Vyra
Multi-model AI code generation platform. Describe a project and watch as models compete to build your vision.
Inspiration
As computer science students using generative AI models to accelerate the programming process, we have questioned which models would be the cheapest and best to use for specific tasks. After watching a YouTube video comparing Mario games built by Claude and Gemini, we wondered: what if your IDE could do the same? Compare models side by side and let you pick the best output yourself.
What it does
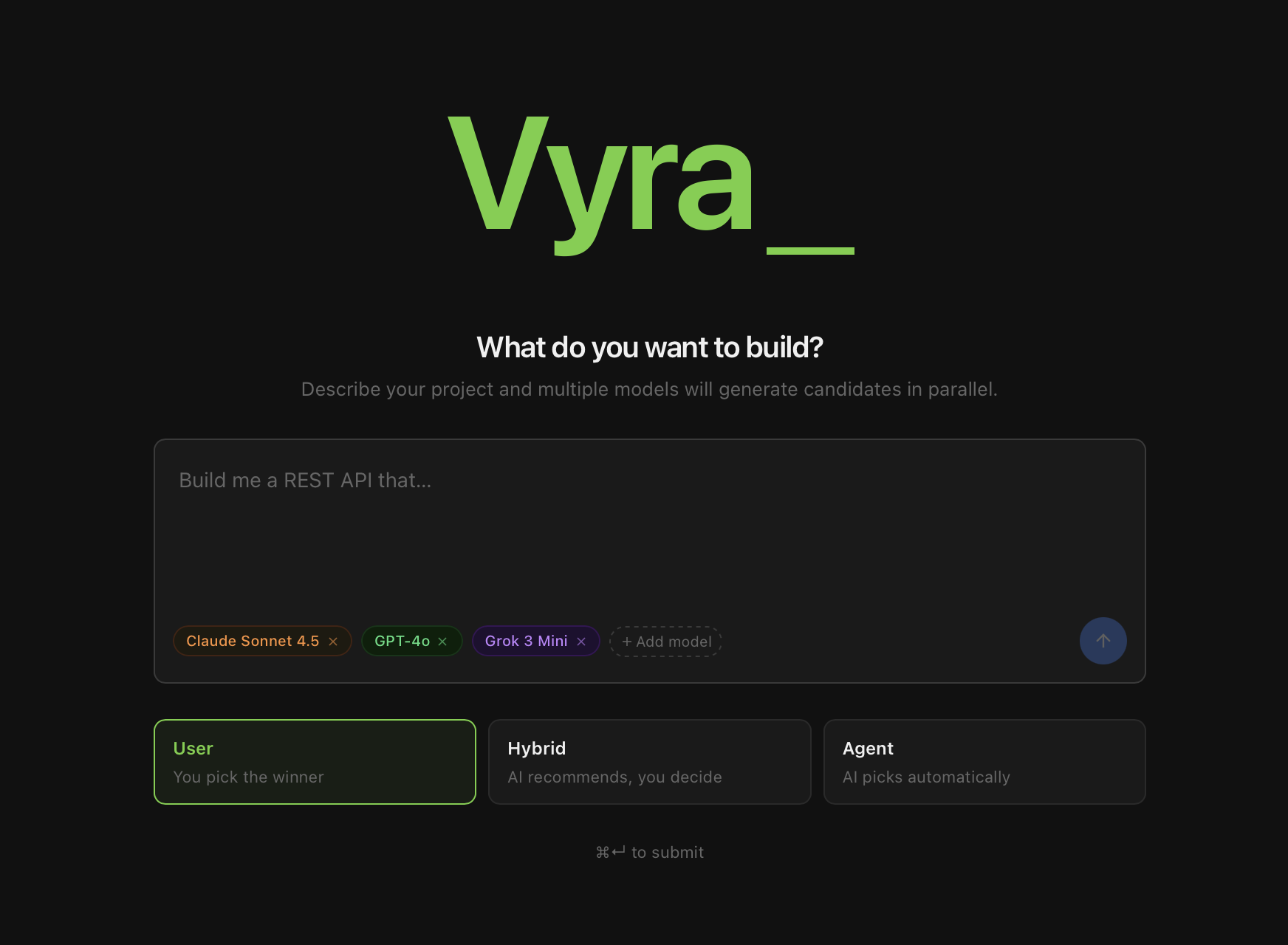
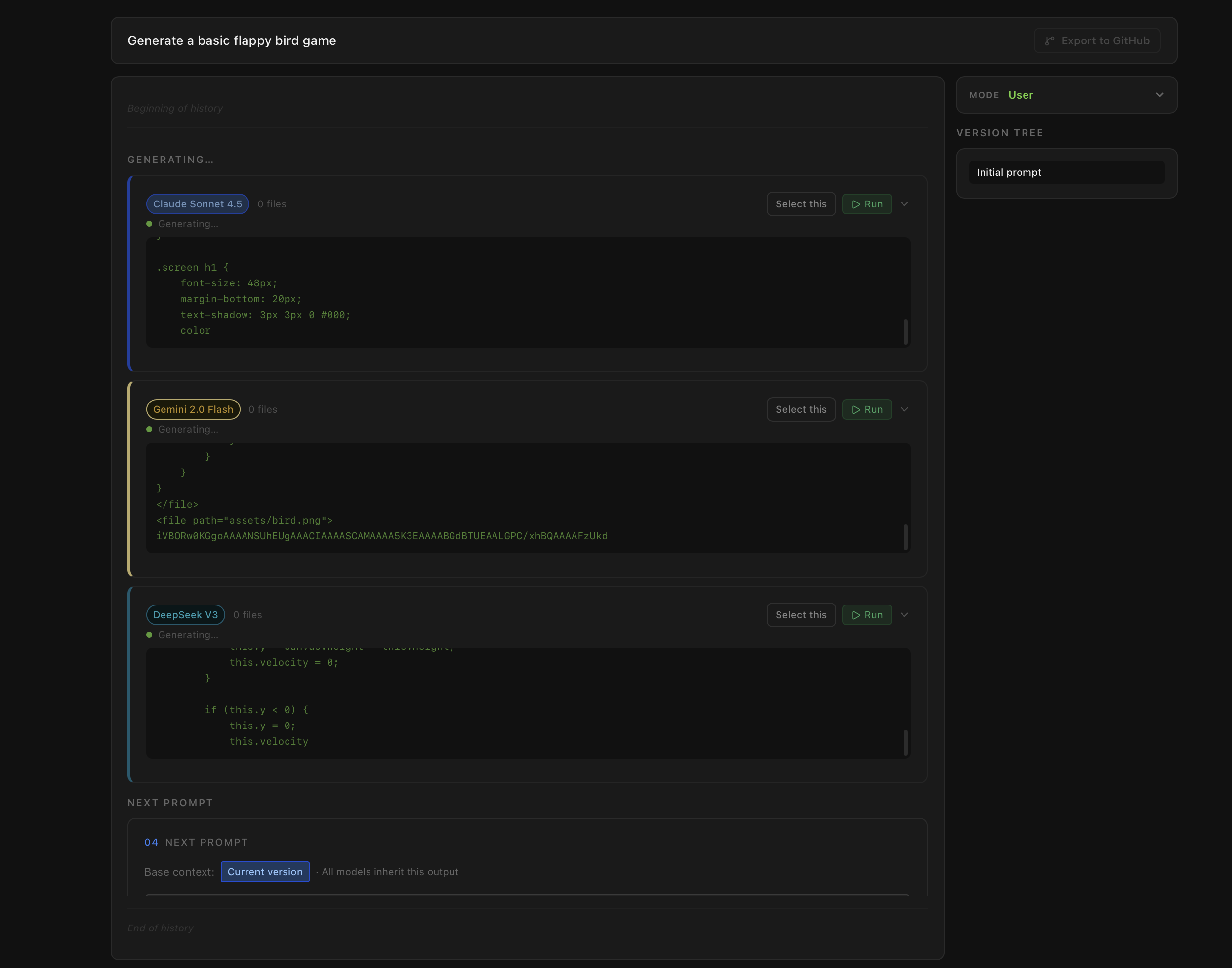
Vyra is a web-based IDE that is fully powered by and able to run AI agent code. Just by writing a prompt, anyone can write a fully functioning program by picking and choosing between several different agents that write their program code in parallel, iterating through whichever versions they like, until they are satisfied with the project.
