-
-
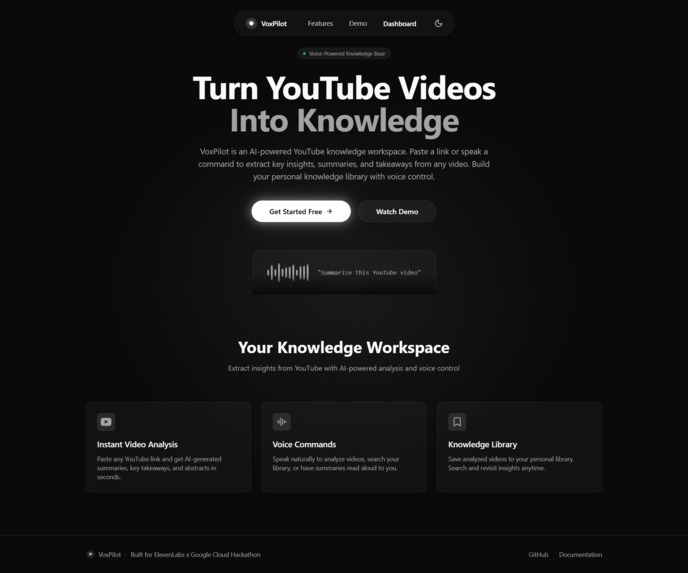
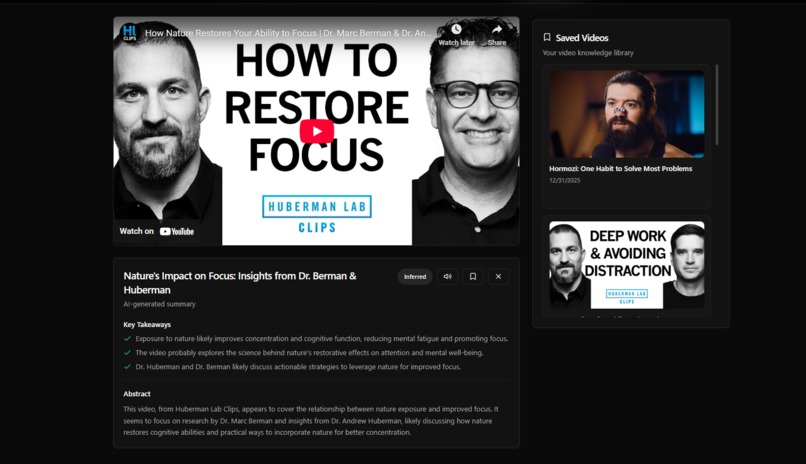
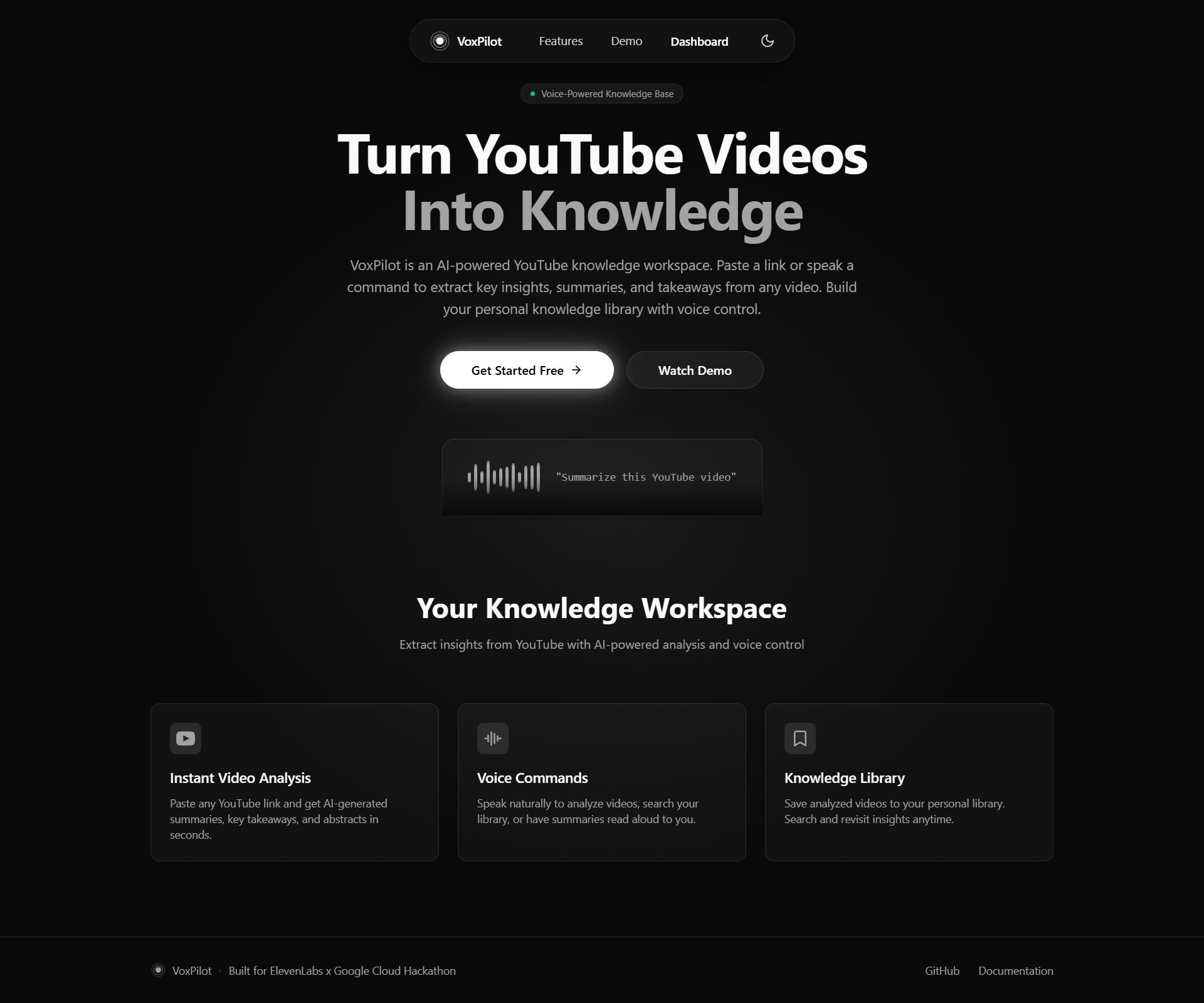
Landing page
-
Login page
-
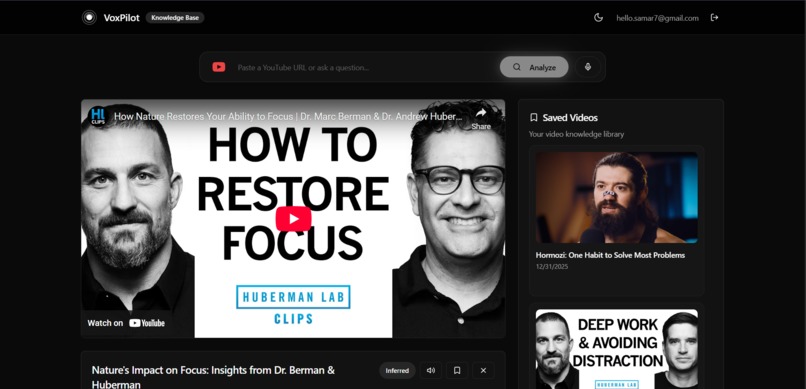
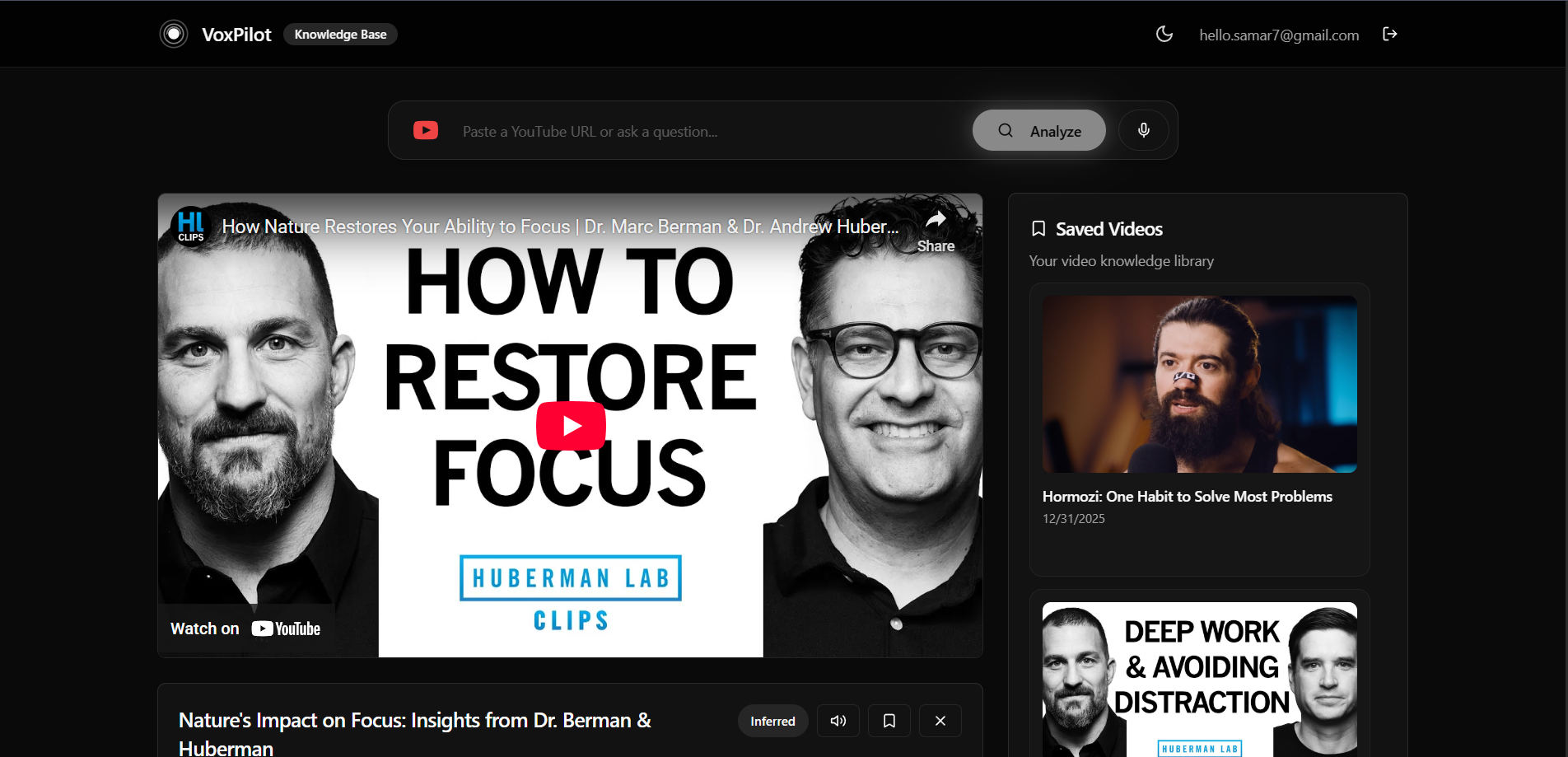
