-
-

Cover Photo
Inspiration
Every minute a self-checkout lane is down costs retailers revenue, frustrates customers, and burns out store associates. The problem isn't a lack of data — retailers already collect transaction logs, latency readings, and error events. The problem is that nobody sees the pattern until a line is already forming and a customer is already at the service desk complaining.
We kept asking ourselves: why is the store manager always the last person to know? Existing tools are reactive. They tell you a lane failed after it failed. We wanted to build something that gave managers a 1–4 hour warning, told them exactly what was wrong in plain English, and walked them through the fix — without ever taking autonomous action on a live lane.
That's how Voyix Ops Companion was born.
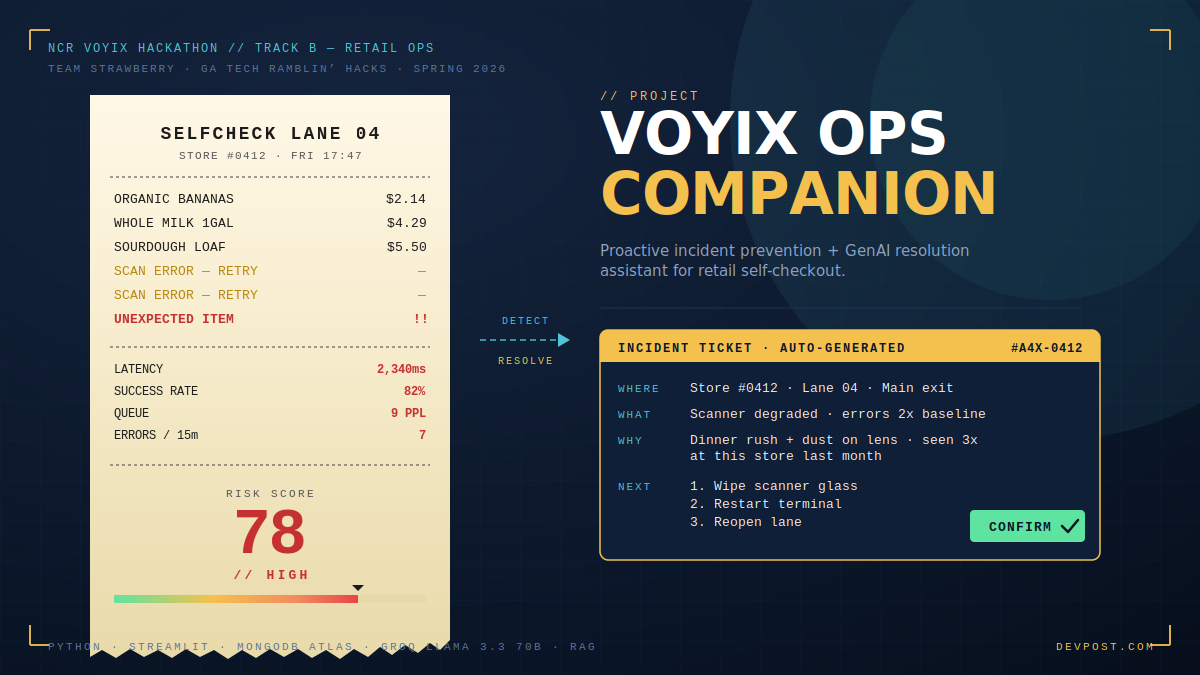
What it does
Voyix Ops Companion is a proactive incident prevention and GenAI resolution assistant for retail self-checkout operations. It has four pieces that work together:
- Risk Scoring Engine - generates a 0–100 risk score for every self-checkout device, updated continuously from five operational drivers: latency, success rate, decline rate, error count, and queue length.
- Auto-Generated Incident Tickets - when risk crosses 60, the system creates an incident card containing the location, root cause analysis, top drivers, numbered next steps, and a human-in-the-loop confirmation flag.
- GenAI Chat Assistant - a RAG-powered conversational interface built on Groq's Llama 3.3 70B. Managers can ask three core questions: What's happening?, What should I do now?, and Why are you recommending this? - and get grounded, data-backed answers in 2–5 seconds.
- Manager Dashboard - Streamlit-powered visualizations of risk trends over time, top risk drivers across stores, highest-risk locations, and live ticket status, filterable by city and store ID.
How we built it
Data Pipeline. We started with a real Kaggle retail transactions dataset, 50,000 rows spanning 10 U.S. cities. We stripped PII at ingestion (no customer names, no payment details, no product lists) and enriched it with synthetic self-checkout health signals: latency, success rate, decline rate, error counts, and queue length. Peak hours (11am–2pm, 5pm–8pm) were modeled to show degraded metrics, and roughly 15% of devices were marked "flaky" to create realistic failure patterns. Final dataset: 45 stores, 11 SCO device types, 79 days.
