-
-
HeroPage
-
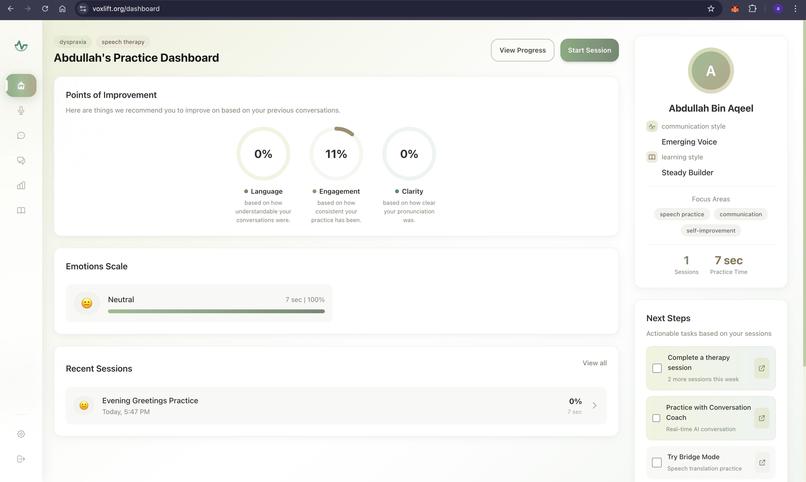
Dashboard
-
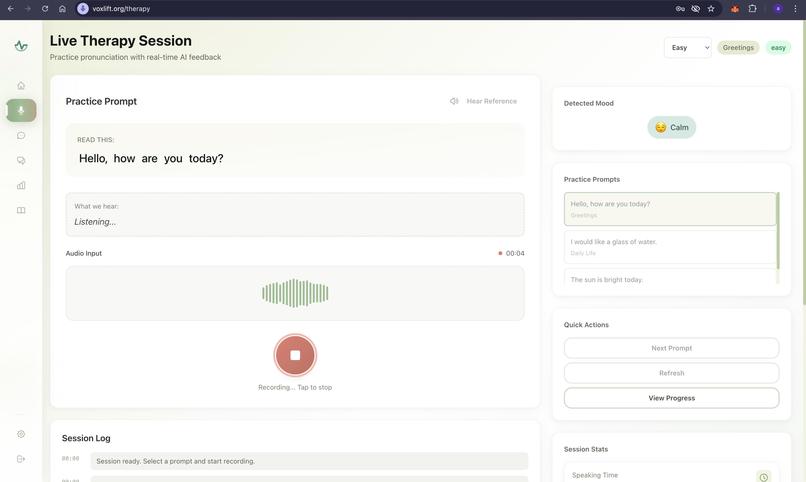
Therapy
-
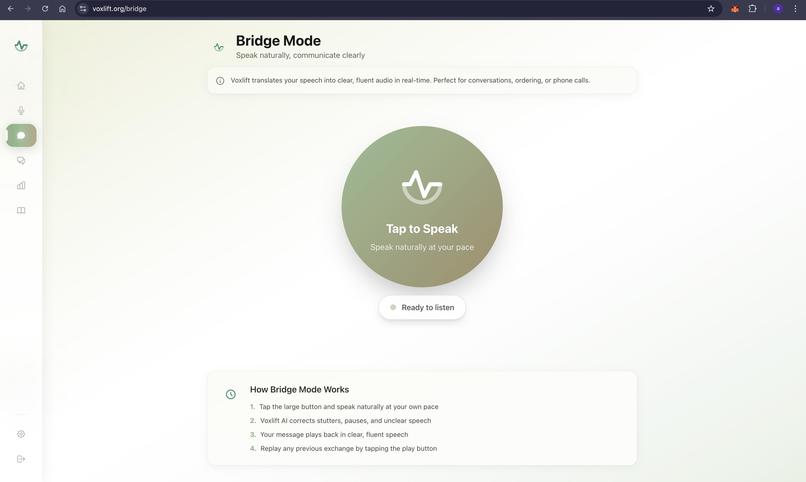
Bridge
-
Conversation
-
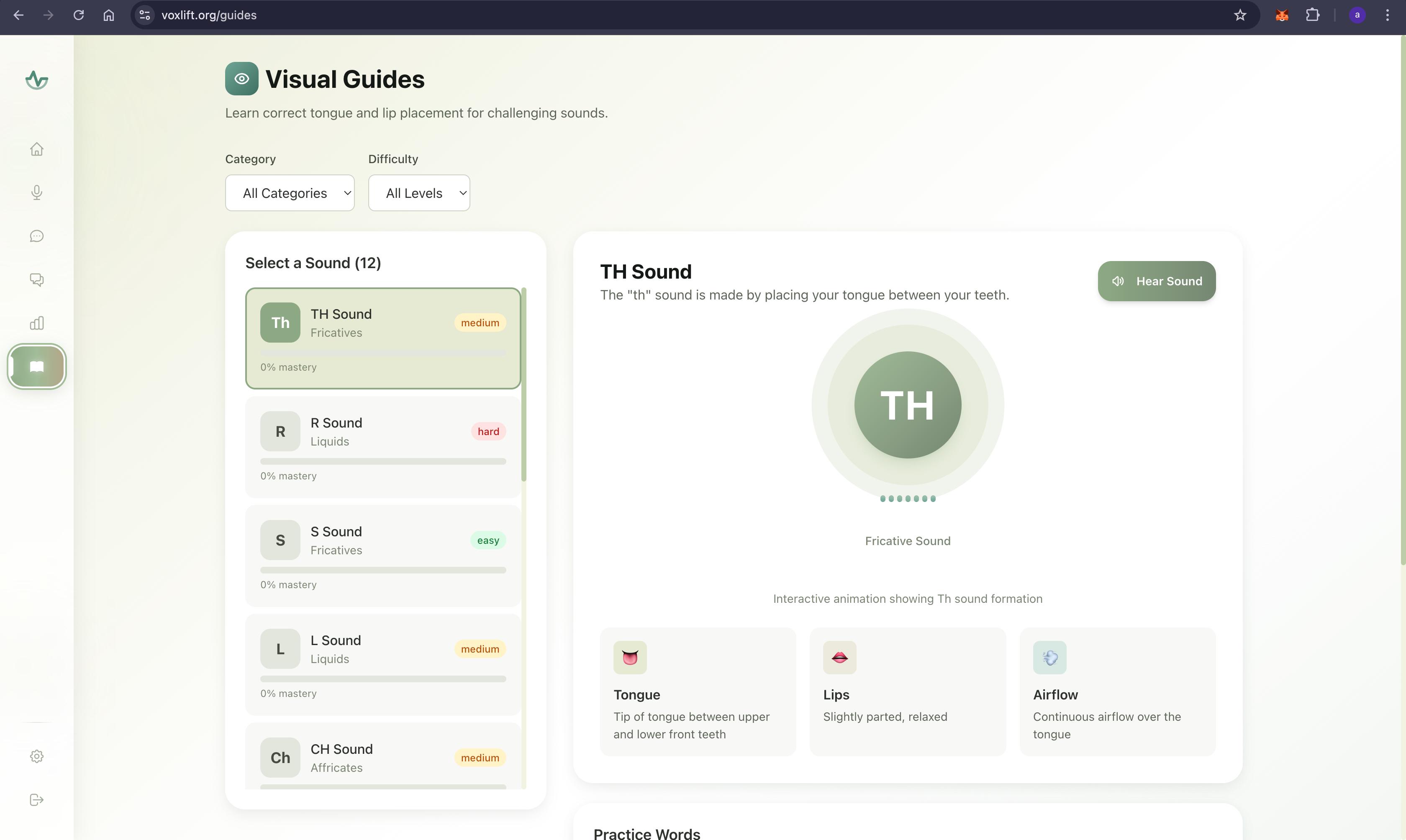
Guides
-
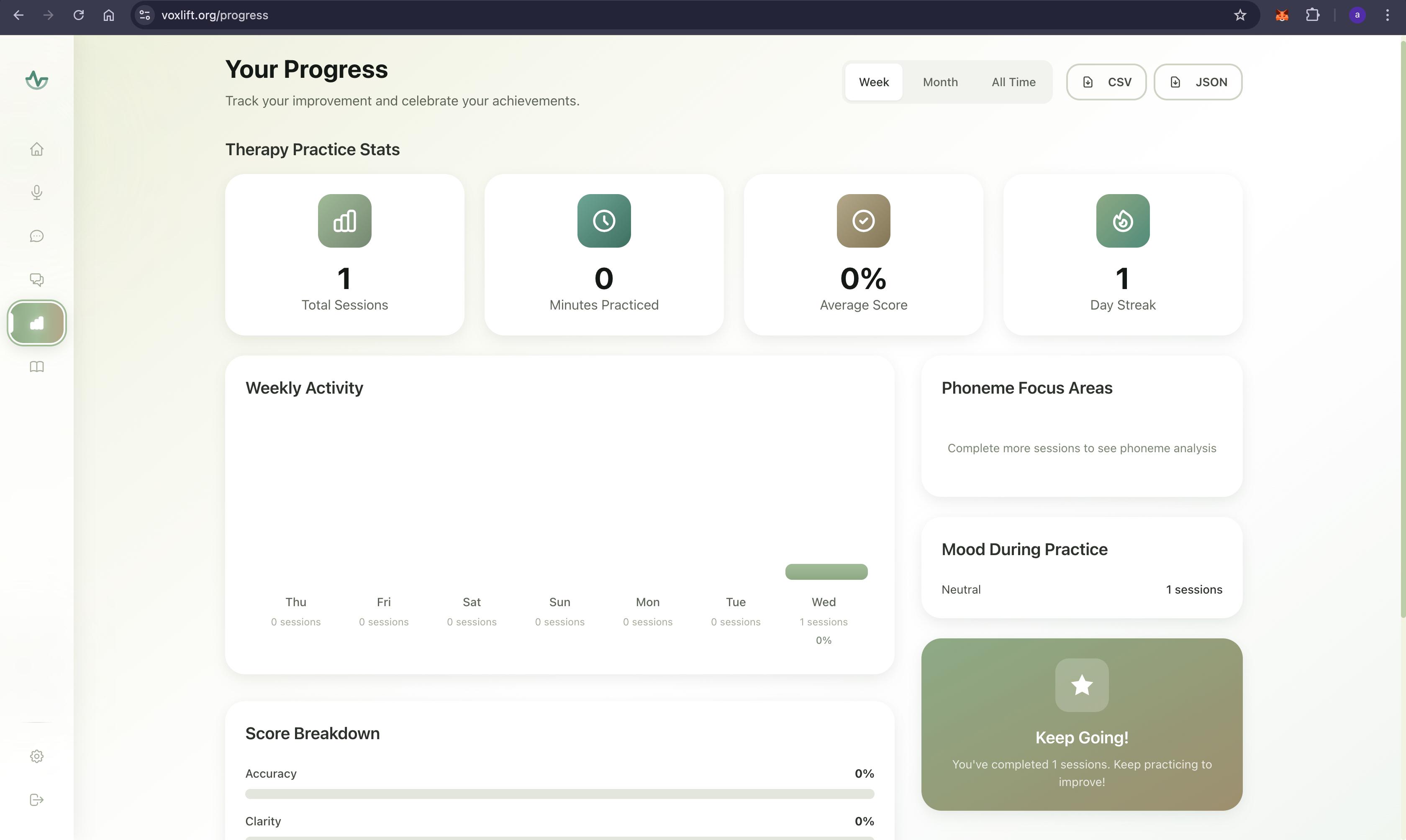
Progress
Inspiration
Communication is not just a utility; it is a fundamental human right. Yet, for millions of individuals living with motor speech disorders—such as Dyspraxia, Apraxia, ALS, and Parkinson's—the simple act of being understood is a daily, often agonizing, battle. Traditional speech therapy is the gold standard, but it faces critical limitations: it is expensive, geographically inaccessible for many, and limited to brief scheduled sessions. We asked ourselves: What if we could build a speech therapist that never sleeps? And further, what if we could build a bridge that allows someone to speak with their own voice, fluently and clearly, in real-time? VoxLift was born from this vision. We wanted to leverage the latest advancements in Multimodal AI to create a dual-purpose platform: one that rehabilitates speech over time, and one that empowers immediate communication today.