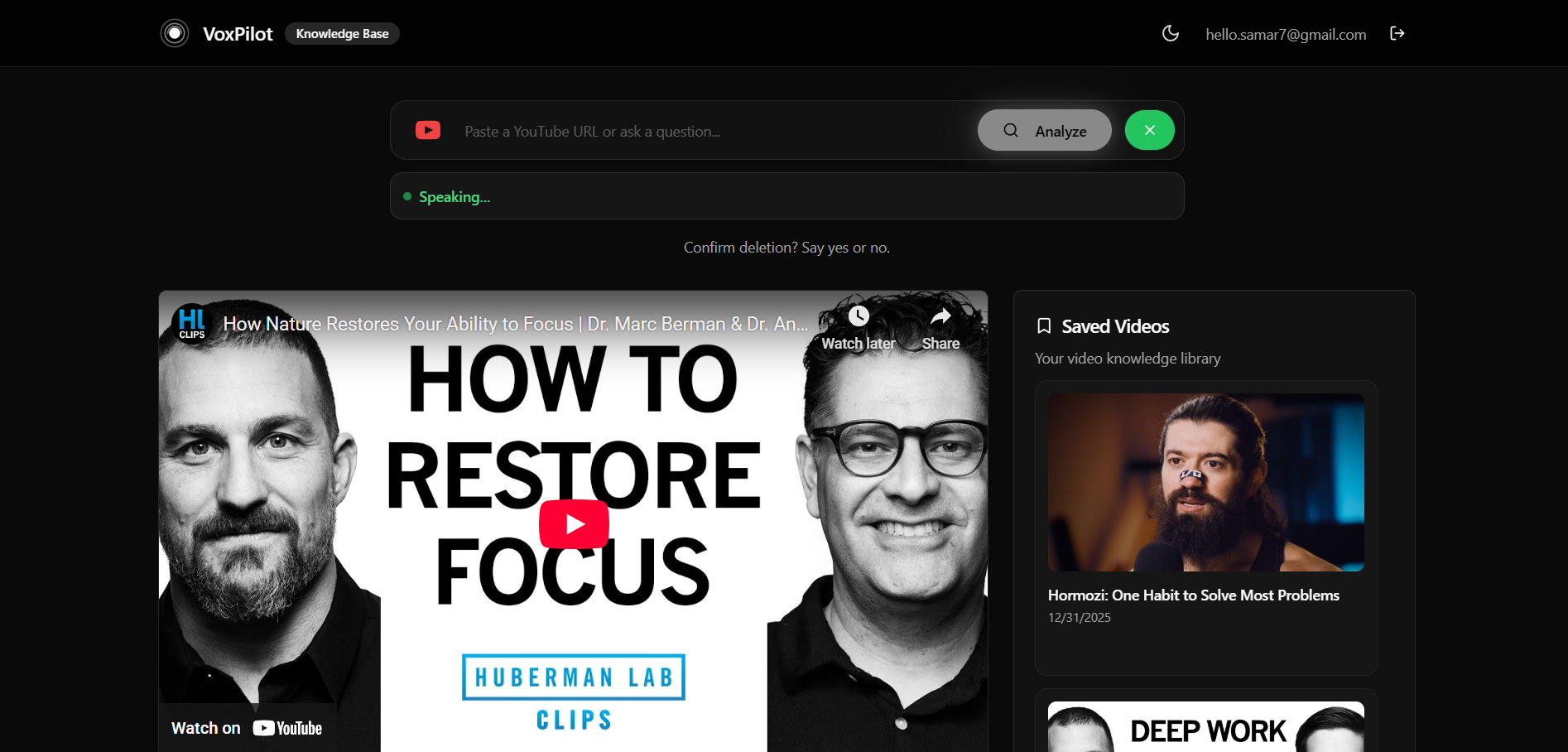
Main dashboard
-
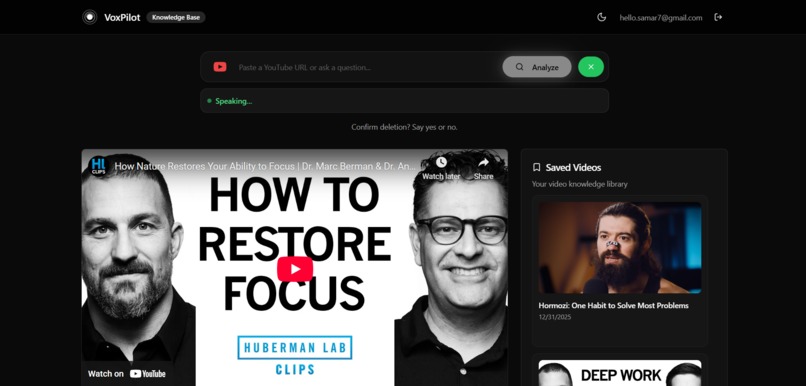
-
Inspiration
Video has become the dominant medium for learning, but extracting actual knowledge from long-form content remains slow, passive, and inefficient. Most people either skim through videos, forget what they watched, or never revisit valuable insights buried inside hours of footage. VoxPilot was born from a simple question: What if you could talk to your video knowledge instead of passively consuming it? We wanted to build a voice-first AI system that transforms YouTube videos into structured, reusable knowledge while staying transparent, safe, and production-ready from day one.
