Inspiration
If you are a DevOps engineer, you know the nightmare: it's 3:15 AM, your phone starts buzzing, and you are dragged out of bed because a node in us-east-1 is dropping packets. You groggily SSH into a server, stare at Grafana charts, and manually reroute traffic to a fallback cluster. Then you write a post-mortem.
The inspiration for Vyuha AI was born out of frustration with this exact cycle. We realized that in a world of 99.9% SLAs, the remaining 0.1% hurts the most. Traditional tools are essentially just expensive dashboards-they tell you what broke, but they put the burden of figuring out what to do onto the human. We wanted to build an Autonomous SRE that could detect the failure, reason through the architecture, and propose the exact fix before the engineer's phone even rings.
What it does
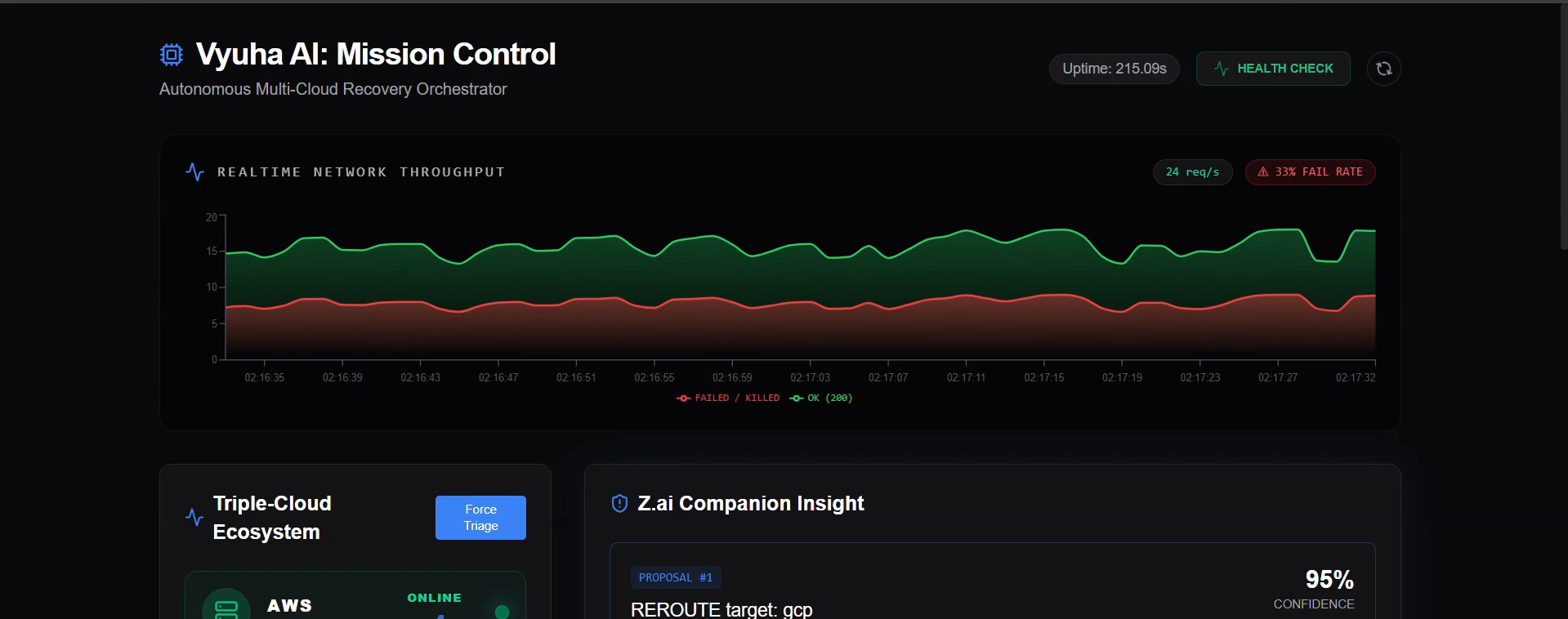
Vyuha AI is an intelligent Triple-Cloud Mission Control. It monitors mock nodes across AWS, Azure, and GCP in real-time behind a dynamic reverse proxy. When a failure occurs-and we've built a Chaos Lab to simulate Hard Kills, Flaky connections (25% packet drop), or 1.5s Latency spikes-the Z.ai Companion, powered by GLM-5.1, activates instantly.
