-
-
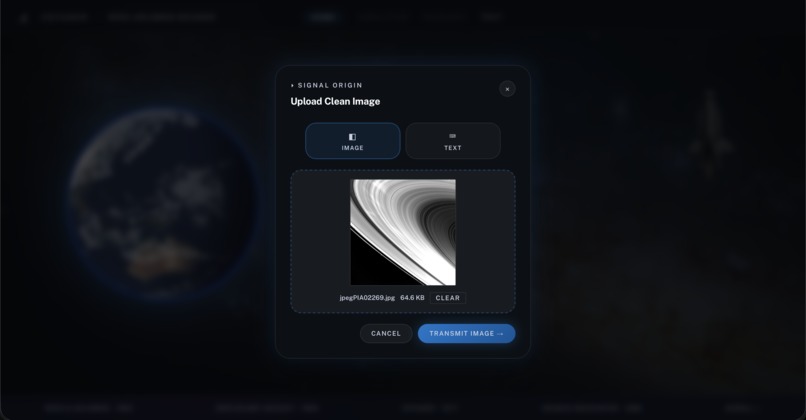
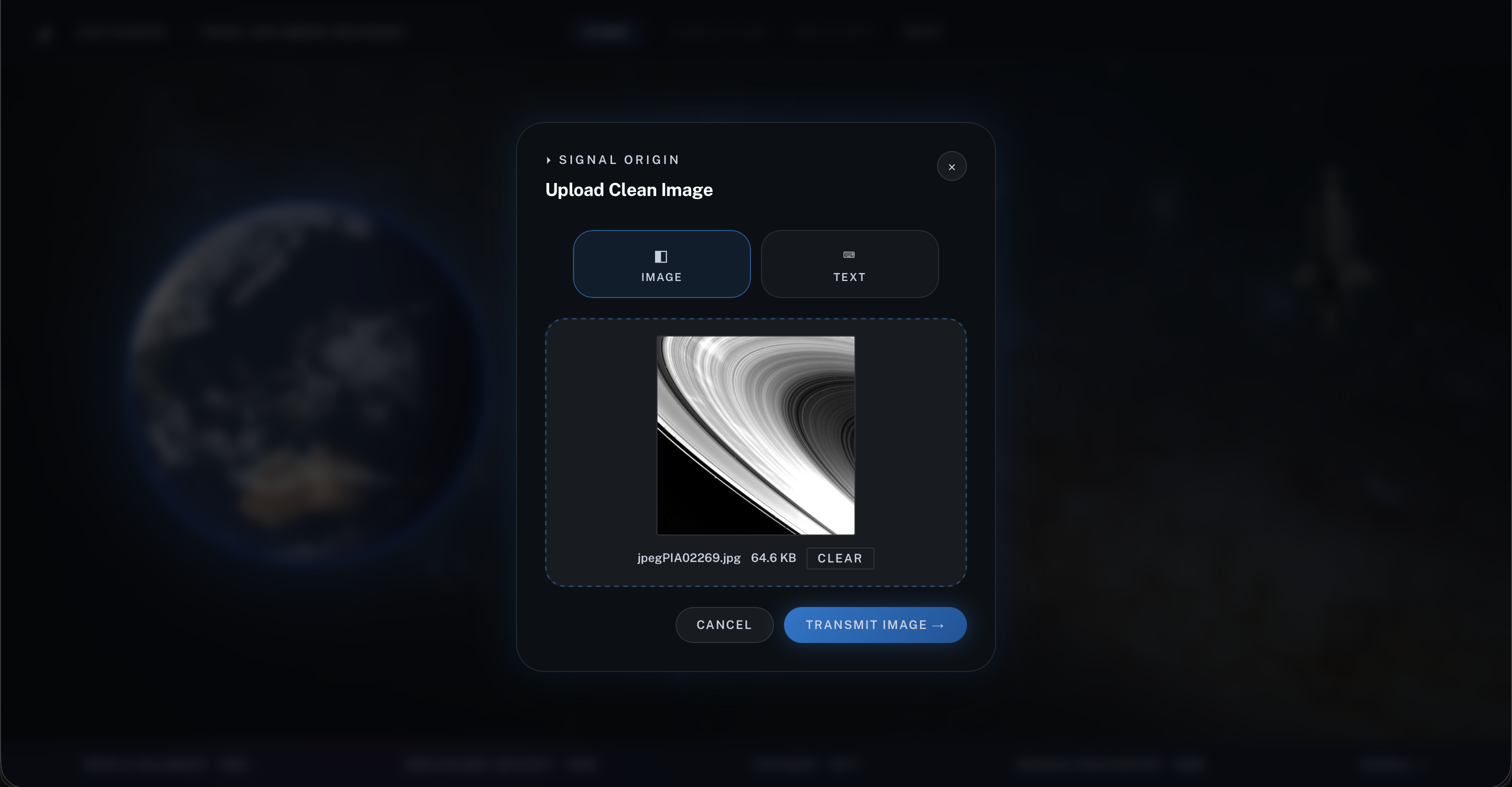
[1] Feature 1 - Upload a clean source image to encode, corrupt with simulated channel noise and recover through the RS pipeline
-
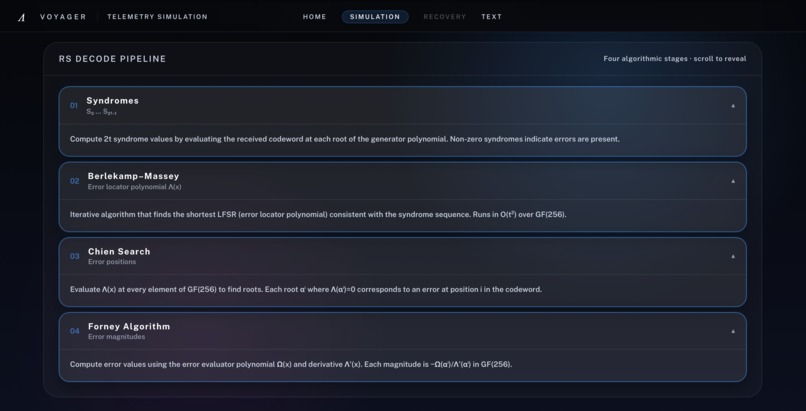
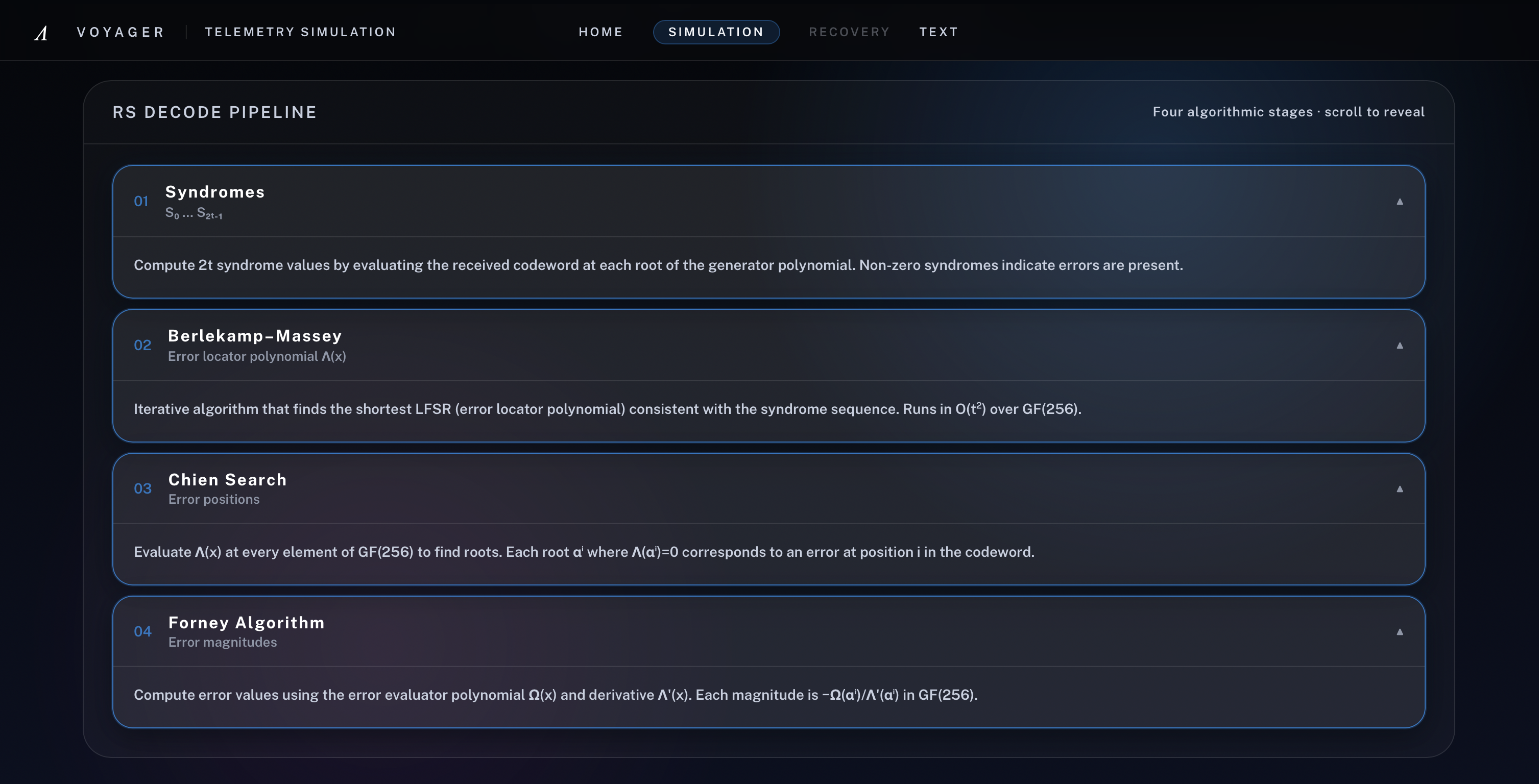
