Inspiration
As students from India, we have noticed countless number of senior citizens who suffer from dementia and Parkinson's These diseases are often diagnosed too late, in communities where specialist care is scarce and clinical infrastructure is not up to dadte. That personal reality is what drove us to build VoxClinical, because anyone is able to record a simple recording of their voice with their smartphone, eliminating the use of specialized neurologists which many don't have access to.
What it does
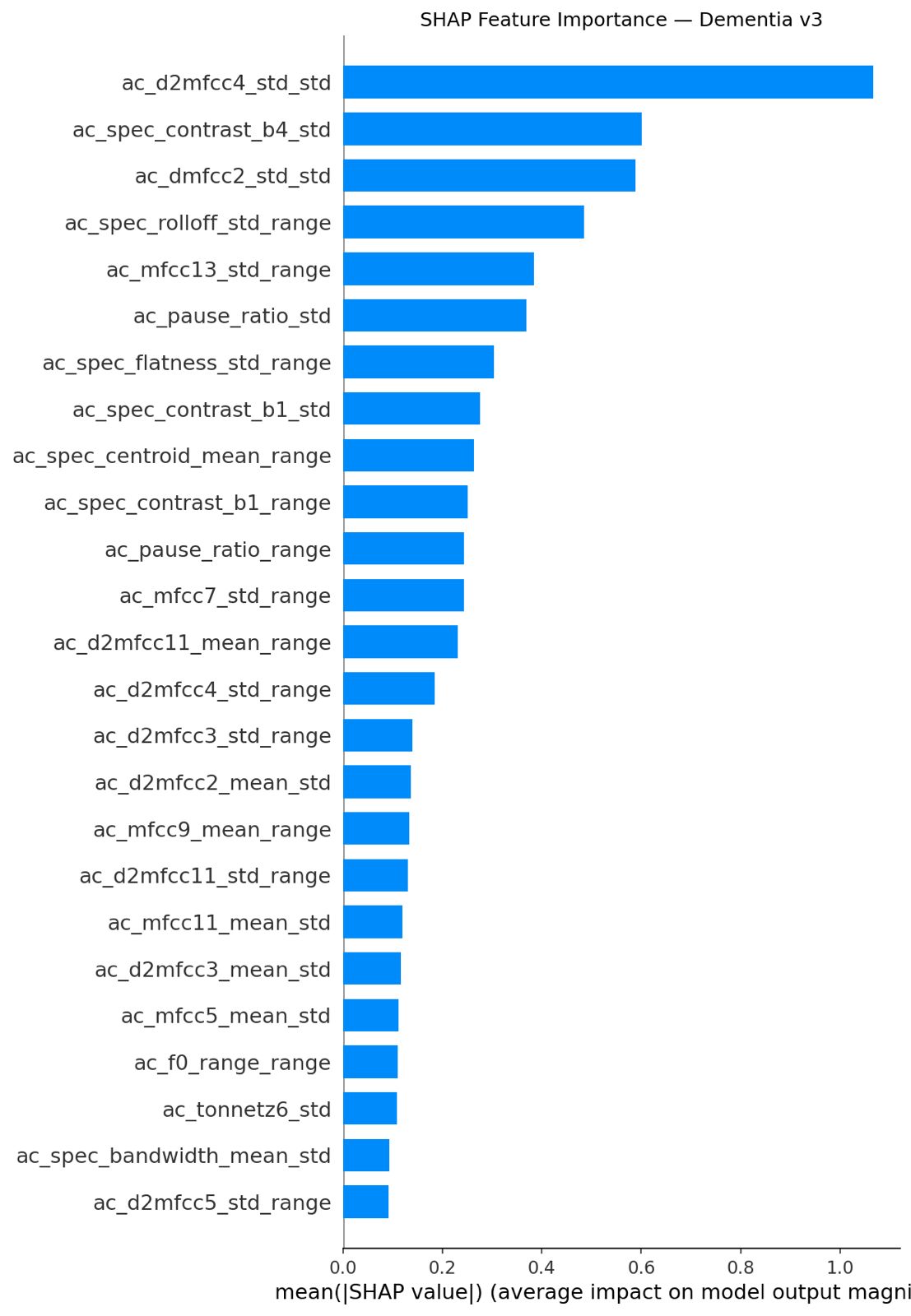
Our product analyzes a short voice recording and automatically screens for both dementia and Parkinson's disease without any imaging or clinical tests. It extracts various acoustic and linguistic features from the audio, runs them through machine learning models trained on real patient data, and produces an instant, interpretable risk report that breaks down exactly which speech markers drove the result.
How we built it
For the frontend, we built the interface using TypeScript and React designed to be clean and accessible so anyone can upload a recording and read their results without any technical background.
