-
HomePage: Upload pay stubs in seconds — WageShield scans for wage theft, illegal deductions, and overtime violations using AI.
-
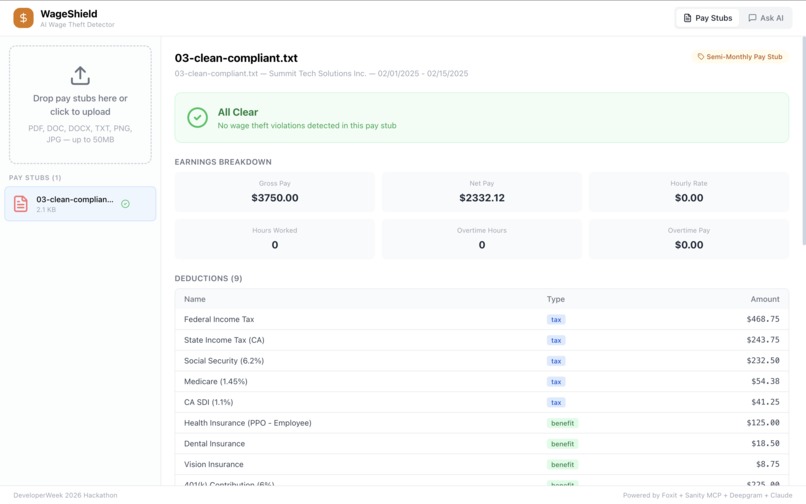
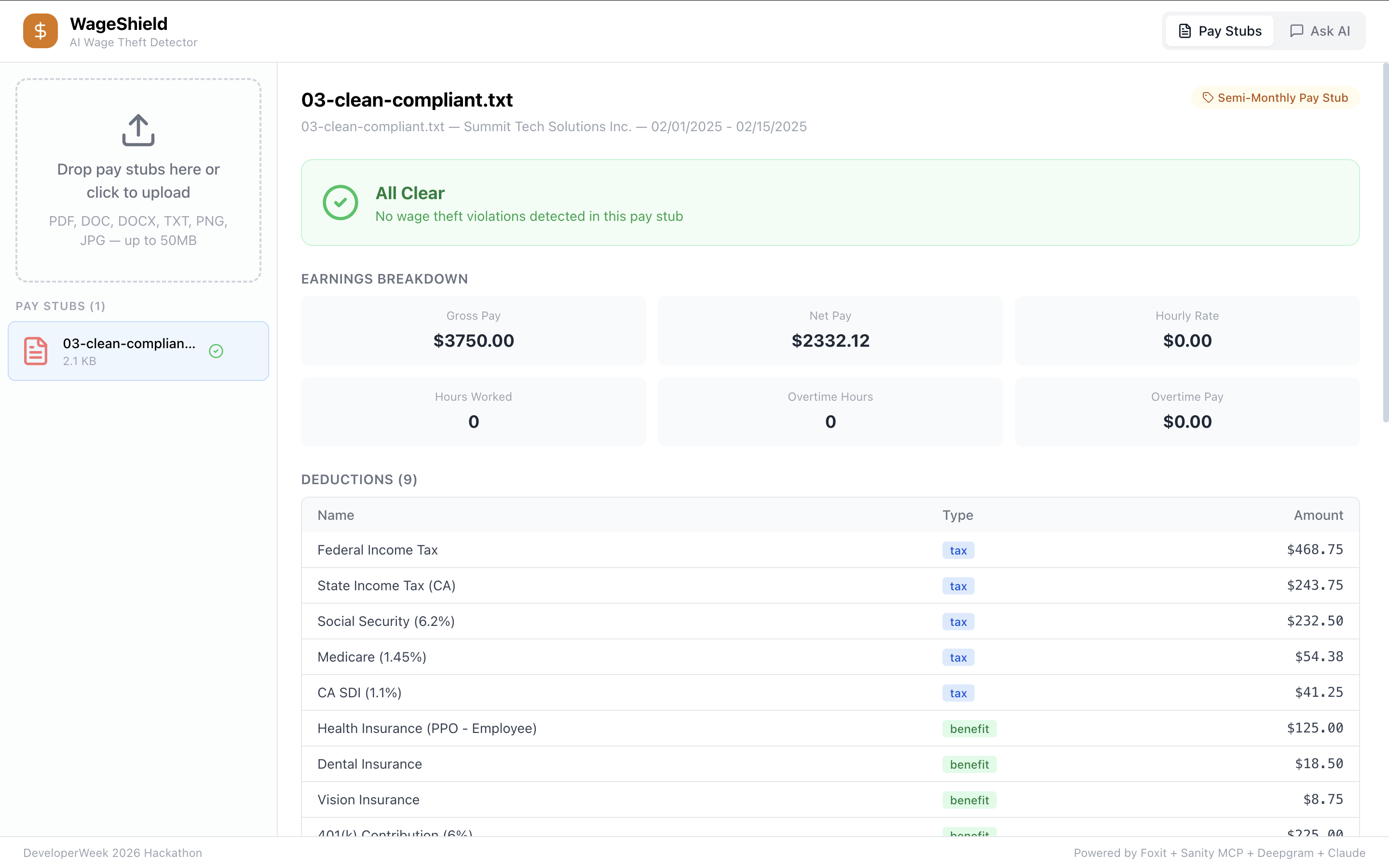
CleanCompliant: All clear — WageShield confirms compliant pay with full earnings breakdown, deductions table, and tax verification.
