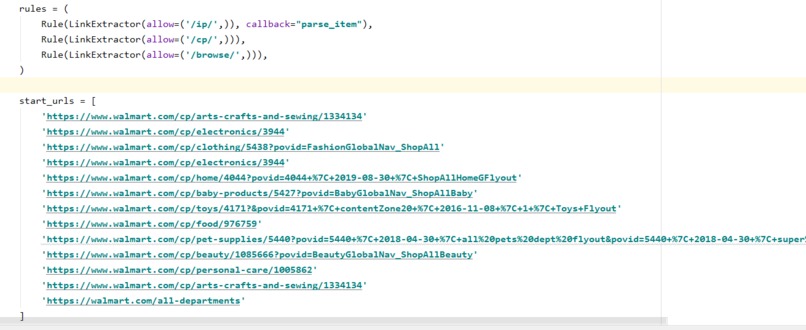
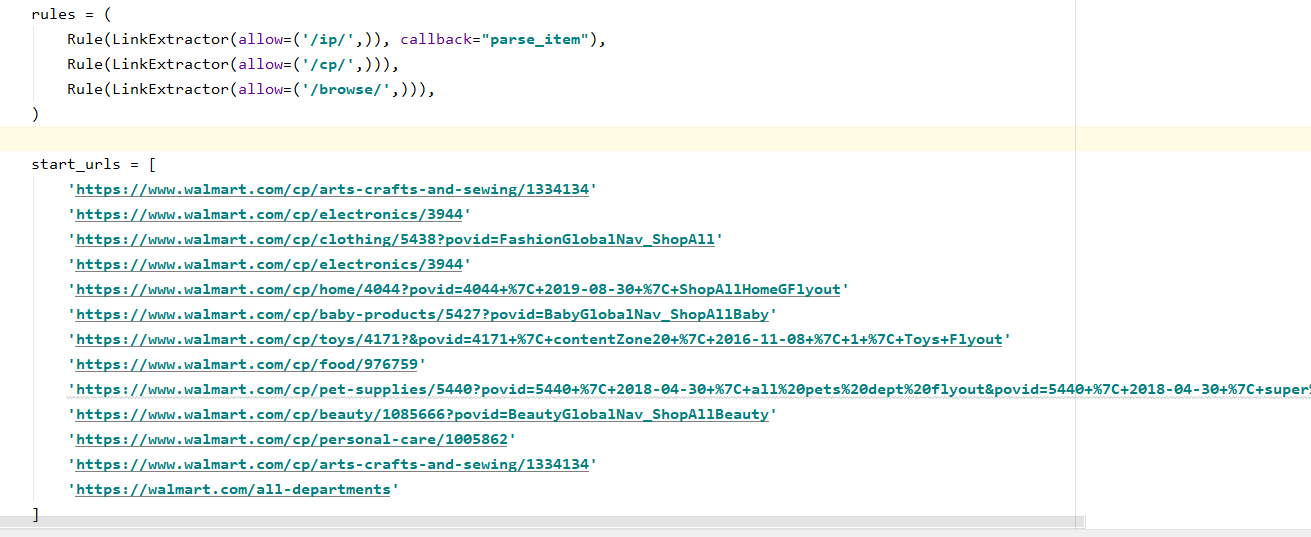
Navigation Rules for Scrapy Webscraper

Inspiration
We were interested by Walmart's problem statement for the 2020 TAMU Datathon and felt that it would provide a great learning experience.
What it does
Give some search query, our front end requests results from our server using websockets. Our server runs NLP analysis, clustering on the products, and a popularity heuristic algorithm to determine the most relevant results.
How I built it
Using a Scrapy web scrawler, we got over 47,000 products from Walmart.com and their information. We then built both a front-end (using Angular) for running searches and a back-end (Python) for executing the searches. The server and client communicate via socket.io requests.
For each product, we use a word2vec library to convert the product name to a 100D vector. We can compute the dot-product between these product vectors and the search vector to determine likeness between the searches and products. We used a pretrained word2vec library with plans to train on our collected data.
We also ran a K-means clustering algorithm based on product price and product category to place products in 100 different clusters. Our search results then prioritize returning results of a similar cluster. This helps to prevent scenarios where products like a "webcam for laptop" reach the top results when a user is just searching for "laptops."
When completed, our server responds and the front end displays the search results.
Challenges I ran into
Web crawling could be difficult as different pages had different formats. We also ran into issues with dynamically loaded pages; because our web crawler did not have user/browser information associated with it, parts of many product pages failed to load and run necessary embedded javascripts.
Developing an accurate heuristic was difficult, as it's hard to judge if a set of search results are good or bad. Additionally, we attempted to run feed the product descriptions into our model, but the language was not as focused as the product titles, yielding lower quality results.
Accomplishments that I'm proud of
NLP, client-server sockets, web crawling, and K-means clustering were all new to us. However, we're proud of the way we embraced researching these topics and figuring out the best way to do certain things. Additionally, we were able to scrape over 47,000+ unique products from Walmart.com and process that data for use in our search engine and UI.
What I learned
We learned a lot about NLP, client-server sockets, web crawling, and the importance of K-means clustering. None of the members on our team had previous experience in these areas, but we were able to use this challenge as a learning experience and personal challenge to develop a solution using new skills.
What's next for Walmart Search Engine
If given more time, we'd train the pre-trained word2vec model further on our data to ensure more accurate searches specific to Walmart and Ecommerce. We would also refine our web crawler to incorporate additional product information from the Walmart website.

Log in or sign up for Devpost to join the conversation.