-
-
Protecting users from the shadows of vulgarity

Inspiration
The inspiration comes from need of online safety, community standards, mental health, legal and ethical violence's and growing vulgarness among youth. Time to eradication and tackle this type of social community issue.
What it does
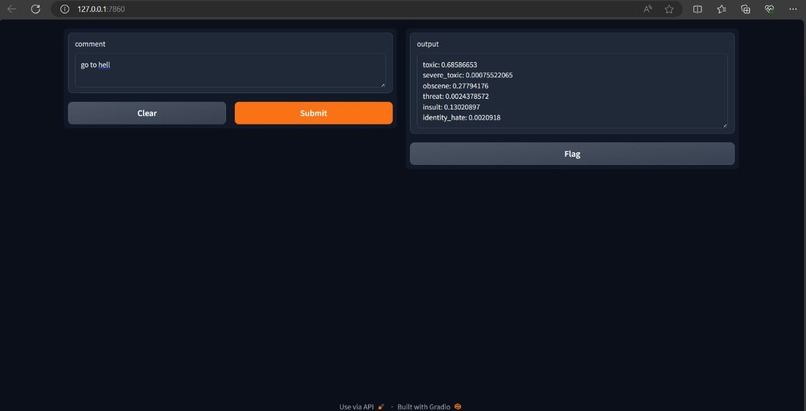
Its basically deep learning model with GUI created using "gradio".It takes input as text from user and then on basis of trained "model.h5" it predicts 6 right feature values (toxic, severe toxic, obscene, threat, insult, indentity_hate).In simple words it predicts and output vector or array.
How we built it
For the project, we have used Python language, Jupyter Notebook, Python frameworks and libraries like tensorflow, keras, nltk, itertools etc. The dataset of 160000 data points was taken, which is further divided in 70% training,10% testing,20% validation set. Data preprocessing is done by "clean_text" function, which rewrites misspelled words, converts text to lowercase and removes space. The NLP requires Text Vectorization for model training, so its done. Then we train the model with Sequential model and LSTM, Bidirectional, Dense, Embedded etc. layers for 10 epochs. Then we check Precision, Accuracy, Recall of model for evaluation purpose. Finally model is saved ready to use. We deploy model using gradio app api. The image of the gradio is added in below.
Challenges we ran into
Overfitting of model- When we were not shuffling the dataset and no batches were made the issue of overfitting occurred. But it was later resolved. Training of model- Creation of model in local environment is somewhat though as we are unable to run more epochs, because of no GPUS. Also, we have tried for 10-20 epochs, but after calculation we get to know that 100-150 epochs will give accuracy between 85-90% which high for deep learning model. Choice of dataset and changing datapoints- The dataset size is large enough. We also added comment text so as to get proper accuracy and recall.
Accomplishments that we're proud of
We are proud of several achievements throughout the development of this project. Firstly, Our deep learning model demonstrates a significant capability in understanding and identifying various forms of vulgar behavior online. The accomplishment of training a model with high precision and recall, despite limitations in computational resources, speaks volumes about the robustness of the architecture and the quality of the dataset we curated. Secondly, we successfully integrated a user-friendly GUI using Gradio, making our solution accessible to users with varying levels of technical expertise. This democratization of AI tools is a step toward broader adoption and impact. Finally, the hands-on experience gained in handling and preprocessing a large-scale dataset, and applying advanced NLP techniques like LSTM and Text Vectorization, has been immensely educational and fulfilling.
What we learned
Through the journey of creating the Vulgar Chat Detection on Social Media project, we dove deep into the complexities of Natural Language Processing and emerged with a wealth of knowledge. Our experience taught us the intricacies of LSTM networks, which proved indispensable for interpreting the subtleties of human language in our text data. We honed our skills in data preprocessing, understanding that the meticulous process of tokenization, lemmatization, and stop word removal is crucial for refining input data and enhancing the model's predictive power. We encountered the ubiquitous challenge of overfitting and learned to navigate it by implementing strategies like dataset shuffling and batch processing, ensuring our model remained robust and generalizable. Perhaps most importantly, we learned to be resourceful with our computational resources. Limited by the absence of high-end GPUs, we optimized our training procedures, achieving commendable model performance within these constraints. This experience underscored the importance of resource optimization and opened our eyes to the potential of cloud computing for future projects.
What's next for Untitled
Moving forward, we aim to expand the reach and utility of our project in several ways. The immediate goal is to deploy the model on a live server, ensuring consistent uptime and scalable access to users. Integration with social media platforms is another critical step, where we plan to collaborate with platform developers to embed our model within the existing content moderation workflows. Moreover, to address a global audience, we are exploring ways to add multi-language support, thereby widening the impact of our tool across diverse linguistic demographics. The continuous evolution of language and slurs presents an ongoing challenge, and thus, we are also looking into implementing a real-time learning mechanism to adapt to new patterns of vulgar expression. This would help in maintaining the relevance and efficacy of our model over time.
Please note that gradio link provided below will vanish after 72 hrs.If needed we can provide you the link for same.

Log in or sign up for Devpost to join the conversation.