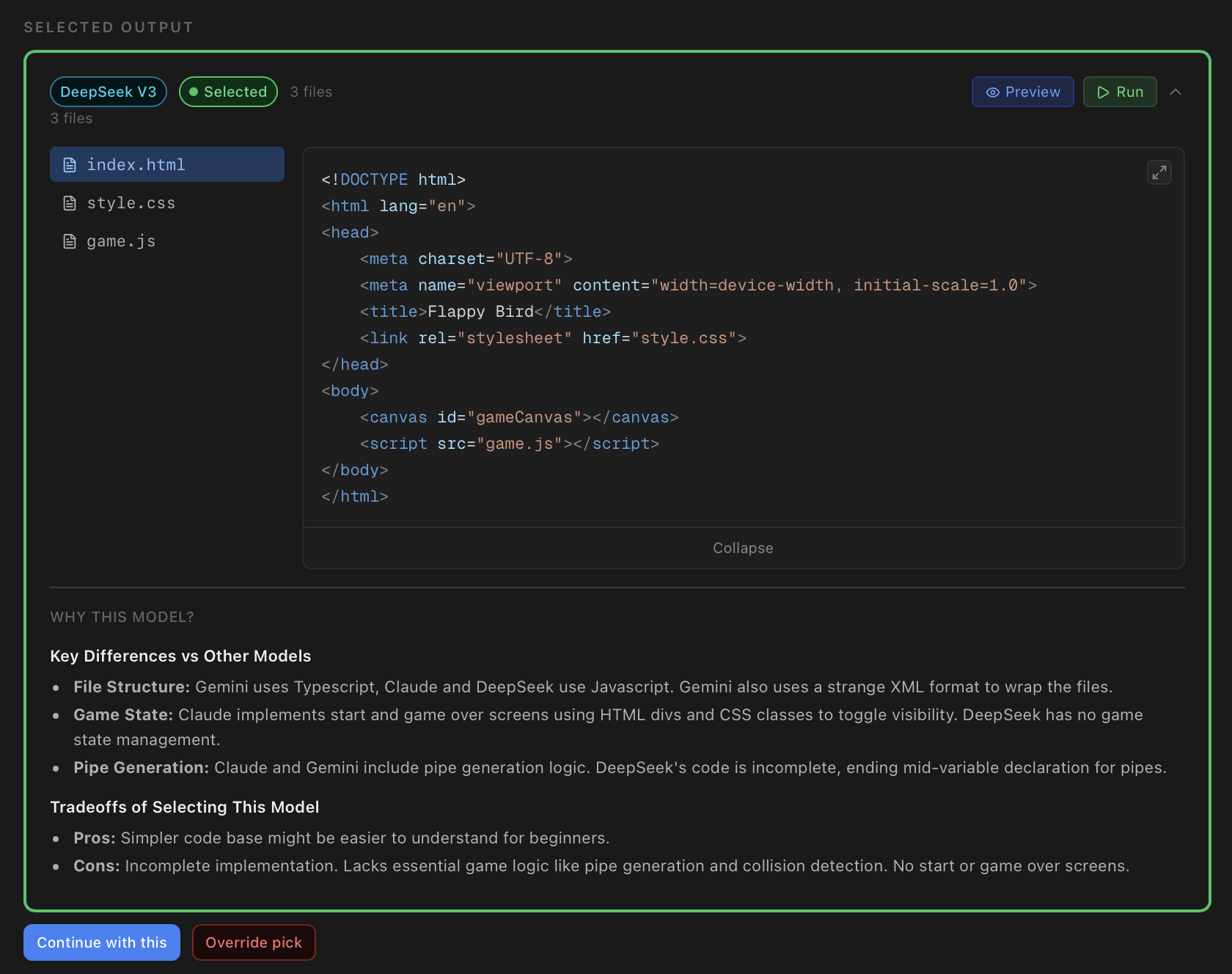
The user has complete control over customizability. They can preview code, see overviews of what programs do and how they work, and use previous iterations of their code as a basis for what should come next. If they prefer a more hands-free approach, they can simply turn on "Agent Mode" and take a break while the evaluator AI performs the comparisons and iterations autonomously.