What it does
VoxLift is a comprehensive, accessibility-first platform designed to restore the power of voice. It functions through two distinct, high-impact modes:
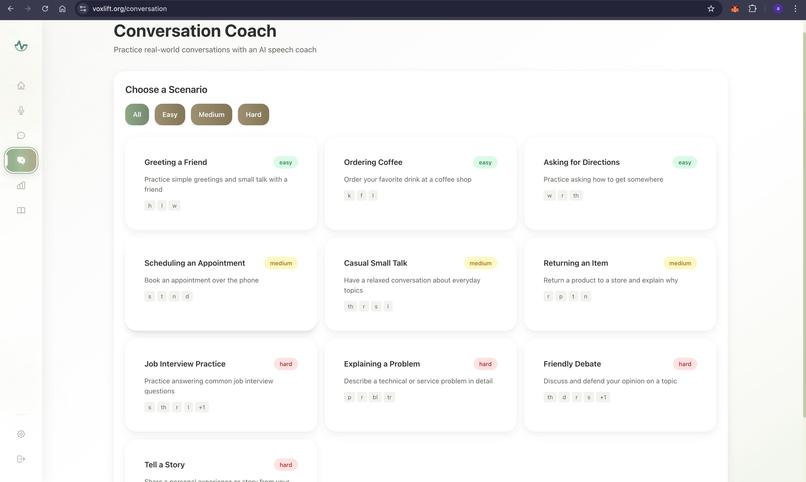
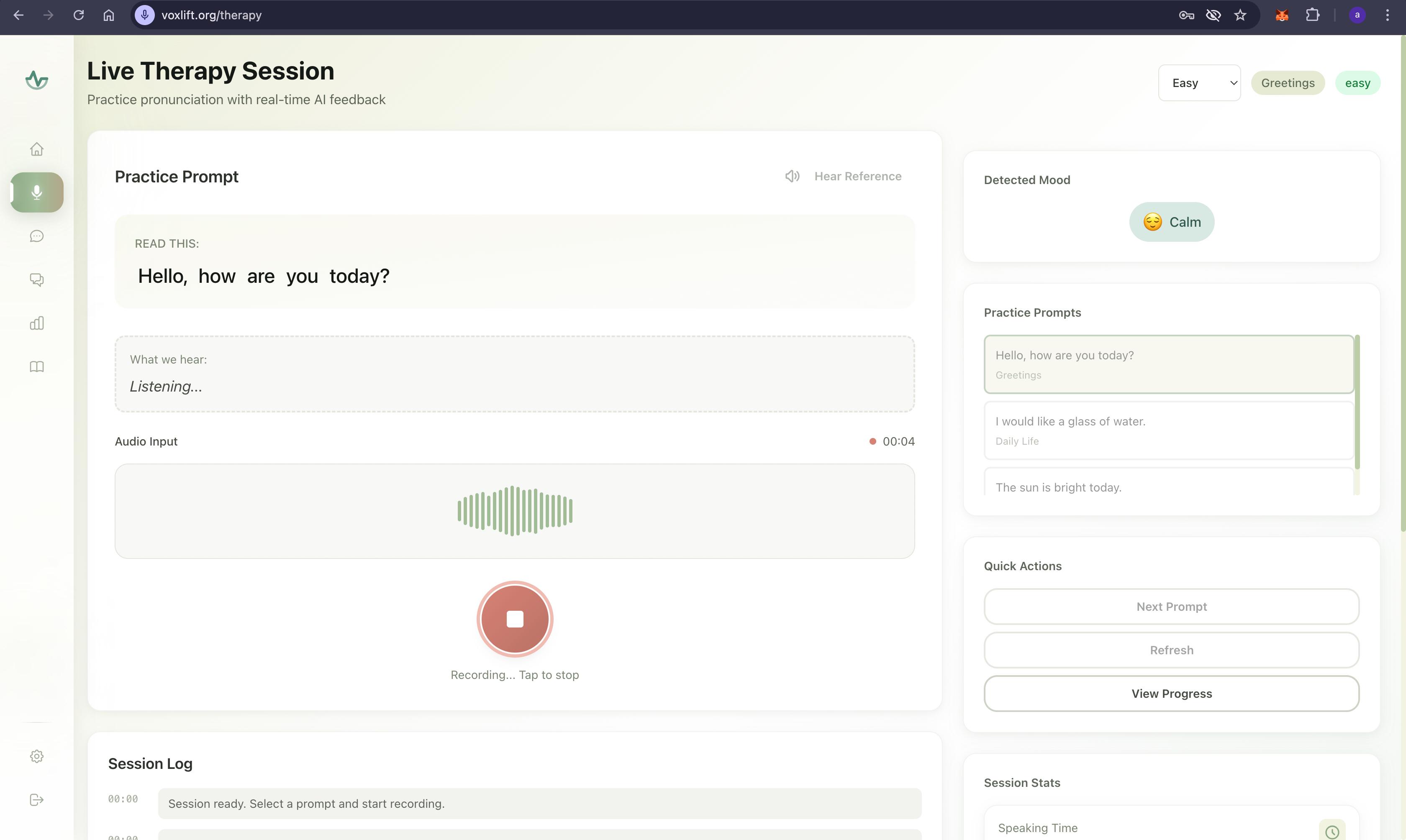
- Therapy Mode (The AI Clinician):
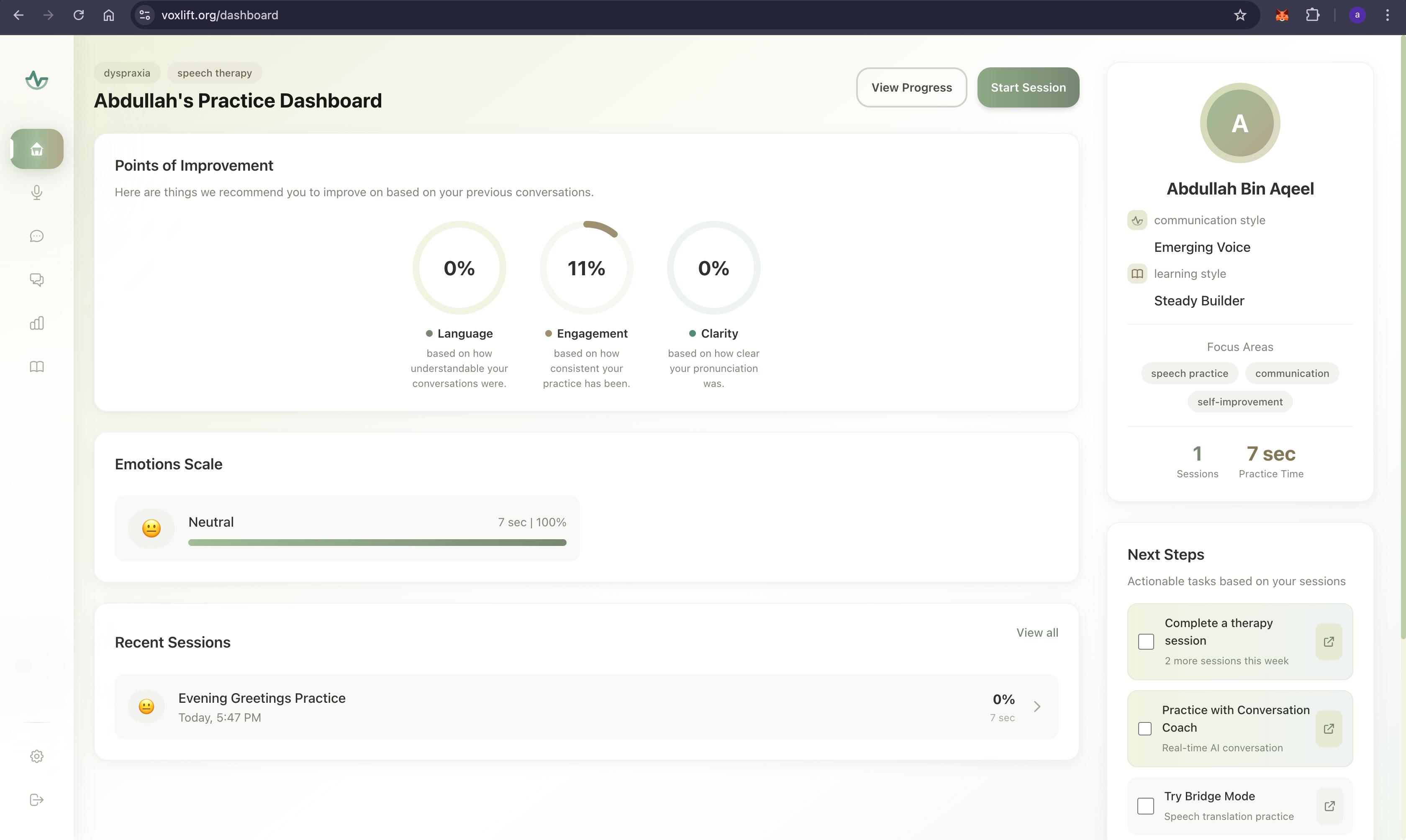