[2] Interactive walkthrough of all four Reed-Solomon decode stages
-
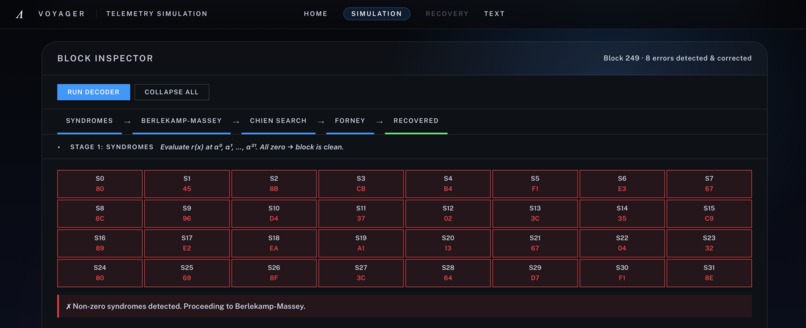
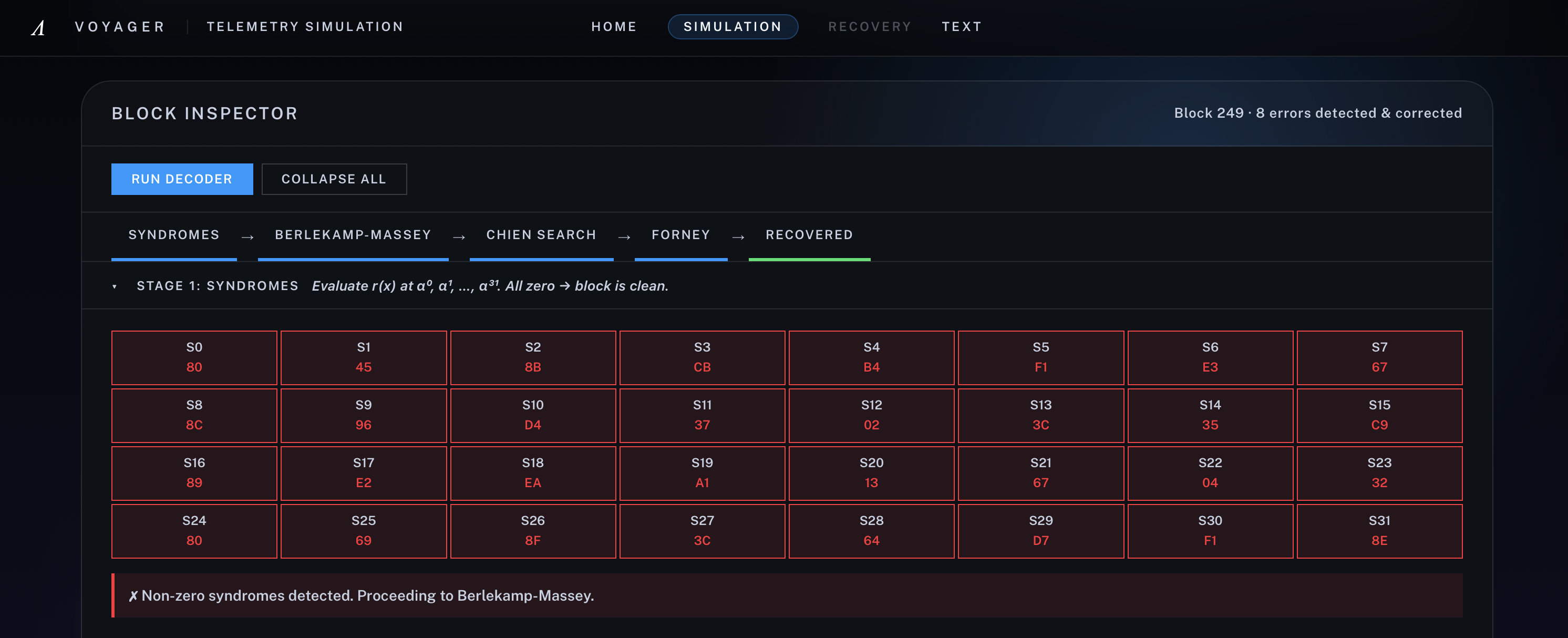
[3] Stage 1 - Syndrome: Non-zero evaluations show the received block is corrupted and must enter the decode pipeline
-
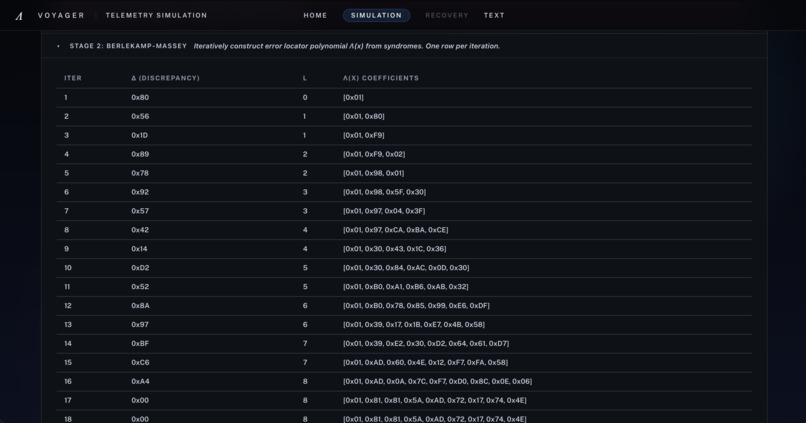
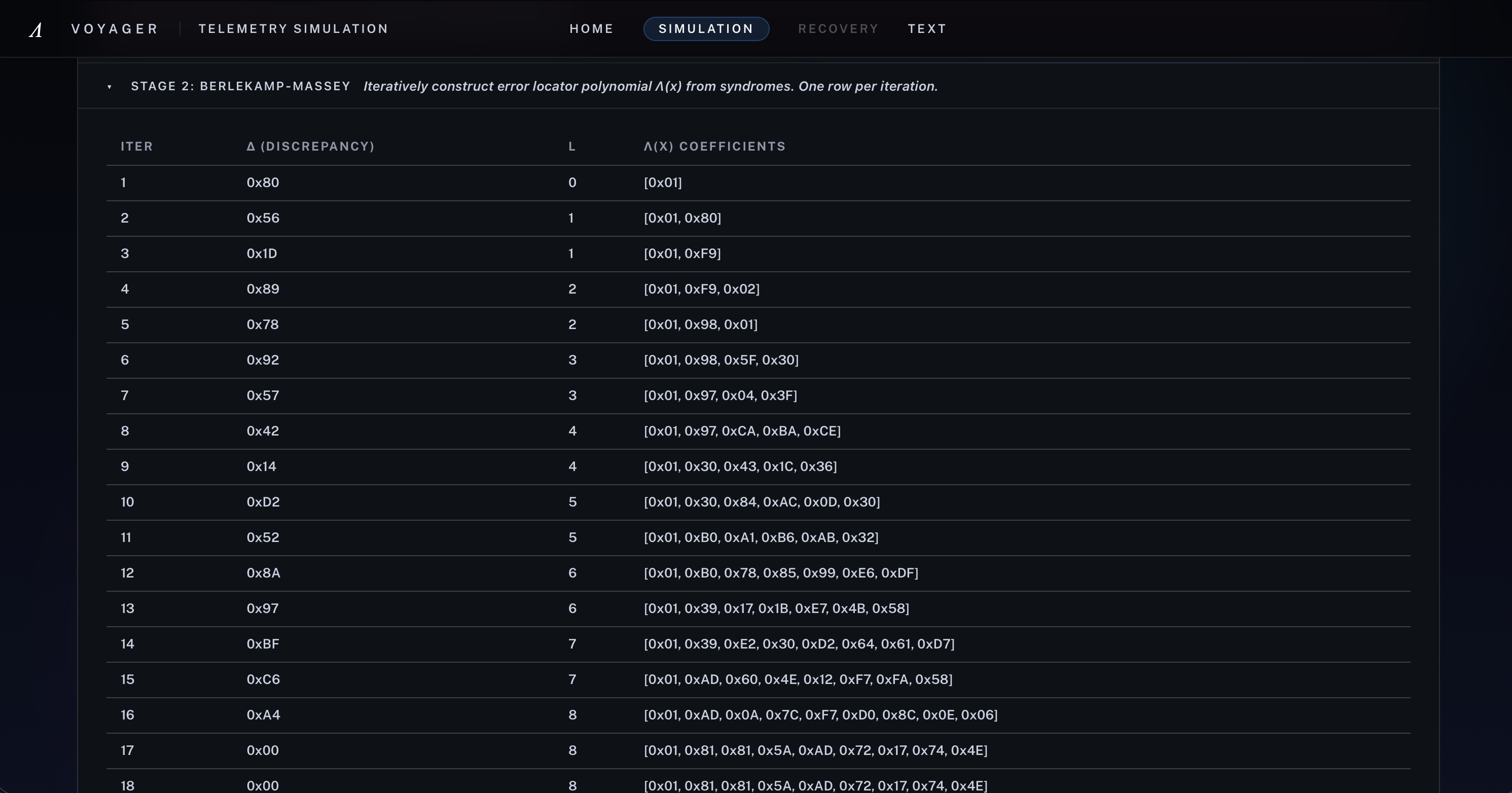
