-
-
Owo-AI - Homepage
-

Reference Signs Page
-
Upload sign and get result

Inspiration
Over 4 million deaf people in Nigeria have almost no AI tools built for them. There is no publicly available Nigerian Sign Language (NSL) dataset, creating a technology gap that leaves the deaf community completely underserved. I wanted to change that. This is honestly just my starting point and I know it’s small compared to the problem, but I had to start somewhere.
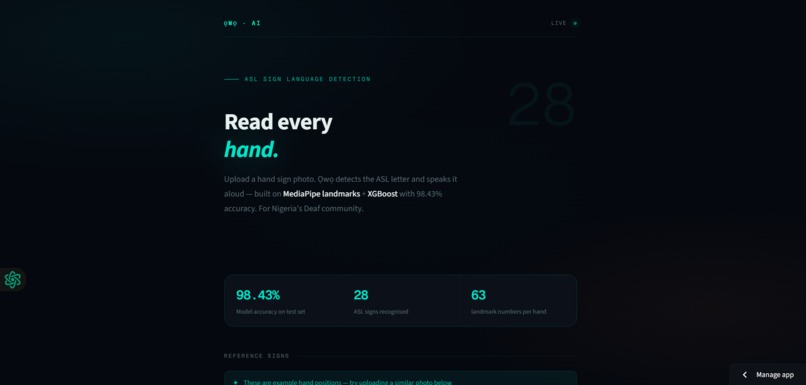
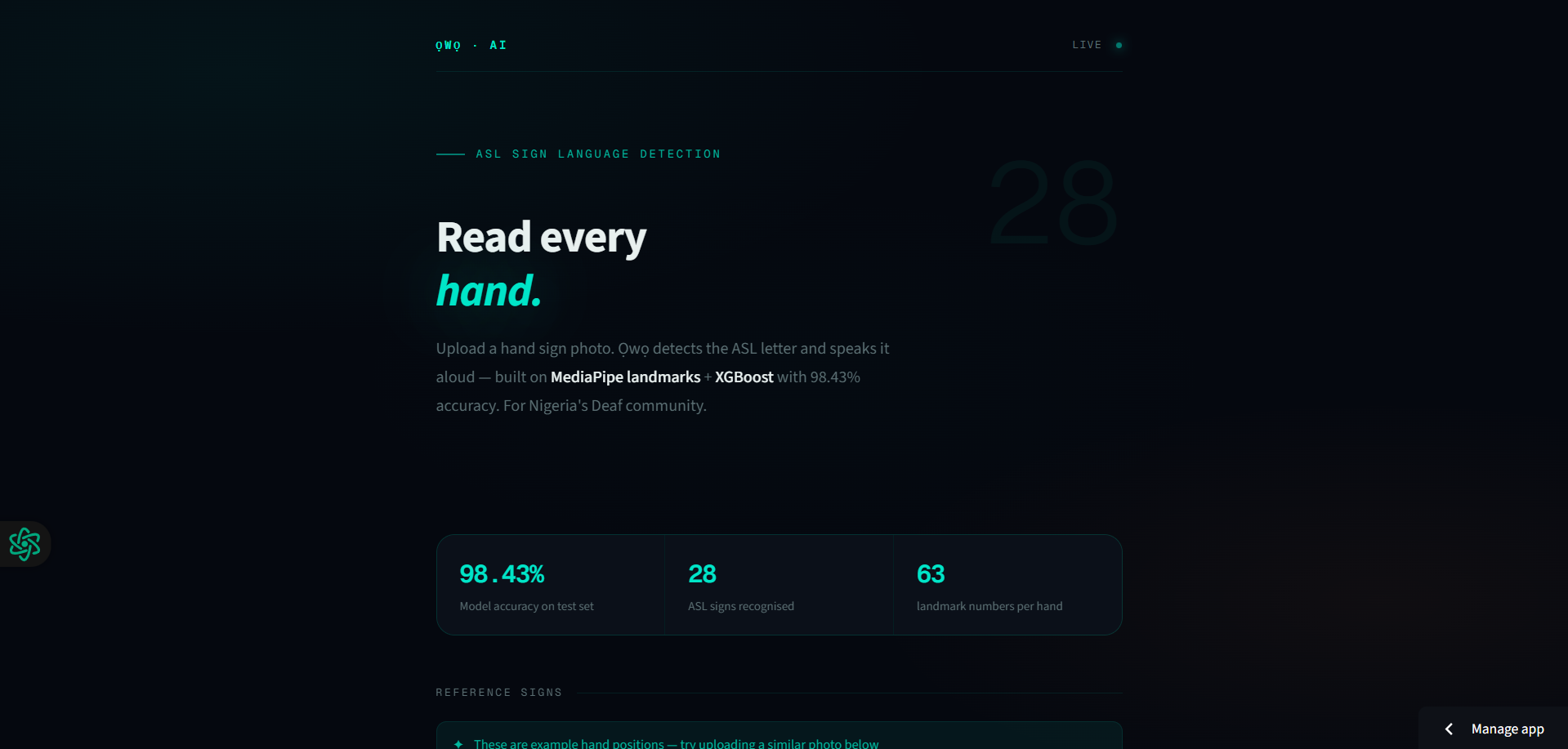
What it does
Ọwọ-AI is a real-time ASL sign language detector built for Nigeria's deaf community. It detects 28 hand signs (A-Z + space + del) from a photo or webcam feed using MediaPipe hand landmarks and XGBoost. Instead of training on raw pixels, it extracts 21 hand keypoints, 63 numbers per image and classifies the hand shape. It achieves 98.43% accuracy and works across skin tones, including dark skin tones 🤚🏾
Try it live at owo-ai.streamlit.app
How we built it
- Downloaded the ASL Alphabet Dataset - 87,000 images across 28 classes.