- Acts as an intelligent, always-available speech therapist.
- Utilizes advanced audio processing to provide real-time, multimodal feedback on pronunciation, rhythm, and clarity.
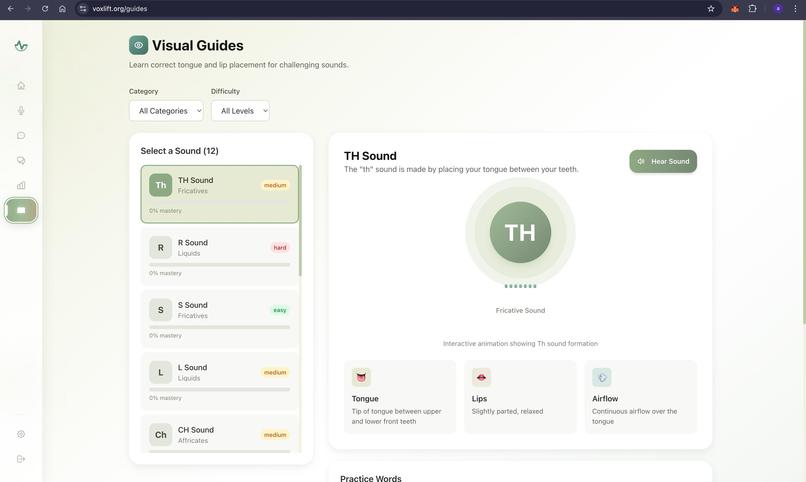
- Offers visual cues for tongue and lip placement, gamifying the rehabilitation process to encourage consistent practice.