Instead of just alerting you, the agent parses the failure, assesses the severity, and figures out how to dynamically rebalance the traffic payload among the surviving nodes to prevent cascading failure. It then generates a structural failover plan.
Crucially, it uses a Human-in-the-Loop model. The AI explains its reasoning step-by-step and waits. Once the operator clicks "Approve," the orchestrator physically applies the new proxy formation, isolating the dead node and restoring full uptime with zero manual terminal commands.
How we built it
We built Vyuha AI using a robust split-stack architecture:
The Brain (Control Plane): A Python FastAPI backend that acts as the orchestrator. It runs the continuous monitor loop, evaluates state changes, and interfaces with the ZhipuAI GLM-5.1 API for long-horizon triage reasoning.
The Body (Infrastructure): A custom-built async reverse proxy that actually respects the AI's formation changes, alongside three mock cloud instances and a load generator running parallel traffic tests.
The Face (UI): A dark-mode, neon-styled Next.js 14 dashboard utilizing Recharts and Framer Motion for a high-impact, real-time visualization of network throughput and chaos experiments.
The Memory (Storage): A local SQLite database managed via
aiosqliteto store incident records, proposals, and learnings.
Challenges we ran into
The Infinite Triage Loop:
When the LLM detects a node is dead, it proposes a fix. But after the human approved the fix, the node itself was structurally still "dead" while it recovered. This initially caused the orchestrator to keep seeing the dead node every 5 seconds and triggering new incidents. We had to build a complex state-machine lifecycle (DETECTED -> PROPOSED -> APPLIED -> REFLECTED) so the agent knew to suppress alerts while a fix was actively "Monitoring Recovery."
Type-Safety vs. Chaos:
We lost several hours to a silent Pydantic validation bug because our React chaos buttons were emitting "flaky", but the backend strictly demanded the enum "FLAKY". It was a great lesson: LLMs are intelligent, but bridging unstructured AI output with strict frontend-to-backend API contracts requires bulletproof data parsing.
Accomplishments that we're proud of
Evolutionary Memory Logging: We built a feature where the AI learns from its own history. Every time an operator approves or rejects an AI proposal, the system runs a secondary "Reflection Phase" to extract a lesson (e.g., "When AWS fails with an intermittent packet drop, rerouting immediately to Azure is effective"). The next time an incident occurs, the orchestrator pulls these specific lessons from SQLite and injects them into the GLM prompt, preventing the AI from making the same mistake twice.
Real-Time Chaos Metrics: Rewriting our load-tester so that it probes all three cloud clusters in parallel, allowing the dashboard's Traffic Graph to instantly react and display "Fail Rate %" badges the very second a user injects a chaos experiment.
What we learned
We learned that building "Agentic UI" is incredibly difficult. You are no longer just rendering static database tables; you have to design user interfaces that communicate reasoning, confidence, and uncertainty.
We also learned the incredible power of the GLM-5.1 model. Its ability to take a raw technical spec (e.g., node response times, active routes) and output a perfectly formatted JSON formation change while accurately diagnosing a "503 Packet Drop" was exceptional.
What's next for Vyuha AI
Moving forward, we want to bring Vyuha AI closer to real-world production readiness:
Slack/PagerDuty Integrations: Bringing the "Approve/Reject" buttons directly into ChatOps where engineers already live.
Auto-Rollback Systems: Giving the AI the ability to undo its own formation change if it detects that the failover actually made network latency worse.
Fine-tuning: Training a specific GLM model strictly on an enterprise's historical incident post-mortems so it automatically understands proprietary company runbooks.
Built With
- docker
- fastapi
- github
- glm
- javascript
- next.js
- python
- react
- render
- sqlite
- tailwind-css
- typescript
- vercel
- zhipuai

Log in or sign up for Devpost to join the conversation.