- Used MediaPipe HandLandmarker to extract 21 keypoints per image (63 features).
- Normalized landmarks by subtracting the wrist position and scaling by hand size, so the model learns hand shape, not size or position.
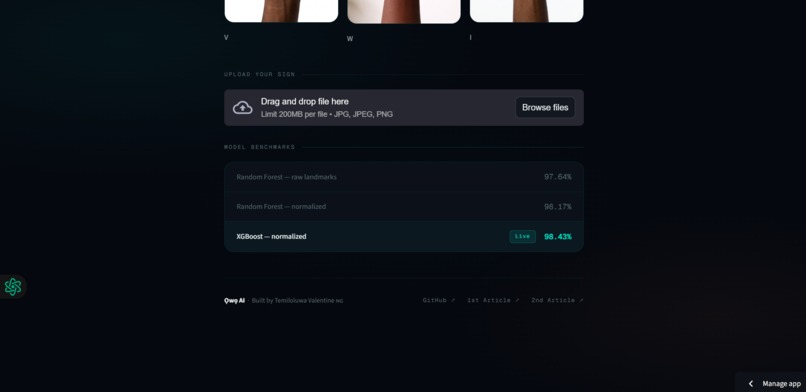
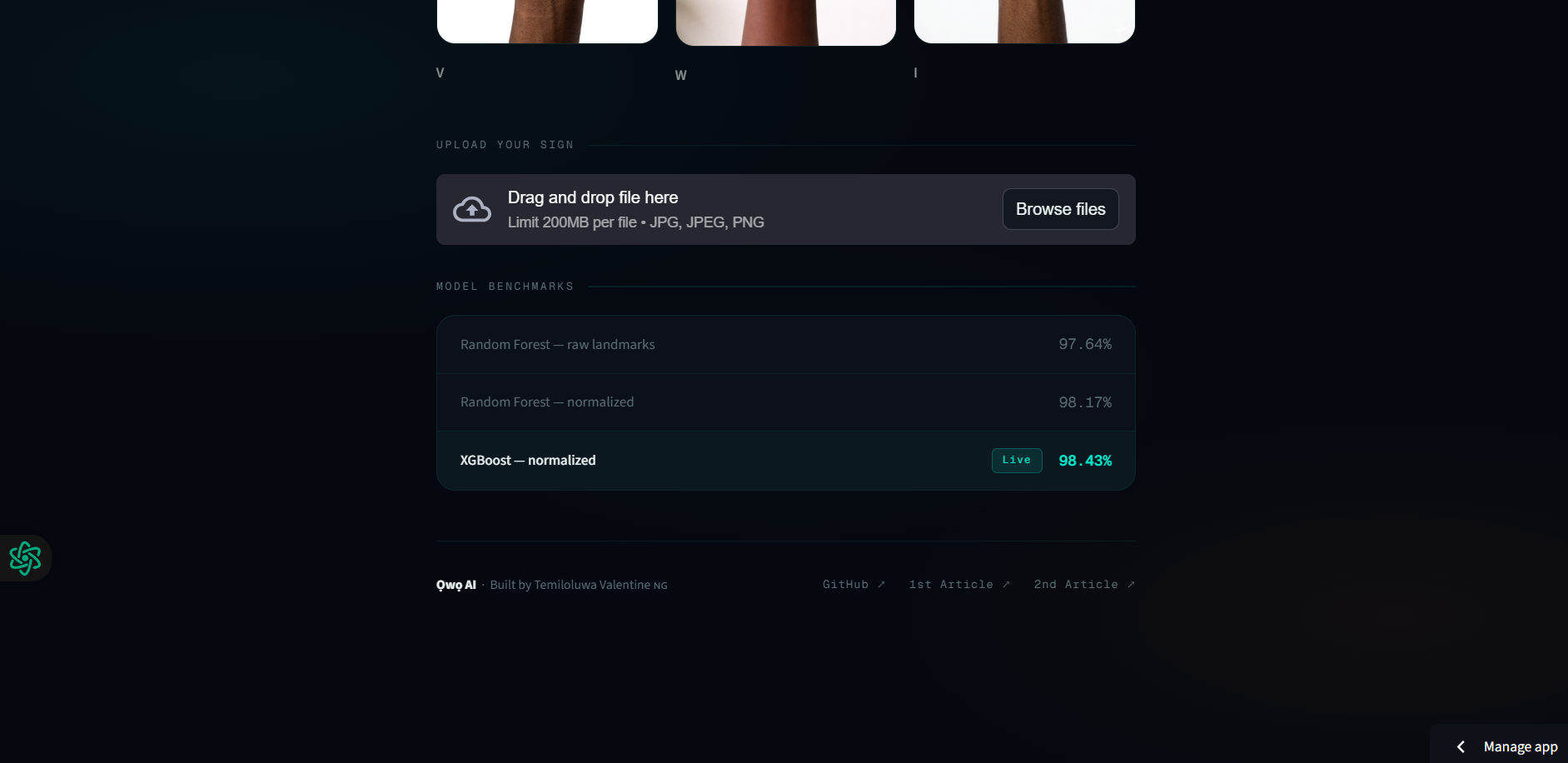
- Trained and compared three models:
- Random Forest on raw landmarks → 97.64%
- Random Forest on normalized landmarks → 98.17%
- XGBoost on normalized landmarks → 98.43% 🏆
- Deployed as a Streamlit web app which is accessible to anyone with a browser.
Challenges we ran into
- Lack of Nigeria Sign Language Dataset, so i had to use the American Sign Language Dataset (ASL).
- MediaPipe 0.10+ completely changed its API, I had to rewrite the entire extraction pipeline from scratch.
- ~24% of images had failed landmark detections due to awkward angles and poor lighting.
- Getting normalization right so the model generalizes across different hand sizes and distances from the camera.
- MediaPipe native library couldn’t load on Streamlit Cloud (usually Python/wheel compatibility), so i forced a compatible runtime by adding runtime.txt (Python 3.11.9) and pinned mediapipe==0.10.14 in requirements.txt.
Accomplishments that we're proud of
- 98.43% accuracy across 28 classes without a single CNN or GPU.
- I specifically tested this on darker skin tones (including mine), because most models fail here and it actually held up.