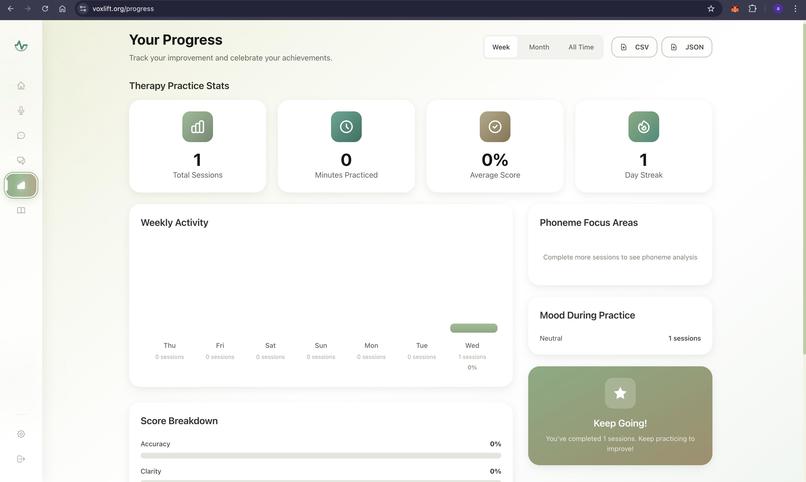
- Delivers actionable, phoneme-level insights to help users rebuild their motor speech planning pathways.
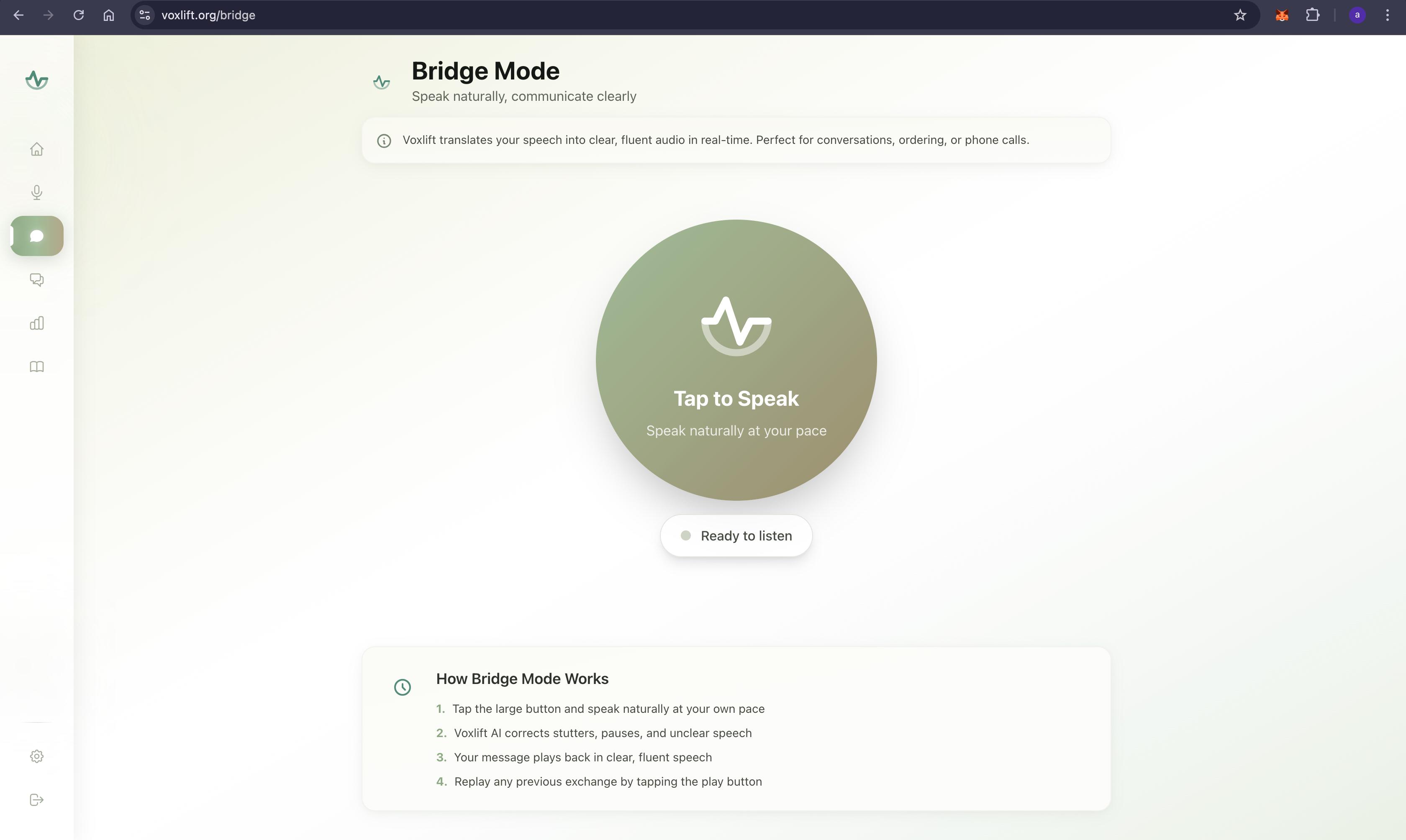