Embedding and Storage. We aggregated the enriched rows into ~3,600 daily store summaries with risk scores pre-computed, converted each one into a natural-language chunk, and embedded them into 768-dimension vectors using Ollama's nomic-embed-text model running locally. Vectors and metadata landed in MongoDB Atlas, where a vector search index enables semantic queries like "which stores are struggling?" and metadata filters allow direct lookups by city, store ID, or risk level.
Retrieval (RAG). Our ragSystem.py is a hybrid retriever. When a user asks a question, it first parses the query for structured entities - store IDs like STR-1012, city names, risk levels, store types. If filters are found, it runs a direct filtered MongoDB query (fast and precise). If no filters are detected, it falls back to cosine-similarity vector search over the embedded chunks. Results are grouped by city with risk-breakdown summaries before being passed to the LLM.
Inference. The retrieved context is injected into a carefully crafted system prompt in riskOpsMethods.py that defines the risk-scoring rules, incident ticket format, explainability requirements, and Responsible AI guardrails. The full prompt goes to Groq's cloud API running Llama 3.3 70B on LPU hardware, which streams responses back word-by-word in 2–5 seconds, fast enough for live shift use.
Frontend. The entire UI is a single Streamlit app (app.py) that imports the Python backend directly, no separate API server needed. It renders the streaming chat, the manager dashboard (powered by dashboardData.py), and the auto-generated incident tickets in one cohesive interface.
Responsible AI by design. Three guardrails are hardwired into the architecture: PII is stripped at ingestion so it never enters the LLM prompt, every risk score surfaces the exact drivers that triggered it (verifiable by humans in seconds), and any high-impact action like disabling a lane requires explicit manager confirmation before execution.
Challenges we ran into
Grounding the LLM in real data without hallucinations. Our first prompts produced confident-sounding but fabricated metrics. We solved it by restructuring the system prompt to explicitly require all claims to cite the retrieved database context, and by building a fallback path for casual messages ("hi", "thanks") that bypasses retrieval entirely so the LLM can't invent incident data out of thin air.
Balancing filtered retrieval vs. vector search. Pure vector search missed obvious matches when users typed specific store IDs. Pure filter matching failed on natural-language questions. The hybrid retriever that tries filters first and falls back to vectors only when no entities are detected turned out to be the right call; it gives precise answers when precision is possible and graceful degradation when it isn't.
Keeping the demo credible without real incident data. We don't have access to NCR's internal SCO telemetry, so we engineered synthetic health signals on top of real transaction volume and timing. The hybrid approach (real transactions, synthetic health signals, modeled incident patterns) is more credible than pure synthetic data and was explicitly allowed by the challenge.
Streaming responses through Streamlit. Getting Groq's token stream to render smoothly in Streamlit without blocking the rest of the UI took several iterations of generator handling.
Accomplishments that we're proud of
Every metric in our pitch is measured, not estimated. Across our 50K-row dataset, we classified 7.8% of records as HIGH risk and 81% as MEDIUM-or-HIGH. Peak-hour incidents fire 3.5x more than off-peak (74% vs. 21%). Average latency climbs from 1,500ms off-peak to nearly 2,000ms during peak. Groq returns answers in 2–5 seconds. All verifiable from our code.
100% explainability. Every risk score in MongoDB carries a risk_drivers field listing exactly which signals triggered it. Every LLM response is grounded in retrieved context, not free-form generation. Full Responsible AI coverage. No PII, explainable decisions, human-in-the-loop confirmation; all three categories of AI risk covered by design, not as an afterthought.
A single-file frontend. The entire UI runs from one Streamlit app that imports the backend directly. Judges can clone the repo and run it in three commands.
What we learned
Hybrid retrieval beats pure vector search for structured domains where users frequently reference specific IDs and locations.
Groq's LPU inference is genuinely fast enough for live ops use. 2–5 seconds with a 70B model is a different UX than the 15–30 seconds we'd expected from cloud GPU inference.
Explainability isn't a feature you bolt on, it's an architecture decision. Surfacing the risk_drivers field everywhere (in the database, in the ticket, in the chat reply, on the dashboard) was cheap because we designed it in from day one.
The hardest part of building with LLMs is keeping them honest. Prompt engineering, retrieval grounding, and casual-message bypasses were more work than the LLM integration itself.
What's next for Voyix Ops Companion - Team Strawberry
- Integrate real NCR Voyix telemetry to replace our synthetic health signals and measure actual prediction accuracy against historical incidents.
- Multi-store fleet view with cross-store pattern detection: identify whether a vendor-wide payment processor issue is causing correlated failures across cities.
- Mobile app for store associates so fixes can be dispatched from anywhere on the sales floor, not just from the back office.
- Feedback loop where manager confirmations and outcomes train the risk engine over time, moving from rule-based scoring to a hybrid rule + learned model.
- Expand to Track A (Restaurant Ops); the same architecture applies to peak-hour checkout slowdowns at quick-service restaurants.

Log in or sign up for Devpost to join the conversation.