[4] Stage 2 - Berlekamp-Massey: From the syndrome sequence, Voyager builds the error-locator polynomial step by step
-
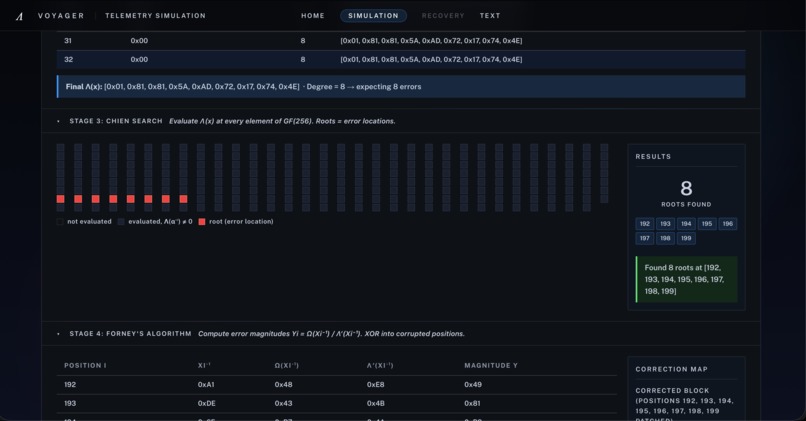
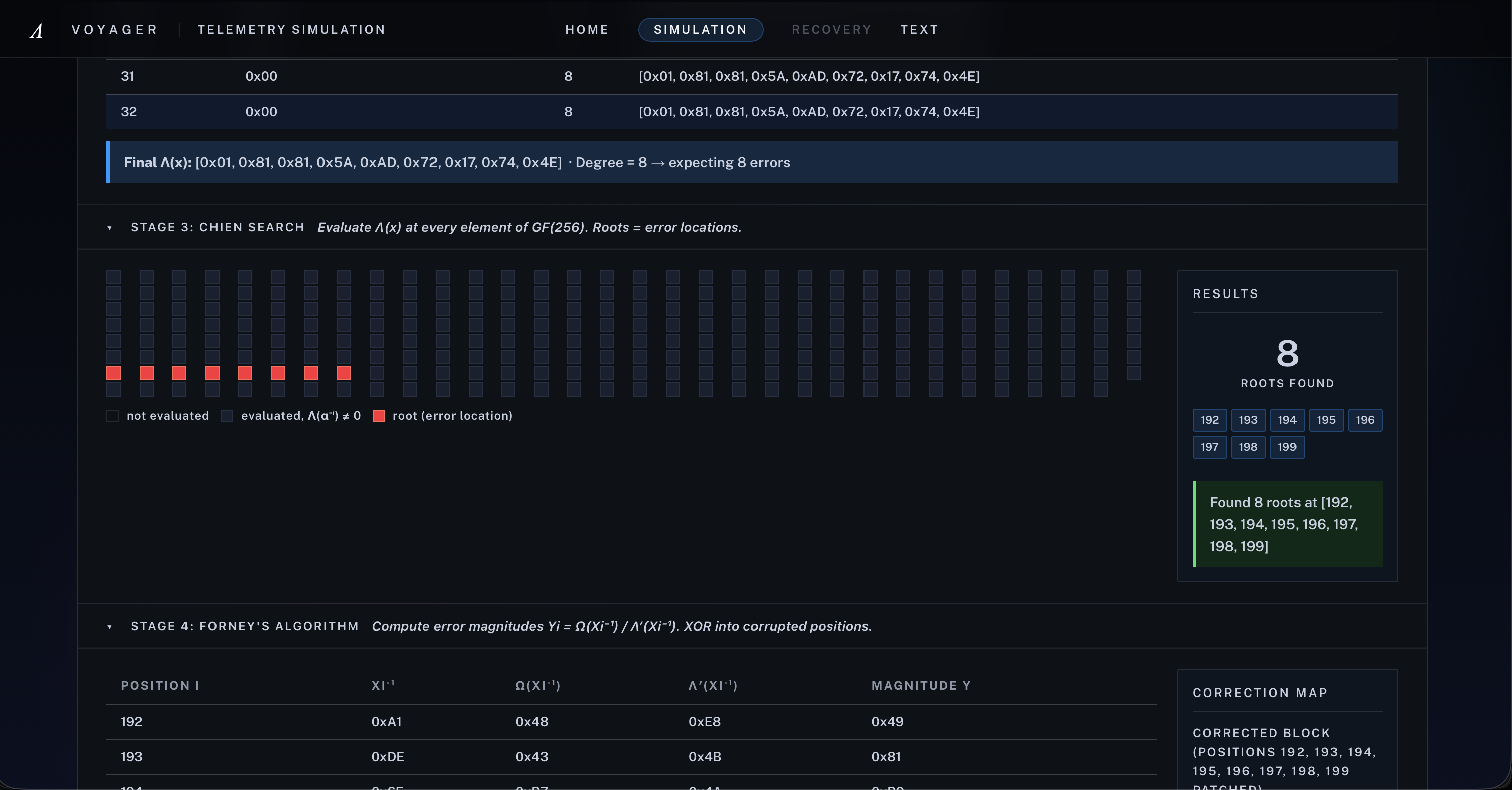
[5] Stage 3 - Chien Search: Roots of the error-locator polynomial reveal the exact corrupted byte positions in the codeword