-
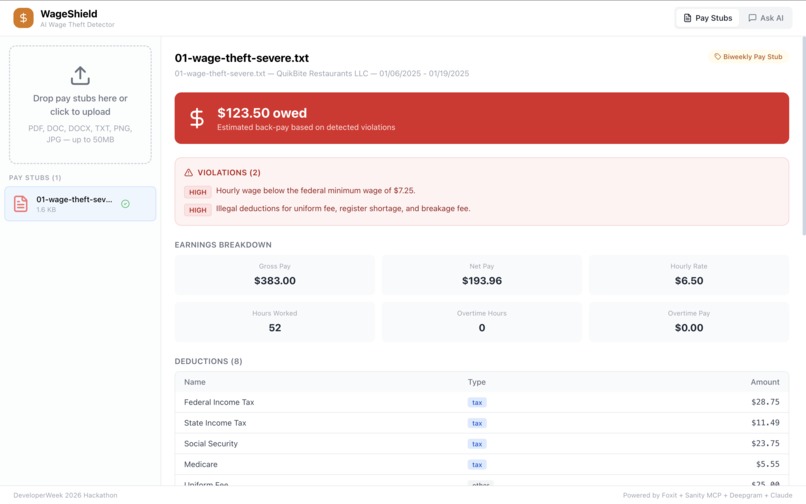
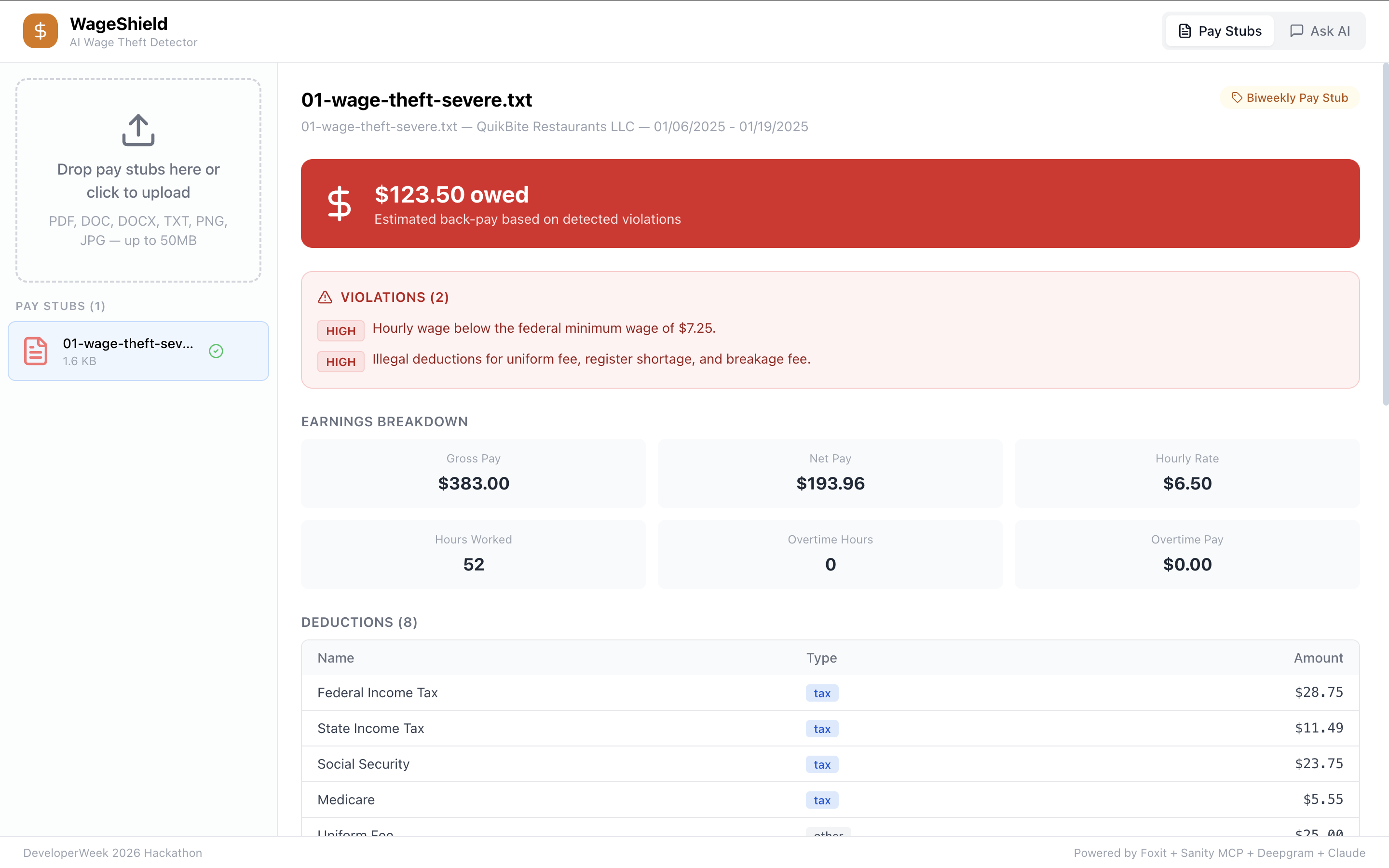
SevereViolation: WageShield flags severe wage theft — minimum wage violations, illegal deductions, and