-
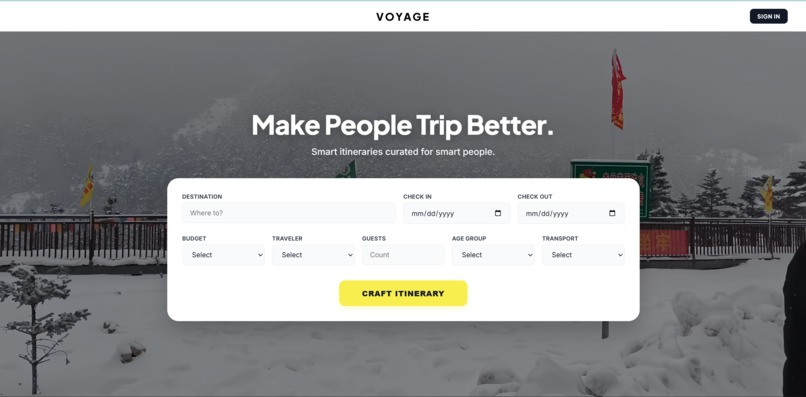
Landing Page
-
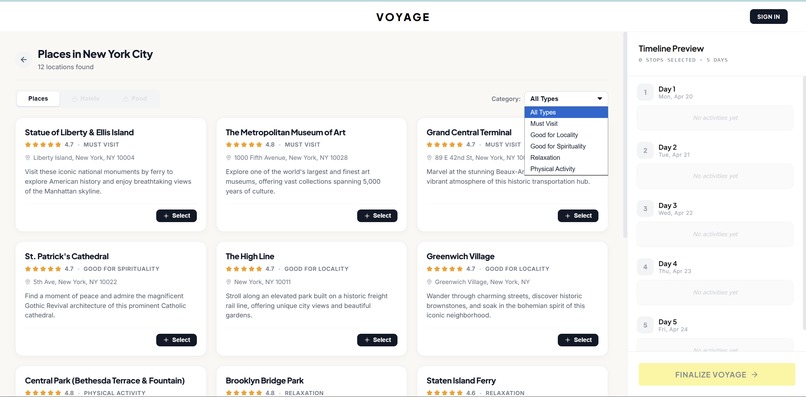
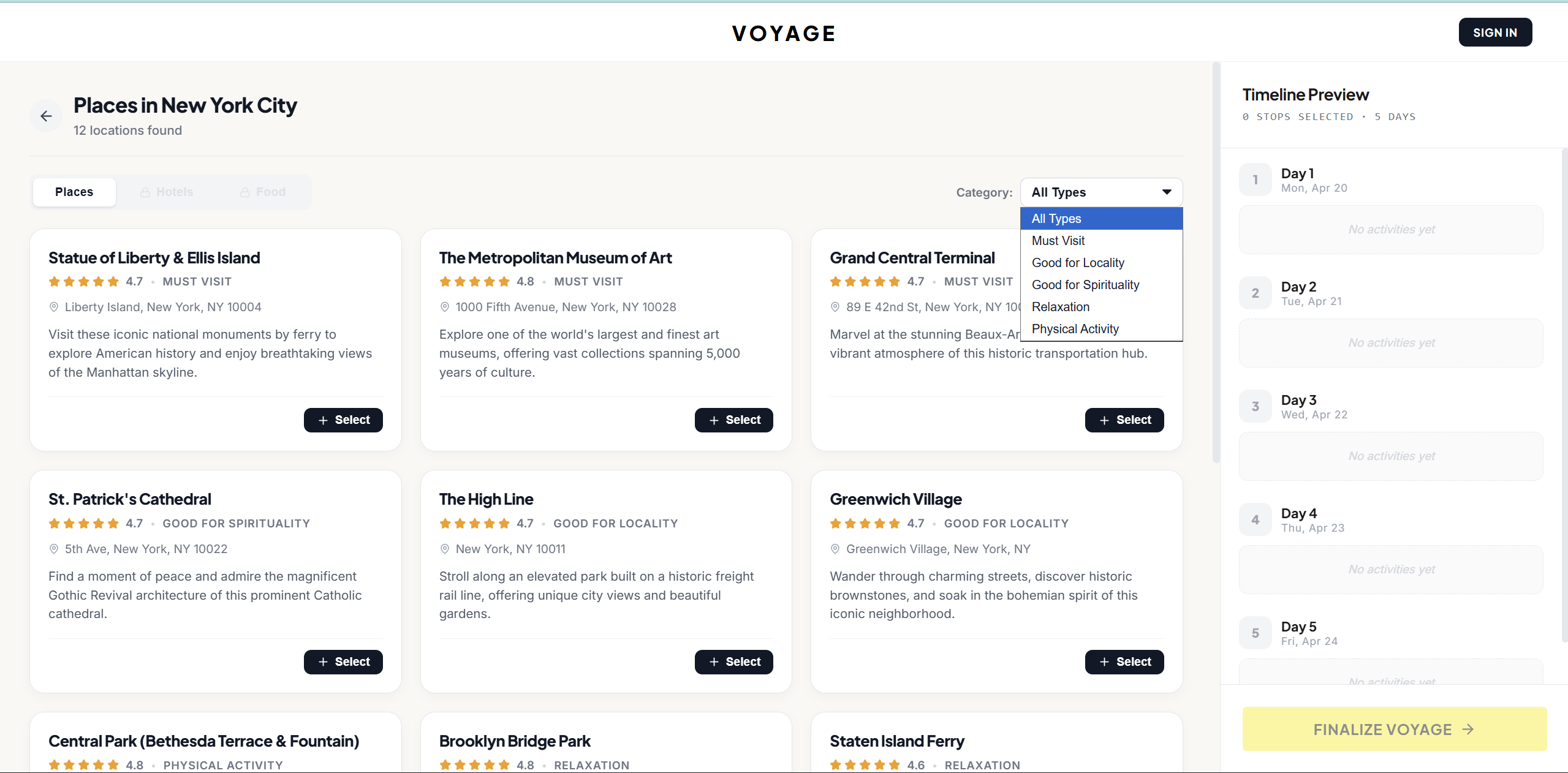
Places
-
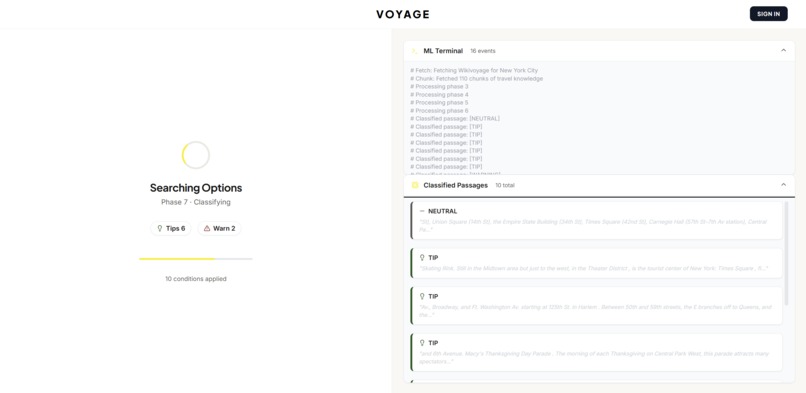