-
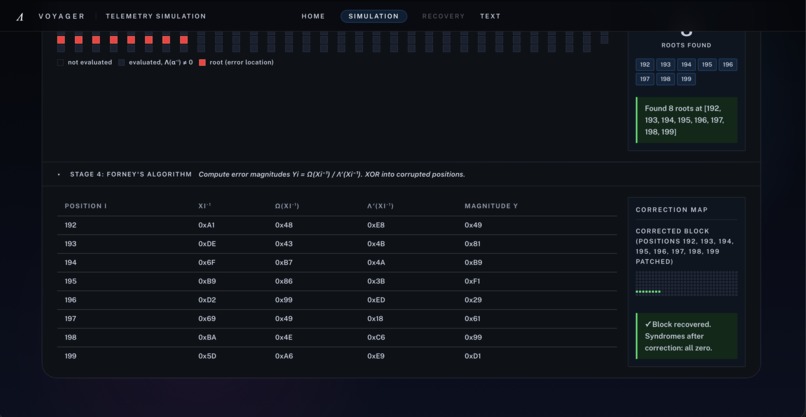
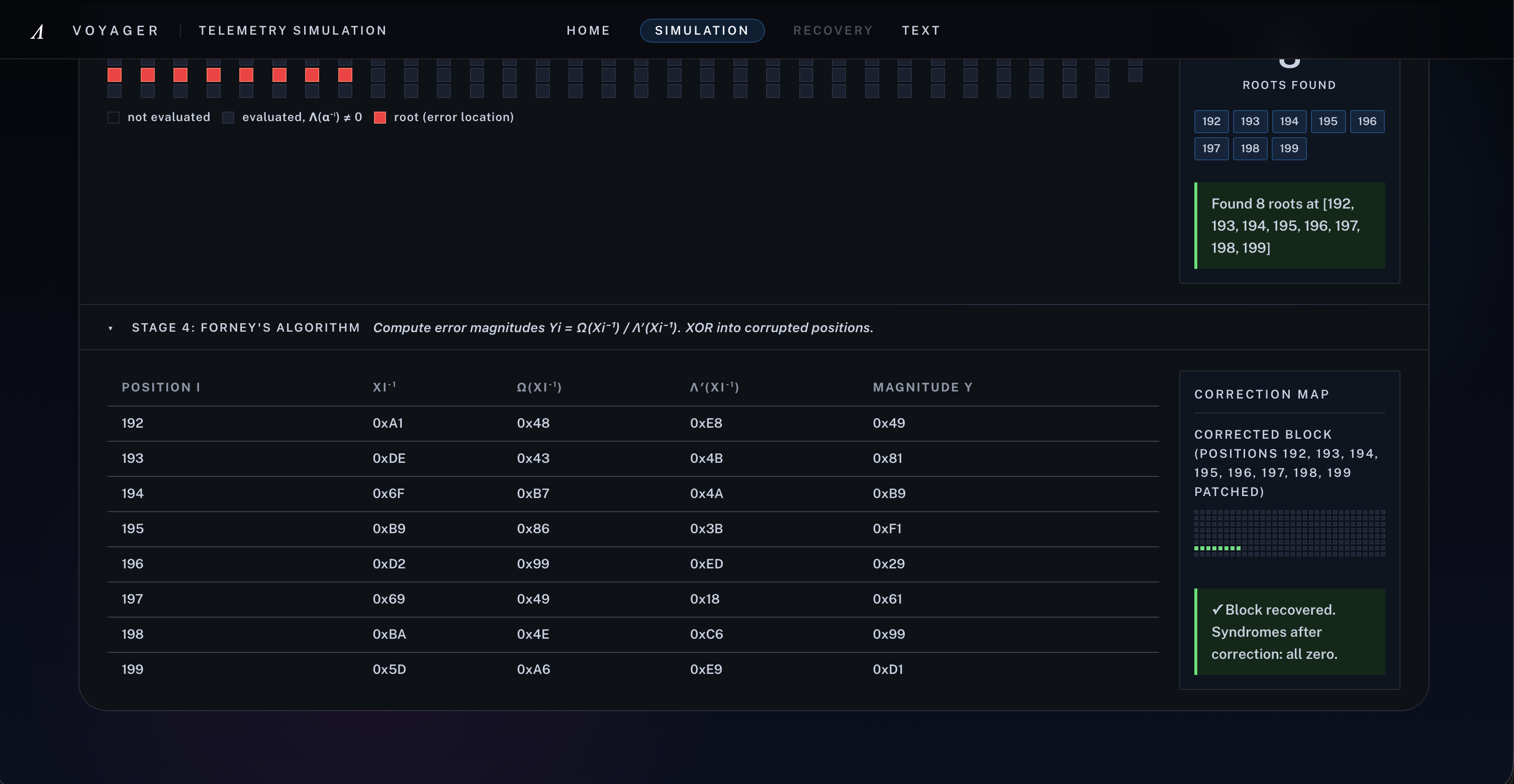
[6] Stage 4 - Forney's Algorithm: Voyager computes each error magnitude and patches corrupted bytes, driving all syndromes back to zero
-
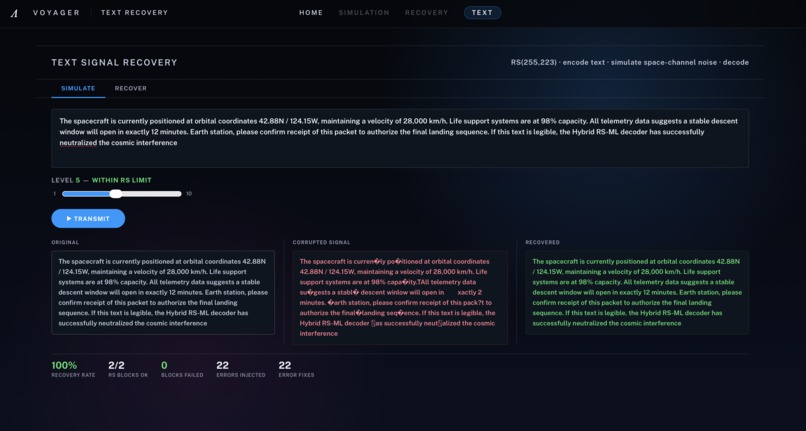
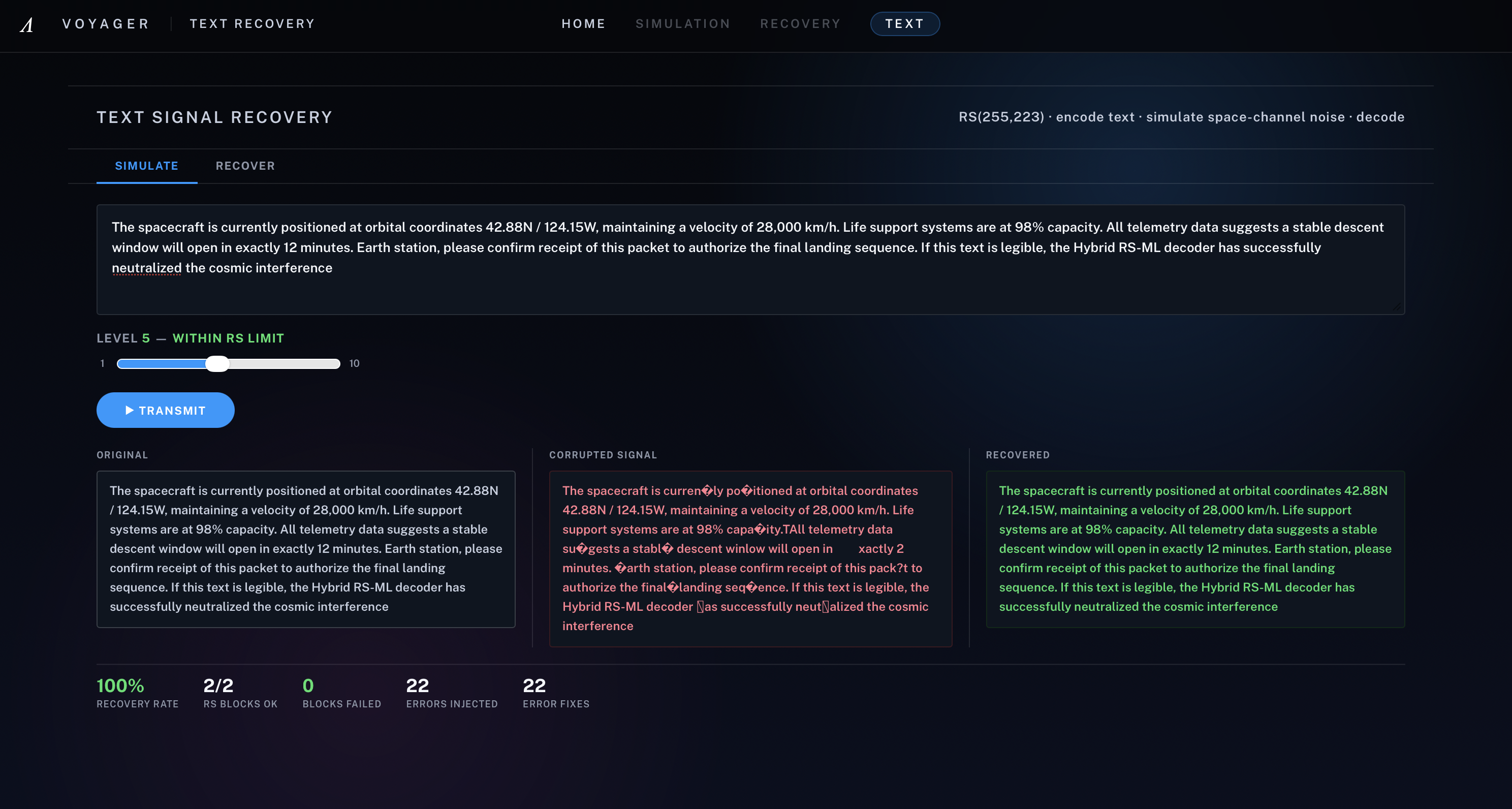
[7] Feature 2 - Text recovery with Reed-Solomon, showing original, corrupted and recovered messages under space-channel noise
Inspiration
Deep space communication is a one-shot problem. When a spacecraft sends data back from billions of kilometres away, retransmission may be impossible. If the signal arrives corrupted, the data could be lost for good.
NASA solved that problem with Reed-Solomon (RS) error correction. By adding 32 parity bytes to every 223-byte block, the receiver can reconstruct damaged data automatically. It was one of the key ideas that made long distance space communication practical.