How we built it
We built Vyra as a multi-model code generation and comparison platform. Users can query prompts, and Vyra will send it out to multiple LLMs simultaneously via OpenRouter. We utilized Gemini 2.0 Flash for the "evaluator" of the model responses following a strict rubric rather than an objective goal, providing an additional confidence score.
There are three modes of operation:
- User Mode: only the user is able to select the model, with assistance from the evaluator if necessary
- Agent Mode: fully automated system where the selected model is chosen by the evaluator
- Hybrid Mode: agent makes the decisions unless faced with unclear situation
Challenges we ran into
We ran into various challenges, both technical and non-technical, throughout the event. There were many features we wanted to include, thus many unfamiliar technologies and libraries we would have to interact with. One such technology was Piston, a sandbox code runner used to preview and compile code locally within your browser. It took many hours getting it set up and working with certain file types (.py, .html, etc.). Additionally, we faced UI/UX design challenges, with a unique layout due to the multi-model functionality. Although we had all used LLMs extensively in the past, it was unclear of how to efficiently display them all together without overloading the user with information.
Accomplishments that we're proud of
This was the first ever hackathon we had been a part of where we faced 0 git problems. In the past, whether it be disregarding merge conflicts, blindly pushing code, or lack of code reviews, our team would constantly face issues left and right related to git, draining us of a lot of time. However, our new mindset for this event (git branch + issues, Claude code reviews, and strong communication) allowed us to traverse through git safely and efficiently.
We're also really proud of cleanly grasping all of the technologies we used, both old and new. For example, MongoDB was something many of us hadn't used in years, but this project served as a refresher of the technology itself and how much it's changed since then, along with many of the other ones we used. Additionally, we were able to deploy it safely and confidently, allowing us to share the project with friends to try out and see how different people use it in different ways.
What we learned
Obviously by spending so much time utilizing multiple LLMs at once, we got the chance to see how different agents compare with each other directly. For each prompt we queried, we saw how different LLMs approached the same problem, their interpretations of UI/UX designs, and also the speed and efficiency of it. It was never the same, and not only did it teach us that we can't just blindly use one singular LLM because it's "objectively better" but also that quantity can sometimes equal quality.
What's next for Vyra
Vyra currently supports an arsenal of very "rudimentary" LLMs that aren't as powerful as many of the most up-to-date models. This is largely due to funding, as we aren't able to afford such expenses... yet. We're hoping that with your support, we'll be able to bring the very best models out there to Vyra and elevate the quality of each output to the next level. We also want to be able to show the user just how much time they might be saving, how many credits they might be saving, and how much better the final result is by using Vyra compared to a single other LLM. Ultimately, we want Vyra to be as universal, as user-friendly, and as adoptable from any other AI, helping its users play a larger role in perfecting their project while retaining the efficiency from LLM usage.
Built With
- docker
- fastapi
- mongodb
- next.js
- nextauth.js
- openrouter
- python
- react
- tailwind
- typescript
- uvicorn
- zed
- zod
- zustand






Log in or sign up for Devpost to join the conversation.