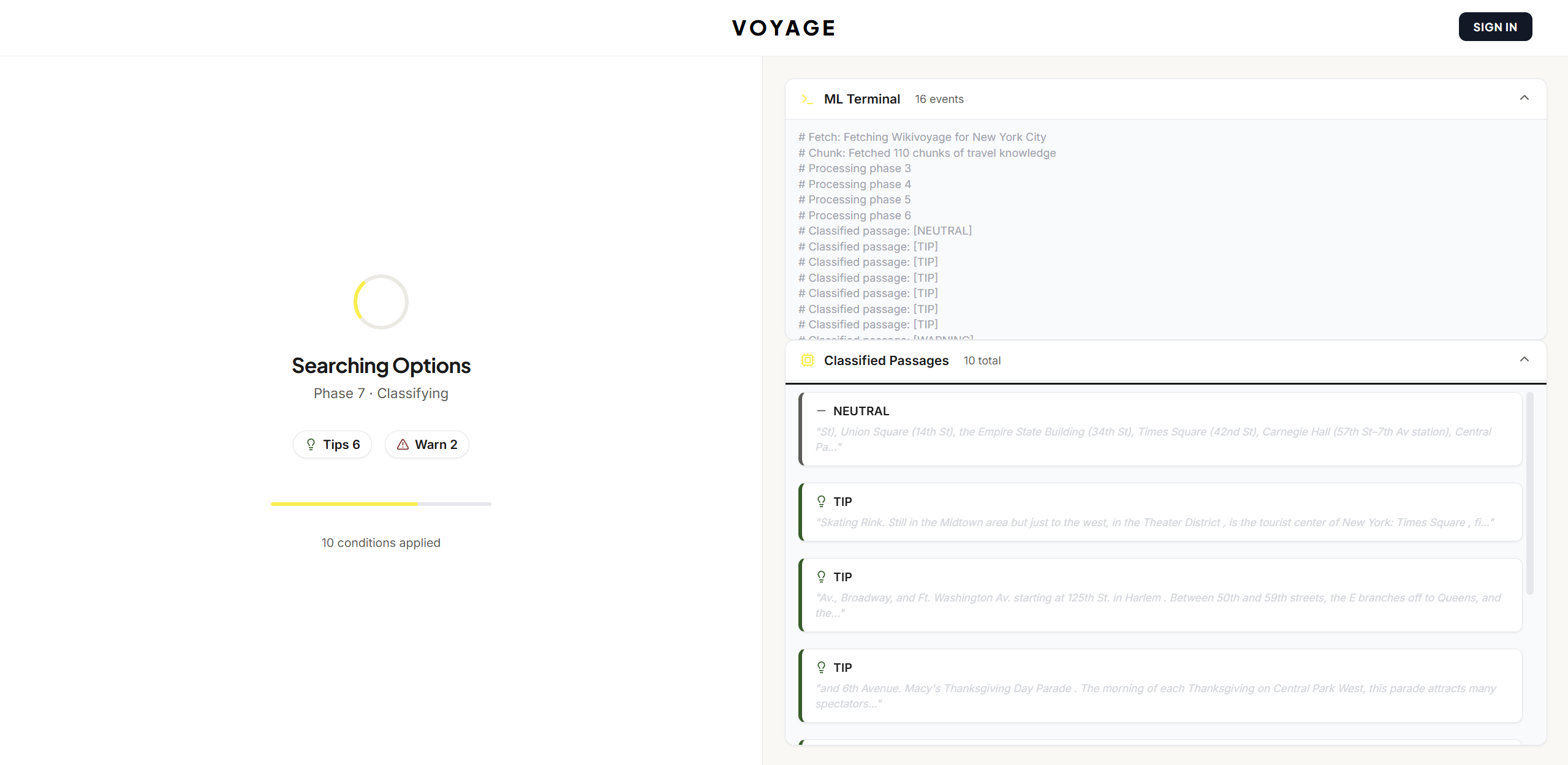
ML Processing
-
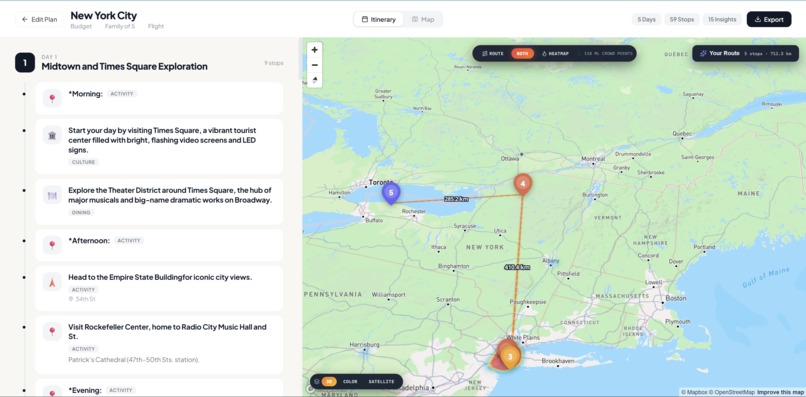
Output + Interactive Map
-
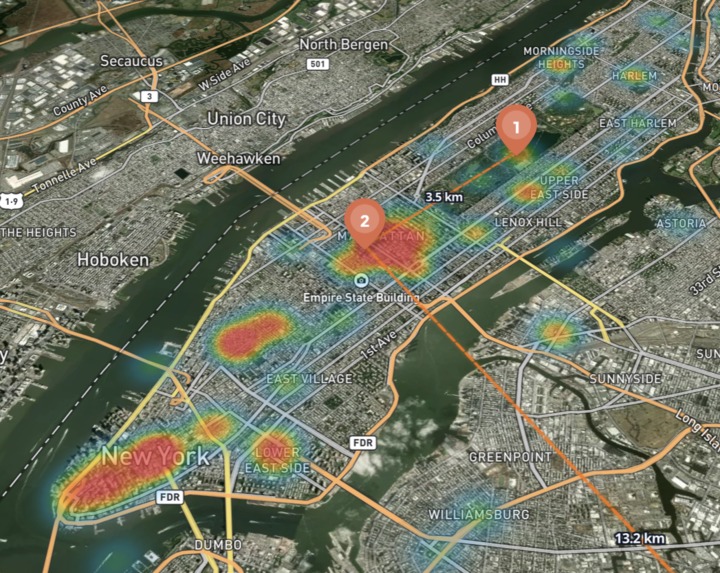