Problem Statement & Our Solution
Most Reed-Solomon resources fall into two buckets: theory-heavy papers and specs or production implementations that hide the decoder entirely. That means users can read about syndromes, Berlekamp-Massey, Chien search, and Forney’s algorithm, but usually cannot see the full pipeline operate on real corrupted data from input to recovery.
This matters because Reed-Solomon feels abstract until it is visualised and most tools also hide failure modes. They do not show where decoding breaks, why the correction limit is exceeded or what data can still be recovered.
Voyager solves this by making the full Reed-Solomon pipeline visible and interactive. Users can corrupt real images or text, then watch encoding, corruption, and decoding step by step. Voyager shows when errors are still correctable and makes failure cases visible instead of treating them as a black box.
For images, Voyager combines RS(255,223) decoding with ML erasure detection. For text, Voyager adds a soft-failure recovery path that keeps partially intact content and repairs it with an n-gram layer when classical decoding fails.
Voyager is built for students, educators and engineers who want to understand how deep space error correction actually works, and it also contributes a practical improvement: hybrid recovery methods that extend classical Reed-Solomon decoding for corrupted images and text.
What it does
Voyager is an interactive rebuild of NASA’s Voyager Reed-Solomon error correction pipeline. It lets users corrupt deep space images or text messages, then watch the system attempt to recover them in real time, step by step.
For images, Voyager applies a hybrid recovery pipeline. It first encodes image data with RS(255,223), then simulates corruption and finally decodes the result block by block. On top of the classical Reed-Solomon decoder, we add ML erasure detection: a neural median filter scans each image for likely corrupted byte positions and passes those positions to the decoder as erasure hints. This allows the system to recover beyond the standard 16-error limit when those locations are identified accurately. When corruption is too severe for exact correction, Voyager falls back to a neural image refiner that produces a best-effort cleanup instead of discarding the block entirely.
For text, Voyager uses a different recovery path. Messages are UTF-8 encoded, packed into RS(255,223) blocks, corrupted with symbol-flip noise and decoded block by block using the full Reed-Solomon pipeline: syndrome computation, Berlekamp-Massey, Chien search and Forney correction. When a block exceeds the classical correction limit, Voyager preserves the partially recovered text instead of zeroing it out, then applies a second-stage repair pipeline using deterministic language heuristics: diacritic stripping, leet-speak repair, mid-word case repair and bigram-based character recovery. This helps restore readable text even when exact Reed-Solomon recovery is no longer possible.
The result is a system that does more than just show final outputs. Voyager lets users see how deep space error correction behaves under increasing noise, compare exact recovery against soft failure and understand both the power and the limits of classical decoding and ML-assisted recovery.
How we built it
Voyager has two parallel recovery pipelines, one for images and one for text, both built around a shared RS(255,223) codec. The entire system runs fully in the browser as a static web application, with no server-side computation. For performance, the image pipeline’s RS encoding and channel simulation were implemented in C and compiled to WebAssembly, while the text pipeline was implemented in JavaScript. Both pipelines expose their decoding stages in real time so users can vary the corruption level and observe how recovery changes step by step.
At the core of both pipelines is the Reed-Solomon code over GF(2^8) with primitive polynomial
$$ p(x) = x^8 + x^4 + x^3 + x^2 + 1. $$
Each block of K = 223 message bytes is encoded into a codeword of N = 255 bytes by appending 2t = 32 parity bytes, giving a hard correction capacity of
$$ t = \left\lfloor \frac{32}{2} \right\rfloor = 16 $$
unknown symbol errors per block.
The generator polynomial is
$$ g(x) = \prod_{i=0}^{31}(x - \alpha^i), \quad \alpha = \texttt{0x02} \in GF(2^8), $$
and each message polynomial m(x) is encoded as
$$ c(x) = m(x)\cdot x^{32} + \left(m(x)\cdot x^{32} \bmod g(x)\right). $$
Those 32 parity bytes are not copies of the message but a structured algebraic function of it.
We then rebuilt the classical four-stage decoder in full. For a received polynomial r(x), we first compute the 32 syndromes
$$ S_i = r(\alpha^i) = \sum_{j=0}^{254} r_j \cdot \alpha^{ij}, \quad i = 0,1,\ldots,31. $$
If the syndrome vector is nonzero, Voyager runs Berlekamp-Massey to recover the error-locator polynomial Lambda(x), uses Chien search to find its roots, and then applies Forney’s algorithm to compute correction magnitudes.
The key update step in Berlekamp-Massey is the discrepancy
$$ \delta = S_n + \sum_{i=1}^{L} \Lambda_i \cdot S_{n-i}, $$
and the Forney stage computes magnitudes through
$$ \Omega(x) = S(x)\cdot\Lambda(x) \bmod x^{32}, $$
$$ e_i = -X_i \cdot \frac{\Omega(X_i^{-1})}{\Lambda'(X_i^{-1})}. $$
After correction, Voyager recomputes syndromes to verify that decoding succeeded.
For the text pipeline, we added a soft-failure path instead of zeroing blocks that exceed the classical correction limit. When the decoder cannot correct a block, Voyager keeps the raw first 223 message bytes and then applies a four-stage n-gram repair layer: NFD diacritic stripping, leet-speak substitution, mid-word uppercase normalisation, and bigram-guided character recovery.
The key idea was that even in a failed block, much of the message is still intact. The report models this as
$$ E[\text{message errors}] = E \times \frac{K}{N} = E \times \frac{223}{255}, $$
so at E = 18, only about 15.7 of the 223 message bytes are expected to be corrupted.
The bigram repair stage scores printable ASCII candidates with
$$ \text{score}(c) = \log P(c \mid c_{\text{prev}}) + \log P(c_{\text{next}} \mid c) + 0.3 \cdot \log P(c), $$
and the user-facing confidence metric is
$$ \text{confidence} = \frac{\min(E_{RS} + E_{ng}, E_{\text{total}})}{E_{\text{total}}}. $$
For the image pipeline, we extended the classical decoder with a Neural Median Filter that predicts likely corrupted byte positions before decoding. Those positions are passed into the decoder as erasure hints. This matters because the theoretical limit changes when error locations are known: RS(255,223) can correct up to 16 unknown errors, but up to 32 known erasures. In practice, that lets Voyager recover image blocks that the classical decoder alone would not be able to fix. On top of that, we built an interactive visualisation layer that surfaces each stage of recovery live, from clean decoding through to boundary behaviour and soft failure.