calculates total amount owed.
-
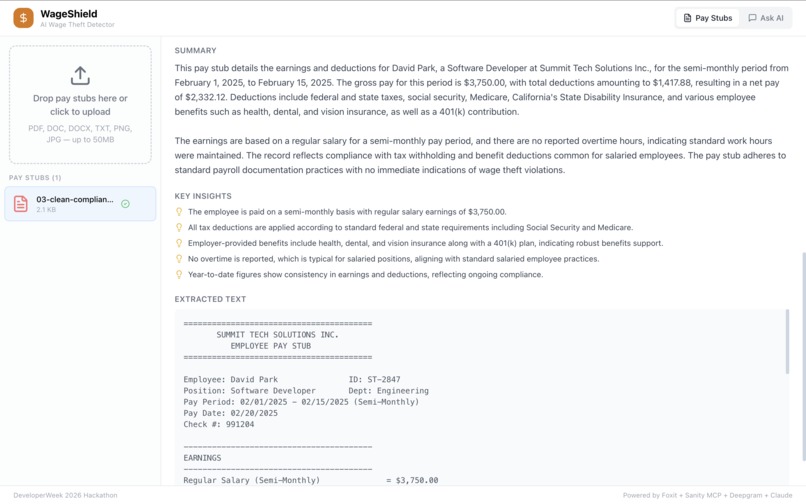
Summary: AI-generated summary with key insights, employer info, pay period details, and earnings at a glance.