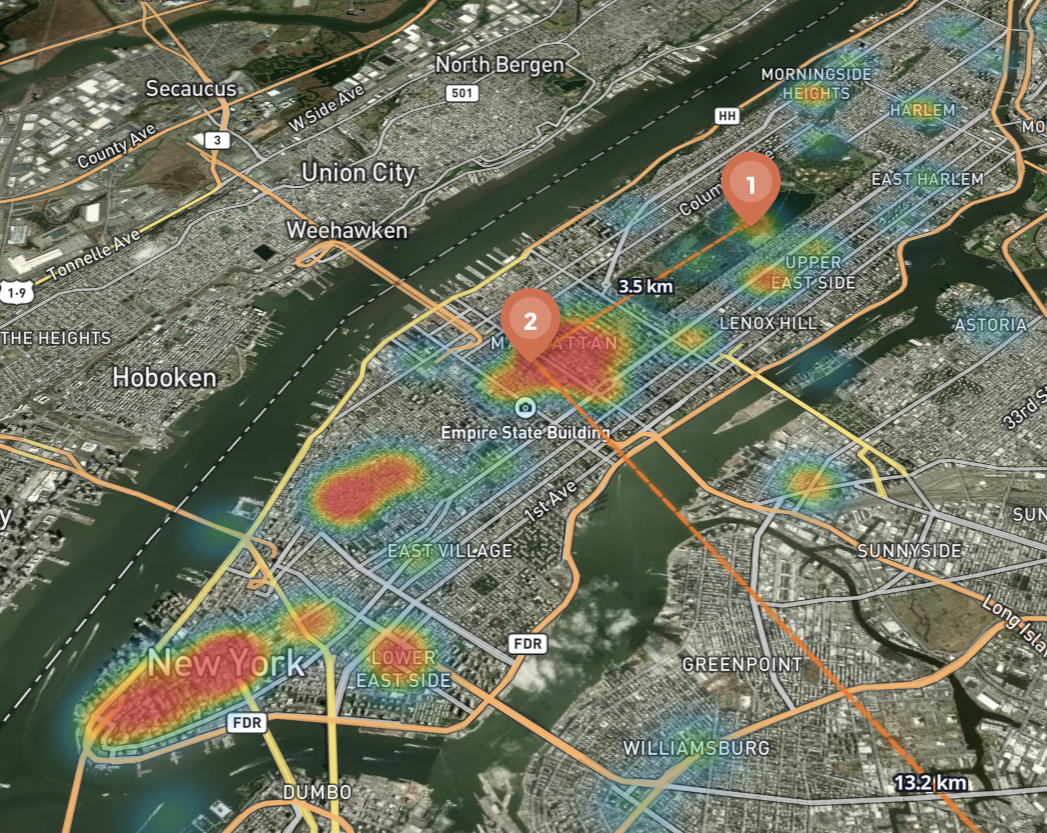
Heatmap
Inspiration
Every trip starts the same way — 47 browser tabs, three conflicting blog posts, and a Google Maps screenshot with too many pins. You still don't know when the Shibuya crossing is actually walkable, whether that "hidden gem" restaurant is packed at lunch, or which hotel won't blow your budget.