Challenges we ran into
Our main challenge was making Voyager mathematically faithful without losing clarity. We rebuilt the real Reed-Solomon decoding pipeline, including syndrome computation, Berlekamp-Massey, Chien search and Forney magnitudes, while keeping it understandable and interactive for non-specialists.
We also had to work around the code’s hard limit. For RS(255,223), the decoder can correct at most 16 unknown symbol errors per block. That is a structural limit of the code, not an implementation issue, so we had to design carefully for cases beyond it.
That led to soft failure. In the text pipeline, discarding uncorrectable blocks throws away data that is often still partly usable. We built a fallback that preserves raw bytes without overstating confidence. The n-gram repair layer helped recover readable output, but only with tight constraints, because overly aggressive repair can introduce false positives.
The image pipeline introduced a similar tradeoff. ML erasure detection can push recovery past the classical limit, but only when the hints are accurate. Poor detection can mislead the decoder and reduce performance instead of improving it.
Accomplishments that we're proud of
We’re proud that Voyager is not just a visual demo, but a working and fully observable Reed-Solomon recovery system. Users can see the transition from successful decoding, to boundary behaviour, to soft failure, instead of treating the theory as a black box.
We’re also proud of the two hybrid extensions. For images, the Neural Median Filter turns some unknown errors into erasures, which can extend recovery beyond the 16-error limit when detection is accurate. For text, the n-gram repair layer extracts useful information from blocks that classical decoding would otherwise discard. Both extensions work on top of the original RS(255,223) structure without changing the encoder.
Another achievement is performance. The whole system runs in the browser and even a typical 500-character message can be processed fast enough to keep the experience interactive.
What we learned
We learned that observability matters. A lot of the literature explains each stage of Reed-Solomon decoding separately, but seeing the full pipeline execute on real corrupted data teaches something different: not just that the decoder works, but exactly where its guarantees start and stop.
We also learned that images and text fail differently, so they need different recovery strategies. For image data, local neighbourhood structure makes ML erasure detection useful. For text, the useful prior is not spatial but linguistic, which is why the repair layer relies on diacritics, substitution patterns, case normalisation, and bigram statistics instead.
Another lesson was that preserving partial structure is often better than hard failure. In the text path, retaining the raw message bytes from an uncorrectable block gives the n-gram layer something meaningful to work with. That turned out to be a much better design than wiping the block entirely.
Finally, we learned that hybrid systems only help when their assumptions are controlled carefully. ML-guided erasure detection can extend classical decoding, but inaccurate erasure hints can hurt it. In the same way, the n-gram layer can improve readability, but only if it is constrained tightly enough to avoid hallucinating repairs.
What's next for Voyager
The next step is to strengthen Voyager technically and extend it to more types of data. For the current image pipeline, the most important improvement is to formally evaluate the Neural Median Filter, since erasure hints only help when detection accuracy is high enough to guide the decoder rather than mislead it. For the text pipeline, we want to move beyond character-level bigram repair by adding word-level dictionary lookup and edit-distance search, which would make soft-failure recovery stronger and less dependent on English-only heuristics.
At the systems level, we want to test Voyager on real NASA deep space telemetry datasets and extend it from standalone RS(255,223) decoding to the full CCSDS-style concatenated pipeline, where Reed-Solomon is paired with an inner code for stronger protection against burst errors.
We also want to expand Voyager beyond images and text to other media, especially audio. The long term goal is to turn Voyager into a broader interactive platform for error correction across different signal types, where users can corrupt, recover and inspect not just images and messages, but also sound and other forms of transmitted data.
Reference
Berlekamp, E. R. (1968). Algebraic coding theory. McGraw-Hill.
Consultative Committee for Space Data Systems. (2003). TM synchronization and channel coding (CCSDS 131.0-B-1). CCSDS Secretariat.
Forney, G. D. (1965). On decoding BCH codes. IEEE Transactions on Information Theory, 11(4), 549–557. https://doi.org/10.1109/TIT.1965.1053825
Ludwig, R., & Taylor, J. Voyager Telecommunications. https://voyager.gsfc.nasa.gov/Library/DeepCommo_Chapter3--141029.pdf
Massey, J. L. (1969). Shift-register synthesis and BCH decoding. IEEE Transactions on Information Theory, 15(1), 122–127. https://doi.org/10.1109/TIT.1969.1054260
McEliece, R. J., & Swanson, L. (1994). Reed-Solomon codes and the exploration of the solar system. In S. B. Wicker & V. K. Bhargava (Eds.), Reed-Solomon codes and their applications (pp. 25–40). IEEE Press.
Reed, I. S., & Solomon, G. (1960). Polynomial codes over certain finite fields. Journal of the Society for Industrial and Applied Mathematics, 8(2), 300–304. https://doi.org/10.1137/0108018
Shannon, C. E. (1948). A mathematical theory of communication. Bell System Technical Journal, 27(3), 379–423. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x
VOYAGER 2 - Launch (1977/08/20) [HD source]. YouTube. https://www.youtube.com/watch?v=SmIPMhKyiY0
Reed–Solomon error correction. Wikipedia. https://en.wikipedia.org/wiki/Reed%E2%80%93Solomon_error_correction
Built With
- berlekamp-massey
- c
- canvas-api
- chien-search
- clang
- css
- forney-algorithm
- framer-motion
- galois-field-arithmetic
- javascript
- react-18
- react-three-drei
- react-three-fiber
- reed-solomon
- tensorflow.js
- three.js
- typescript
- vite
- web-assembly



Log in or sign up for Devpost to join the conversation.