-
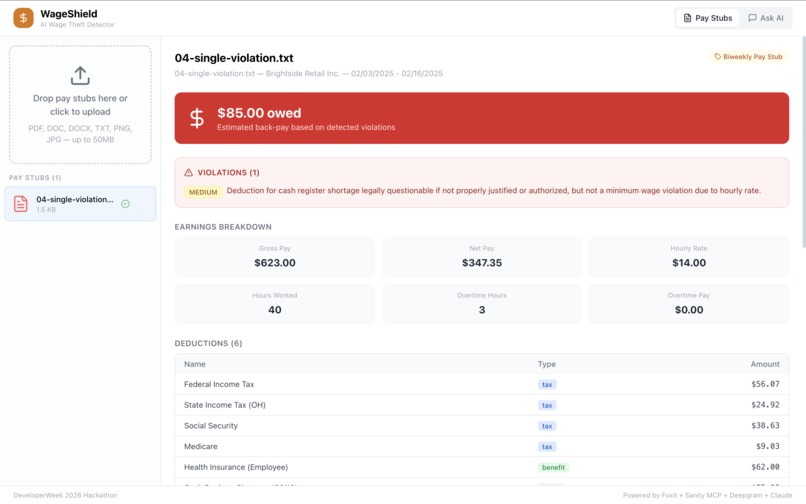
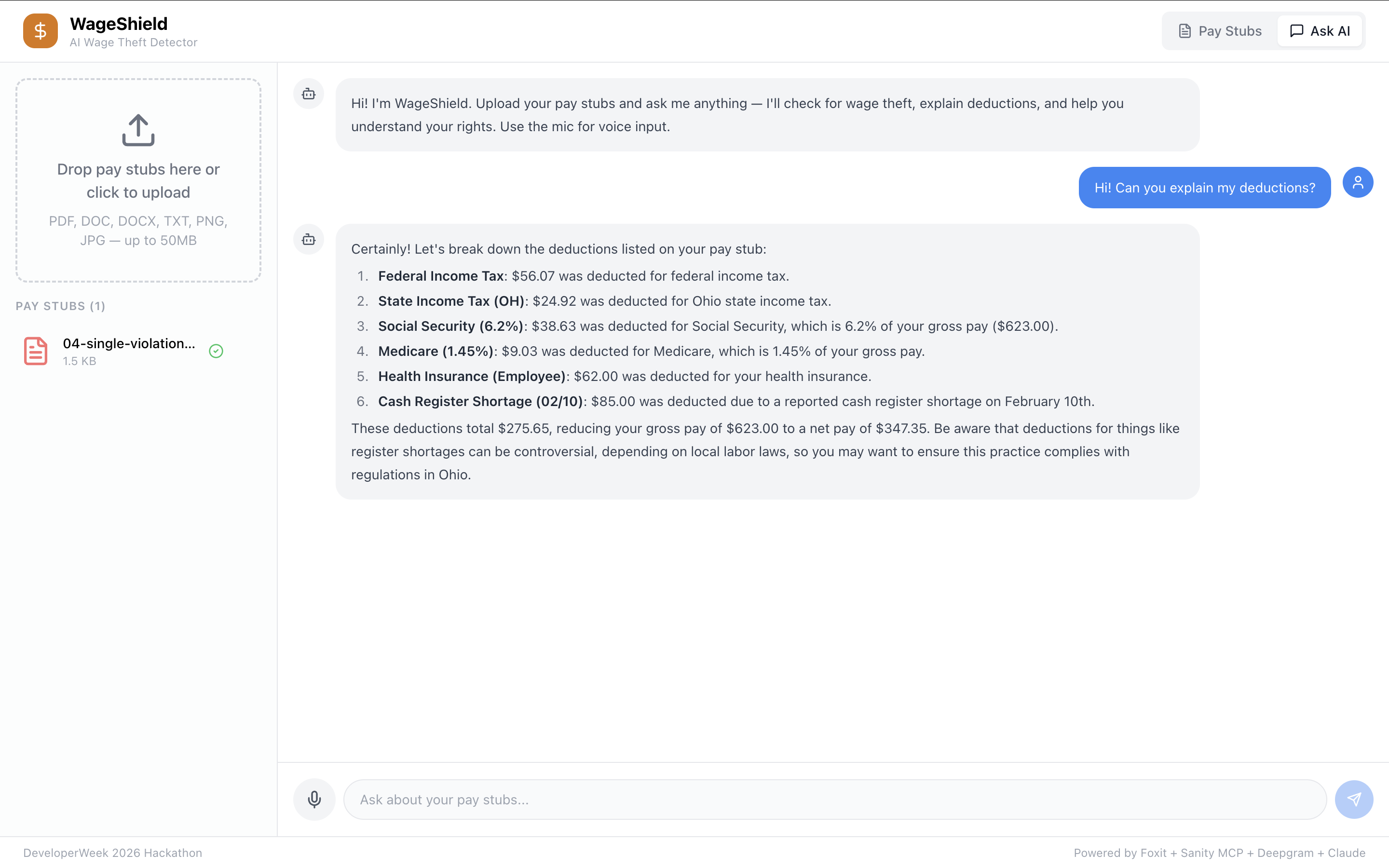
SingleViolation_ASKAI: SingleViolation_ASKAI — Ask about your pay in plain English, get detailed deduction explanations and warnings.