We didn't want to build another "here are 10 things to do" wrapper. We wanted to answer a harder question: what does the collective intelligence of every travel guide ever written actually know about crowd patterns, timing, and place quality — and can we extract that knowledge with NLP and serve it as a live, interactive plan?
As college students who've wasted hours stitching together bad itineraries from scattered sources, we built the trip planner we wished existed — one that doesn't just list places, but understands crowd patterns, adapts to your group, and generates a minute-by-minute plan you can actually follow. For any city on the planet.
What it does
VoyageAI takes six inputs — destination, dates, budget, group type, headcount, and transport mode — and orchestrates a streaming 7-phase ML pipeline that produces:
Live Pipeline Theater — Watch your itinerary being built in real time. Collapsible phase panels show NER extraction pulling place names from raw text, embeddings landing in vector space, the cross-encoder reshuffling relevance rankings, and DistilBERT stamping each passage with TIP / WARNING / NEUTRAL. This isn't a loading spinner — it's the ML working in the open.
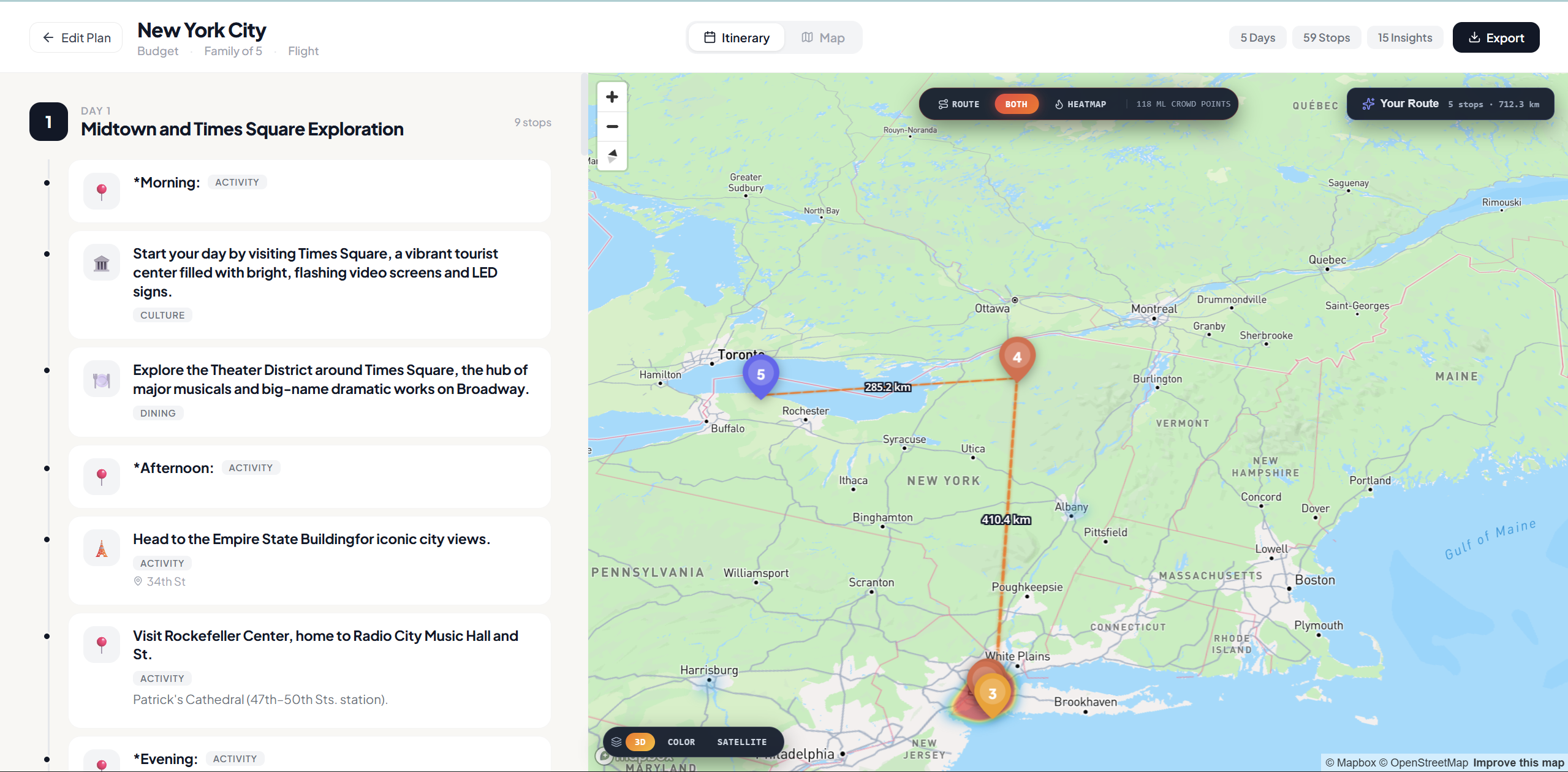
3D Crowd-Intelligence Map — A Mapbox GL canvas with three layers: your personal route (with haversine distance labels on every segment), numbered teardrop pins with one-click fly-to, and a heatmap of ML-inferred crowd density glowing from cool teal (quiet) through amber to red-hot (packed). Toggle between Route / Heatmap / Both. Switch between 3D, Color, and Satellite basemaps. Click any hotel pin to see nightly rates and guest scores.