For the backend, we used Python to for all the model creation and transcribed audio with OpenAI's Whisper, extracting acoustic features with librosa, processing the transcript through spaCy and NLTK for linguistic analysis, and running the output through our 2 trained machine learning models.
For the models themselves, we built two separate classifiers. We used a Random Forest for Parkinson's and a Support vector machine for Dementia trained on real clinical speech datasets and deployed via a Fast API that connects the frontend to the prediction pipeline.
Challenges we ran into
The main challenge which we came across was finding datasets that integrated both acoustic and lingustic data. For many datasets we faced restrictions that wouldn't allow us to use, while other datasets were very noise-prone and could not be used to create good models.
Another important challenge was extracting the linguistic features. Using the base model of whisper resulted in lower quality extractions and hence inaccurate models. However, using the more advanced version would take longer, and given the time constrains made it simply not possible.
Accomplishments that we're proud of
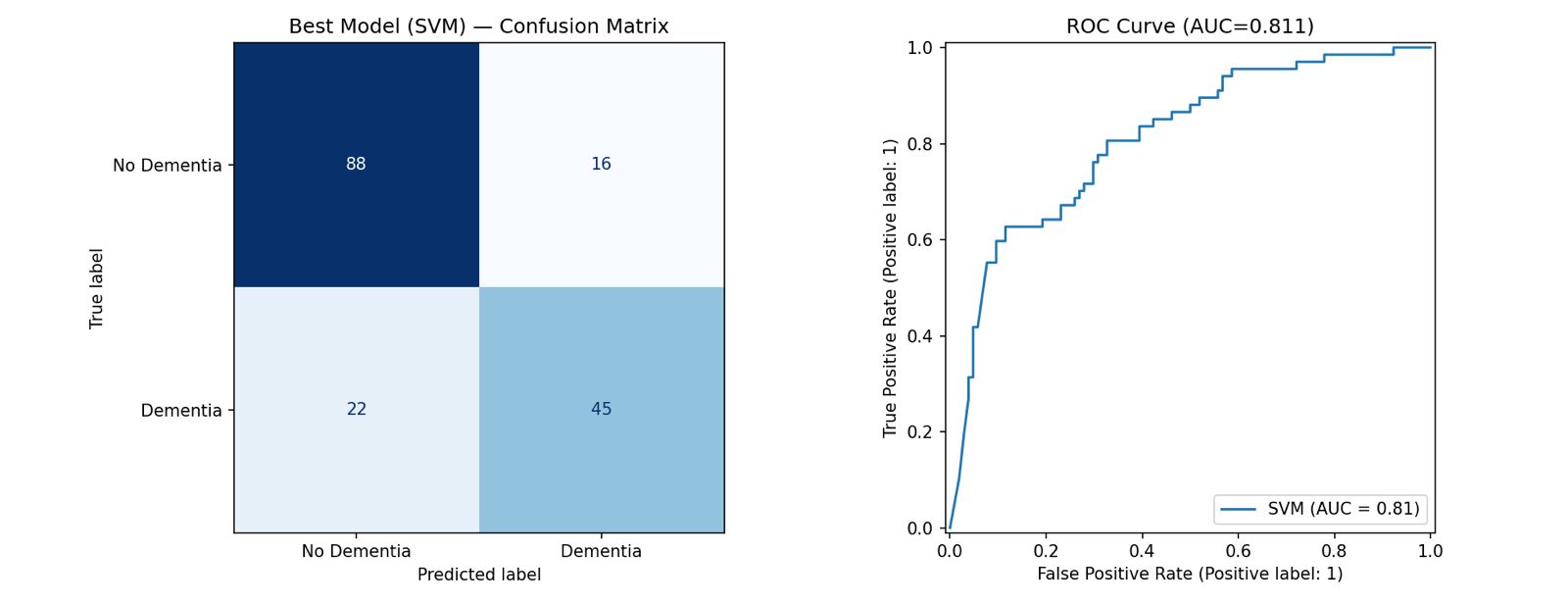
We are proud of building a full end-to-end pipeline entirely from from raw audio ingestion to feature extraction to model inference to a clean report. Getting three parallel feature extraction paths to run reliably and also achieving ROC-AUC scores above 0.81 on both models.
What we learned
We learned more about frontend development through React and Typescript, and how to handle acoustic and lingustic data using new tools like Whisper, spaCy and NLTK.
What's next for VoxClinical
We hope to expand our scope beyond just Parkinson's and Dementia and focus on other pressing neurodegenerative diseases such as Alzheimer's, Multiple Sclerosis and many more which face similar problems. We also hope to work with larger and more diverse datasets to capture a bigger target audience while also achieving better model prediction metrics.
Built With
- llms
- ml
- natural-language-processing
- python
- rag
- react
- spacy
- typescript

Log in or sign up for Devpost to join the conversation.