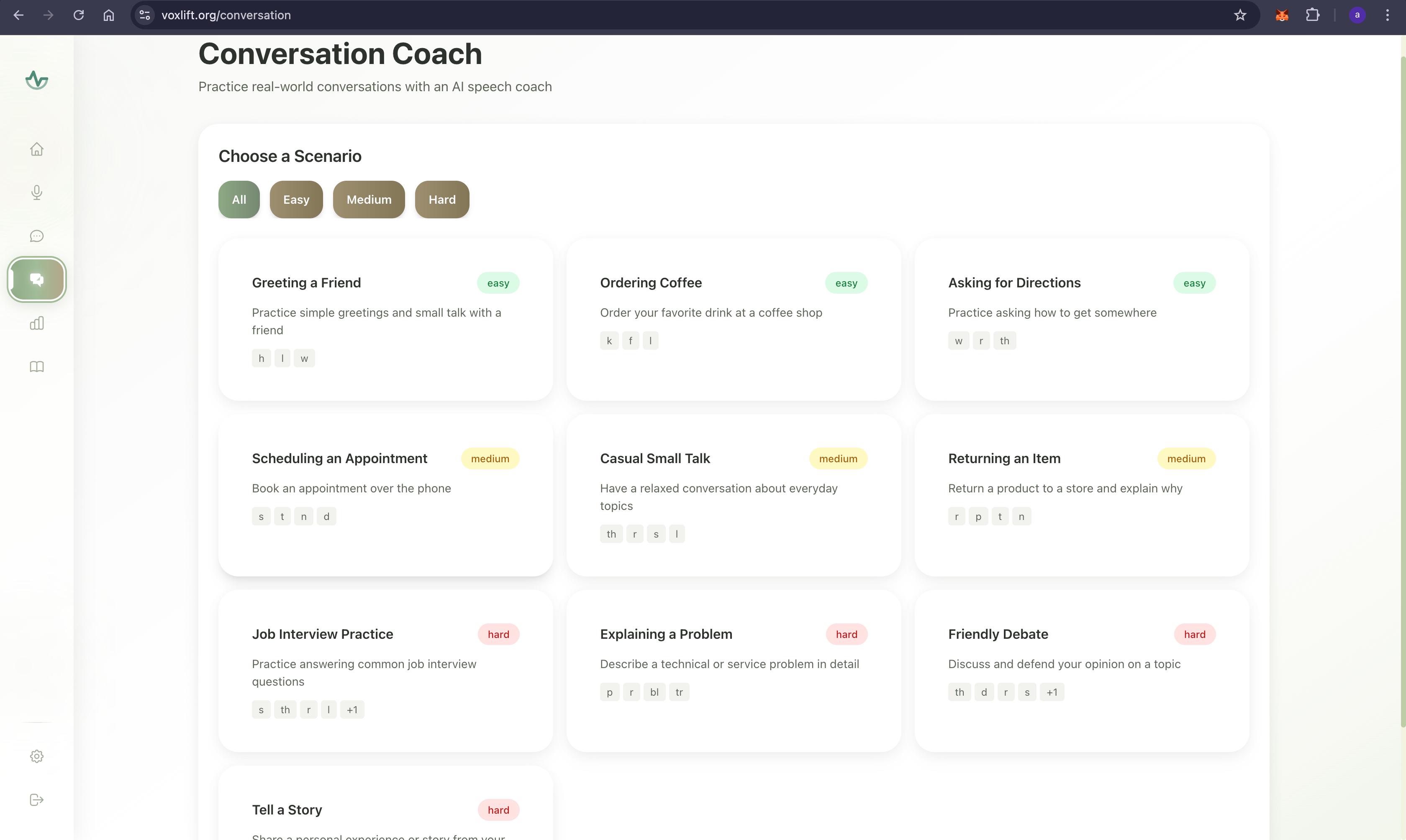
- Bridge Mode (The Real-Time Companion):
- Serves as an assistive communication layer for daily interactions.