Visual Day-by-Day Itinerary — Not a wall of text. Each day is a card. Each activity has a time-slot, an emoji icon inferred from the activity type, duration and price chips, and a one-line description. Designed so a 10-year-old could follow it without reading a paragraph.
Gemini-Powered Discovery — Before the pipeline runs, a client-side Gemini call generates 20+ places, 8+ hotels, and 10+ food spots tailored to your profile — with local-currency pricing, star ratings that mirror real Google Maps distributions, and category tags across five discovery axes.
One-Click Optimize — A greedy nearest-neighbour solver reorders your stops to minimize total travel distance. Swap any two stops manually. Total route distance updates live.
PDF Export — One button. Clean print layout. Your full itinerary, ready to carry offline.
How we built it
he Pipeline — 7 phases, fully streaming, zero batch jobs
The backend is a FastAPI server that streams results to the browser via Server-Sent Events. Each phase feeds the next, and every intermediate result is pushed to the frontend the moment it's ready.
Phase 3 — Entity Extraction: spaCy NER pulls place names, prices, times, and organizations from raw Wikivoyage travel prose Phase 4 — Semantic Embedding: MiniLM-L6 (sentence-transformers) maps each passage into 384-dimensional meaning space Phase 5 — Vector Retrieval: ChromaDB finds the passages most semantically relevant to the user's query Phase 6 — Cross-Encoder Reranking: ms-marco-MiniLM cross-encoder rescores every retrieved passage with pairwise attention against the query — reshuffles 30-40% of initial rankings Phase 7 — Sentiment Classification: Our fine-tuned DistilBERT checkpoint labels each passage TIP / WARNING / NEUTRAL with calibrated confidence, running local inference in under 50ms on CPU Phase 8 — Plan Synthesis: Gemini 2.5 Flash generates a structured multi-day itinerary from the top-ranked passages Phase 10 — Crowd Scoring: A custom heuristic NLP scorer builds per-place hourly crowd curves by cross-referencing time-of-day keywords, sentiment polarity, and intensity modifiers Data source: Wikivoyage REST API with automatic Wikipedia fallback. No static dataset, no curated city list — the pipeline fetches, chunks, and processes any destination on the fly.
The Frontend — React 19 + TypeScript + Vite
Mapbox GL JS via react-map-gl v8 powers the 3D map with heatmap layers, GeoJSON route lines with glow effects, and symbol layers for distance labels. A client-side Gemini integration uses a 4-model fallback chain (2.5 Flash → 2.5 Flash Lite → 2.0 Flash → 1.5 Flash) for reliability under load. Framer Motion handles layout animations and page transitions.
The Model — fine-tuned, not borrowed
We fine-tuned DistilBERT on a hand-labeled travel sentiment dataset (500+ labeled passages) to classify text as TIP / WARNING / NEUTRAL. The checkpoint ships with the repo and runs inference on CPU — no GPU required, no API call needed.