What it does
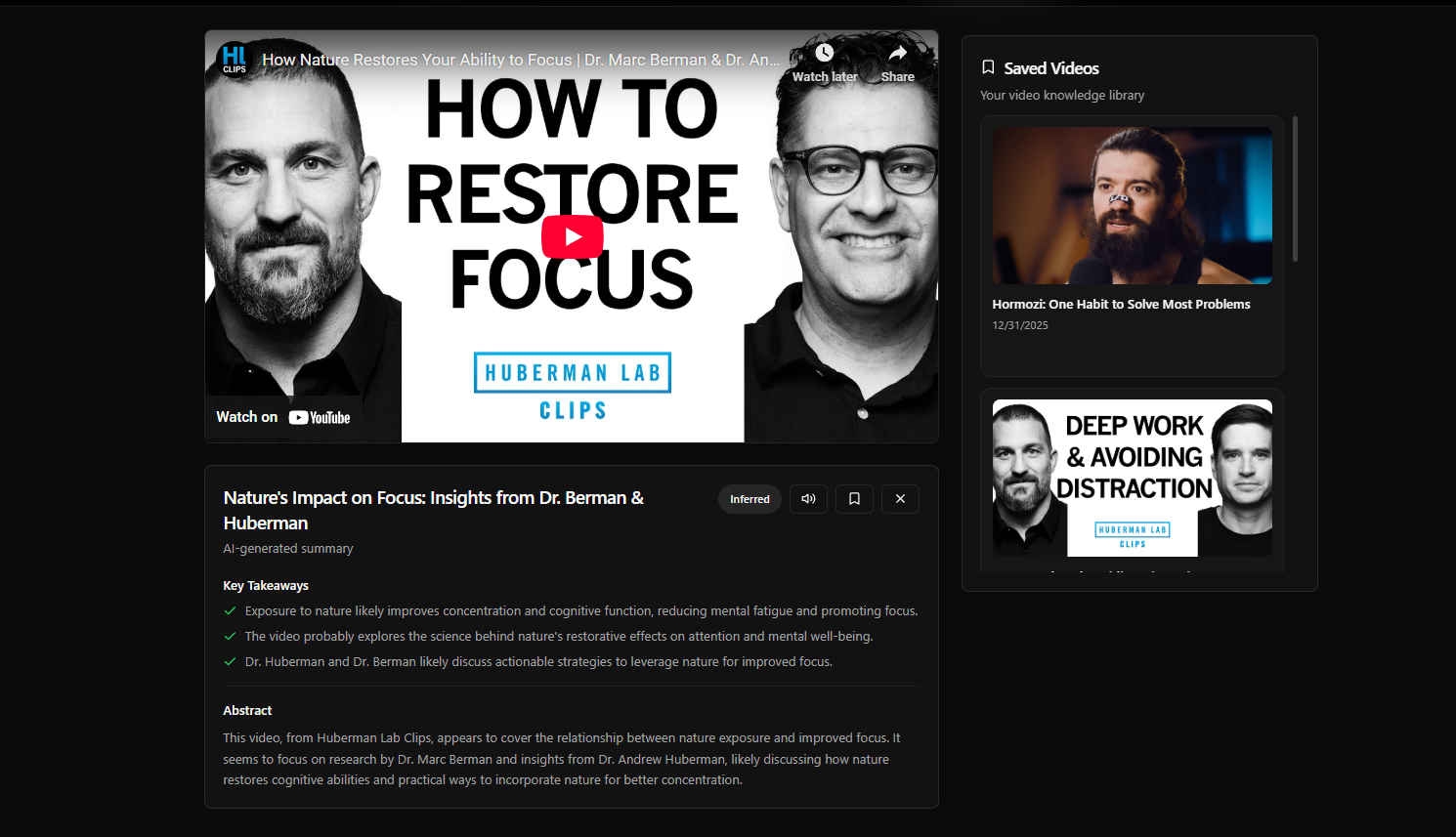
VoxPilot is a voice-controlled knowledge base for YouTube videos. Users can paste or speak a YouTube link and instantly receive a structured AI summary containing a clear title, three key takeaways, and a concise abstract. Summaries can be read aloud using a natural human voice, saved to a personal library, and managed entirely through voice commands with built-in safety confirmations. To build trust, VoxPilot clearly differentiates between two types of analysis:
Full Analysis when video transcripts are available Inferred Analysis when captions are missing, and only metadata is used.