-
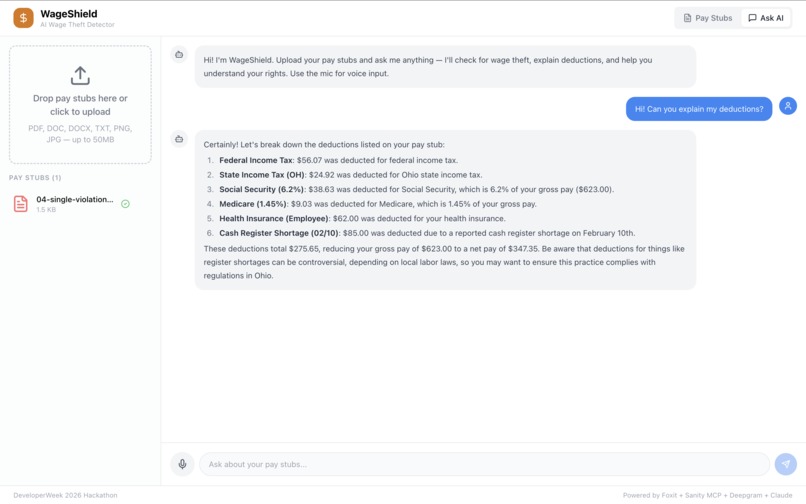
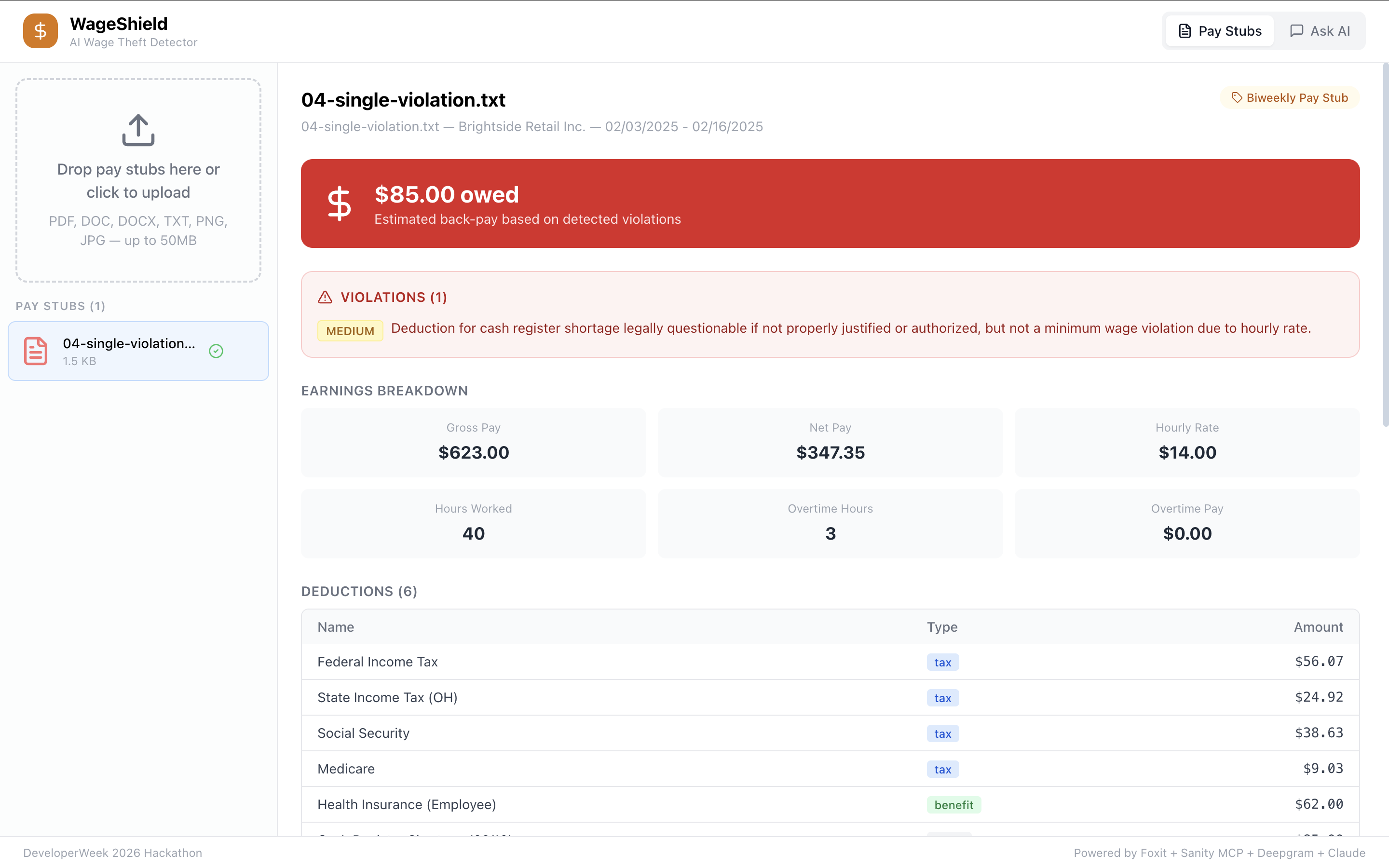
SingleViolation_PaySingleViolation_PayStub — $85 illegal deduction flagged with full earnings breakdown, taxes, and violation severity.