- Letters with distinct shapes like B, C, L, Y, Z, I, J, achieve near 100% confidence.
- Full pipeline open sourced - code, model and two technical articles published.
- Deployed as a live web app anyone can try without installing anything.
- Built entirely by one person as a starting point for Nigerian Sign Language AI.
What we learned
- Landmark-based models generalize across skin tones better than CNNs because they learn geometry not pixel color.
- Normalization is not just preprocessing, it fundamentally changes what the model learns.
- XGBoost consistently beats Random Forest on structured tabular data like landmark coordinates.
- Letters with similar curled finger positions (M/N, A/X, E/S) are genuinely hard even for humans, the confusion matrix confirmed this.
- I didn’t expect this, but building in public actually got a sign language AI startup to reach out to me.
What's next for Ọwọ-AI
- Collect a native Nigerian Sign Language (NSL) dataset with the deaf community.
- Add temporal modeling with LSTM for word and sentence level detection.
- Deploy as a mobile app, lightweight enough to run on any smartphone.
- Partner with deaf schools in Nigeria for real-world testing and feedback.
- Benchmark formally against CNN-based approaches.
- Expand beyond the alphabet to full NSL vocabulary.
Built With
- mediapipe
- numpy
- opencv
- pandas
- python
- scikit-learn
- streamlit
- webcam
- xgboost


Log in or sign up for Devpost to join the conversation.