This distinction prevents AI hallucinations while still delivering value, even when data is incomplete.
How we built it
VoxPilot is designed as a real-world SaaS application, not a prototype. The frontend is powered by Next.js using the App Router pattern with React, creating a responsive and modern dashboard experience. Google Gemini handles all the intelligence layer, performing video summarization, intent understanding, and structured output generation. ElevenLabs provides natural, human-like voice output for short, explicit interactions. Supabase manages user authentication and persistent data storage, while the Web Speech API enables real-time speech-to-text for voice commands. Voice output is intentionally concise and user-triggered to remain efficient and reliable within free-tier API limits. The architecture follows a fail-soft design philosophy where transcript availability is treated as optional rather than mandatory. When transcripts exist, Gemini generates high-confidence summaries from the full content. When transcripts are unavailable, the system falls back to metadata-based inference using video titles, descriptions, and channel names, clearly labeling the result as inferred.
System Architecture / End-to-End Pipeline:
User (Text or Voice Input)
|
v
Speech-to-Text (Web Speech API)
|
v
Intent Detection + Reasoning (Google Gemini)
|
|-- If YouTube Link -->
| Fetch Transcript (if available)
| OR Fallback to Metadata
| Generate Structured Summary
|
|-- If Action Command -->
| Validate Intent
| Request Confirmation (if destructive)
|
v
Dashboard UI Update (Next.js + React)
|
v
Optional Voice Response (ElevenLabs)
This pipeline ensures Gemini performs all heavy reasoning while ElevenLabs handles only presentation. The system remains transparent and safe even when working with incomplete data.
Challenges we ran into
One major challenge was handling YouTube videos without captions. Many AI solutions either fail completely or hallucinate content in these scenarios. We solved this by implementing graceful degradation to metadata-based inference, always labeling results clearly so users understand what type of analysis they received. Another significant challenge was managing API limits on free tiers. This influenced critical design decisions like keeping voice responses short, requiring explicit voice triggers for audio output, and adding confirmation flows for destructive actions like deleting saved content. These constraints actually shaped VoxPilot into a more realistic and production-ready system rather than a resource-hungry demo.
Accomplishments that we're proud of
We built a complete voice-first SaaS workflow that integrates Gemini and ElevenLabs in a practical, non-gimmicky way. The system implements confidence-aware AI outputs that distinguish between full transcript analysis and metadata inference. Voice control works seamlessly with safety confirmations for critical actions. Most importantly, we designed an architecture that avoids hallucinations by default through transparent confidence labeling and graceful fallback mechanisms.
What we learned
We learned that transparency matters more than perfection when building AI systems. Clearly communicating uncertainty builds more trust than hiding limitations behind a polished interface. We also discovered how to design AI-powered products that respect real-world constraints like API quotas, missing data, and user expectations while still delivering meaningful value. The best AI products are honest about what they know and what they infer.
What's next for VoxPilot
Future directions include implementing deeper semantic analysis when full transcripts are available, enabling smarter follow-up interactions grounded in verified content rather than generic responses, and expanding beyond YouTube into a general voice-driven knowledge workspace. We also plan to add collaborative features where teams can share and discuss analyzed content, and introduce custom AI personas that adapt to different learning styles and use cases.
Built With
- app-router
- elevenlabs-text-to-speech-api
- google-cloud-(gemini-/-vertex-ai)
- google-gemini-api
- google-web-speech-api
- javascript
- nextjs
- pnpm
- postgresql
- react
- supabase
- tailwind
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.