Inspiration
While doing research for a class project, I found out that wage theft costs US workers $50 billion every year — more than all burglaries, robberies, and motor vehicle thefts combined. The people affected most are low-wage workers who don't know their rights or can't afford to fight back. I looked for a free tool that could simply tell someone "your pay stub looks wrong" and there wasn't one. That felt like a problem worth solving at a hackathon.
What it does You upload a pay stub — PDF, image, even a text file — and WageShield runs it through GPT-4o to check for:
- Minimum wage violations — are you being paid below $7.25/hr (or your state's rate)?
- Overtime fraud — worked over 40 hours but didn't get 1.5x?
- Illegal deductions — uniform fees, register shortages, breakage charges that push you below minimum wage
- Tax withholding errors — is FICA actually 7.65%? It breaks everything down — earnings, deductions, violations with severity tags, and an estimated amount owed. There's also a chat where you can ask questions about your stubs, and voice input if you don't want to type.
How I built it
- Backend: Django + MongoDB with pymongo. Went with MongoDB over the Django ORM because pay stubs don't have a consistent structure — some have overtime, some don't, some have tips, etc. A document store made more sense here.
- Text extraction: pdfplumber for normal PDFs. For scanned ones, I added pytesseract + pdf2image as a fallback. Also handles uploaded images (png/jpg) with direct OCR.
- AI analysis: GPT-4o with a long system prompt that has FLSA rules, federal minimum wage, FICA rates, overtime thresholds, and illegal deduction rules baked in. Forces JSON output so I can parse it reliably.
- Frontend: React + Vite + Tailwind. Red banners when violations are found, green "all clear" when the stub is clean. Deductions table with color-coded badges (tax, benefit, employer). Markdown rendering in the chat.
- Voice: Deepgram Nova-2 over WebSocket for live transcription in the Q&A interface.
- Sanity CMS: Syncs analyzed data as structured content.
Challenges I ran into The biggest one was scanned PDFs. pdfplumber handles digital PDFs perfectly but returns empty strings on image-based ones. Took me a while to figure out why some uploads were showing "All Clear" with no data — turns out there was just no text to analyze. Fixed it by checking if pdfplumber gets less than 50 characters and falling back to OCR at 300 DPI. Another headache was getting GPT-4o to return consistent JSON. The first few iterations would return different field names or nest things differently depending on the pay stub. I had to be really explicit in the prompt — showing the exact schema, the exact field types, every possible value. Prompt engineering is underrated. Also spent time dealing with false positives. The AI would sometimes flag 401k contributions or health insurance as suspicious deductions. Had to add specific labor law context to the system prompt so it knows the difference between a legal benefit deduction and an employer taking money it shouldn't.
What I learned
- US labor law is way more complicated than I expected. Overtime rules, tip credits, state minimums, deduction limits — they all interact and the details matter.
- OCR quality depends heavily on scan quality. A production version would need image preprocessing (deskewing, contrast adjustment) before running tesseract.
- Structured output from LLMs isn't free — you have to engineer the prompt carefully and handle fallbacks for when it doesn't comply.
- MongoDB was the right call here. The flexibility of not having to migrate every time I added a field saved a lot of time during the hackathon.
What's next
- State-specific labor law (California, New York, and Texas all have different rules)
- Batch upload to compare pay stubs across multiple periods
- Exportable PDF reports that workers can take to their employer or file with a labor board
- Mobile version — the people who need this most are usually on their phones

Log in or sign up for Devpost to join the conversation.