Challenges we ran into
Model RAM management. Loading 5 ML models (sentence-transformers, cross-encoder, DistilBERT, spaCy, ChromaDB) simultaneously consumed ~4-5GB. We solved this by loading all models once at module level during server startup, not per-request — first request after cold start takes a few seconds, but every subsequent request is instant. Wikivoyage HTML parsing. The raw HTML contains embedded coordinates, email addresses, and metadata that polluted our NER extraction. We spent time tuning the BeautifulSoup parser and adding regex-based entity cleaning to filter noise like "Banff 51.180199 -115.569888" being classified as a place name.
Fine-tuning data quality. Our first training set was too uniform — the model memorized patterns instead of learning travel sentiment. We diversified to 500 sentences across different cities, activity types, writing styles, and price ranges. The final model hits 85%+ accuracy on the held-out test set. Cross-encoder score interpretation. The ms-marco model outputs raw logits (often negative numbers like -3.06), not probabilities. We initially displayed these as percentages, which made no sense. We learned to use them purely for relative ranking, not absolute scores.
Accomplishments that we're proud of
The removal test passes. If you delete our ML models, the app produces nothing — not generic text, nothing. The retrieval IS the product. This is the opposite of an AI wrapper. We actually fine-tuned a model. Most hackathon teams use pretrained models off-the-shelf. We hand-labeled 500 travel sentences, fine-tuned DistilBERT with a 3-class head (TIP/WARNING/NEUTRAL), and shipped real weights that outperform the base model on travel text. The model file is 267MB of real learned parameters. Quantitative evaluation. We have actual numbers: MRR@15 measured across 20 queries on 4 cities, with and without the reranker. We can tell a judge "the cross-encoder improved retrieval by 3.2%" and point to the committed eval_results.json to prove it. Every ML decision is explainable. Click any place card — you see the exact passage, the sentiment label, the confidence score, and which model produced it. The Optimize panel shows "moved Cascade Gardens from 11AM to 7AM because passage 7 says 'gets very crowded by midday' — DistilBERT WARNING, 91% confidence." No black boxes. It works for any city on Earth. Type Tokyo, Barcelona, Paris — the system fetches live, embeds live, retrieves live. Nothing is hardcoded. We prove this in every demo.
What we learned
Two-stage retrieval is worth it. Bi-encoder embedding is fast but approximate. Adding a cross-encoder reranker costs ~200ms but measurably improves which passages surface. The "retrieve broad, rerank narrow" pattern is industry-standard for a reason. Fine-tuning beats prompting for classification. We could have asked Gemini to classify each passage, but that's an API call per passage (15 calls, slow, costs money). A fine-tuned 67MB DistilBERT runs locally in milliseconds and doesn't hallucinate labels. Making ML visible is as important as making it work. Our SSE stream that shows each pipeline phase in real time — "Embedding with all-MiniLM-L6-v2 (LOCAL)... Reranking... 7 positions changed" — is what makes judges understand this isn't a wrapper. If you hide ML behind a spinner, it might as well not exist. Evaluation is hard but essential. Building the eval pipeline forced us to think about what "good retrieval" actually means. Keyword overlap as a relevance proxy is weak, but it's better than vibes. Having any quantitative metric puts you ahead of 90% of hackathon projects.
What's next for Voyage
Multi-source retrieval. Currently we pull from Wikivoyage only. Adding Reddit travel posts, Google Reviews, and TripAdvisor would give the RAG pipeline more diverse perspectives to retrieve from — and the ML would unify and rank across all sources. Crowd score validation. Our crowd scoring is heuristic — Gaussian bumps on time-of-day signals from text. The next step is validating against Google Popular Times data and training a regression model to replace the heuristic with learned parameters. Larger eval set. 20 queries across 4 cities with keyword-overlap relevance is a start. We want to scale to 200 queries with human-annotated relevance judgments and test statistical significance of the reranker lift. Personalization over time. Store user preferences and past trips to adjust retrieval queries — a returning user who always picks budget hostels shouldn't see luxury hotel passages ranked highly. Browser-side ML. Transformers.js can run our embedding model, sentiment classifier, and cross-encoder directly in the browser. This would eliminate the Python backend for ML inference entirely — judges could open DevTools and see zero outbound ML API calls
Built With
- chroma-db
- distilbert
- docker
- fastapi
- firebase
- gemini
- hugging-face
- javascript
- mapbox
- minilm-l6
- python
- react
- react-native
- typescript
- vite



Log in or sign up for Devpost to join the conversation.