- Users speak naturally—regardless of stuttering, slurring, or pauses—and our AI engine instantaneously interprets the semantic intent.
- It reconstructs the fragmented speech into fluent, grammatically correct sentences.
- The corrected text is immediately synthesized into ultra-realistic, empathetic speech using ElevenLabs, allowing the user to participate in conversations with confidence and dignity.
How we built it
VoxLift is not just a wrapper; it is a complex orchestration of state-of-the-art AI technologies, built on a robust, scalable architecture:
- Core Intelligence (Google Cloud Vertex AI): We architected our NLP pipeline effectively using Gemini 1.5 Pro. Its multimodal capabilities allow us to process audio and text simultaneously, enabling a deeper understanding of "disordered" speech patterns that traditional STT models miss.
- Voice Synthesis (ElevenLabs): To ensure the voice output feels human and personal, we integrated ElevenLabs' low-latency API. This transforms the corrected text into emotive audio that captures the user's intended tone, not just their words.
- Frontend Engineering (Next.js 14 & Tailwind): We built a highly responsive, accessible interface using Next.js App Router. The UI is designed with Framer Motion to provide calming, fluid interactions that reduce the anxiety often associated with speech therapy tools.
- Data Layer (Prisma & PostgreSQL): A secure backend manages sensitive user data, therapy progress tracking, and personalized configuration settings.
Challenges we ran into
- The "Latency vs. Quality" Trade-off: In Bridge Mode, every millisecond counts. Orchestrating a pipeline that captures audio, transcribes it, corrects it via LLM, and synthesizes audio—all while maintaining conversational speed—required aggressive optimization of our API chains and edge function implementation.
- Deciphering Non-Standard Speech: Standard Speech-to-Text models are trained on fluent speech. They frequently fail for our target demographic. We had to engineer a prompt strategy that instructs Gemini to look for intent amidst phonological errors, effectively using context implementation to "repair" the broken speech input.
- Designing Empathetic UI: Medical interfaces are often sterile and discouraging. Our challenge was to design a UI that felt premium and empowering—"consumer-grade," not "clinical-grade"—while still providing dense technical feedback on speech performance.
Accomplishments that we're proud of
- Multimodal Integration: Successfully implementing a pipeline where audio input directly informs the LLM's context, significantly rewriting the rules for accessibility tools.
- Real-Time Performance: achieving a usable latency for the Bridge Mode, making it a viable tool for actual face-to-face conversation.
- Empowering Design: Creating a product that users want to use. The feedback on our visual cues and "glowing" interaction design has proven that accessibility tools can be beautiful.
What we learned
- The Era of Intent-Based Computing: We learned that accessibility isn't just about recognizing words; it's about recognizing intent. LLMs are the key to unlocking this, serving as a translation layer between different cognitive and motor capabilities.
- Simplicity is Complex: Hiding the immense complexity of our AI pipeline behind a single "Record" button was our biggest UX lesson. The user shouldn't care about the tech stack; they just want to be heard.
What's next for Voxlift
- Personal Voice Cloning: We plan to integrate voice cloning so users with degenerative conditions (like ALS) can "bank" their healthy voice and use it in Bridge Mode forever.
- Therapist Portal: We are building a dashboard for certified speech language pathologists (SLPs) to remotely assign exercises and monitor their patients' progress through VoxLift.
- Mobile Native: Porting our optimized web core to React Native to ensure VoxLift is accessible anywhere, even offline.
Built With
- amazon-web-services
- elevenlabs`
- gemini`
- google-cloud`
- next.js`
- prisma`
- tailwindcss`
- typescript`
- vertex-ai`
- vox




Log in or sign up for Devpost to join the conversation.