-
-

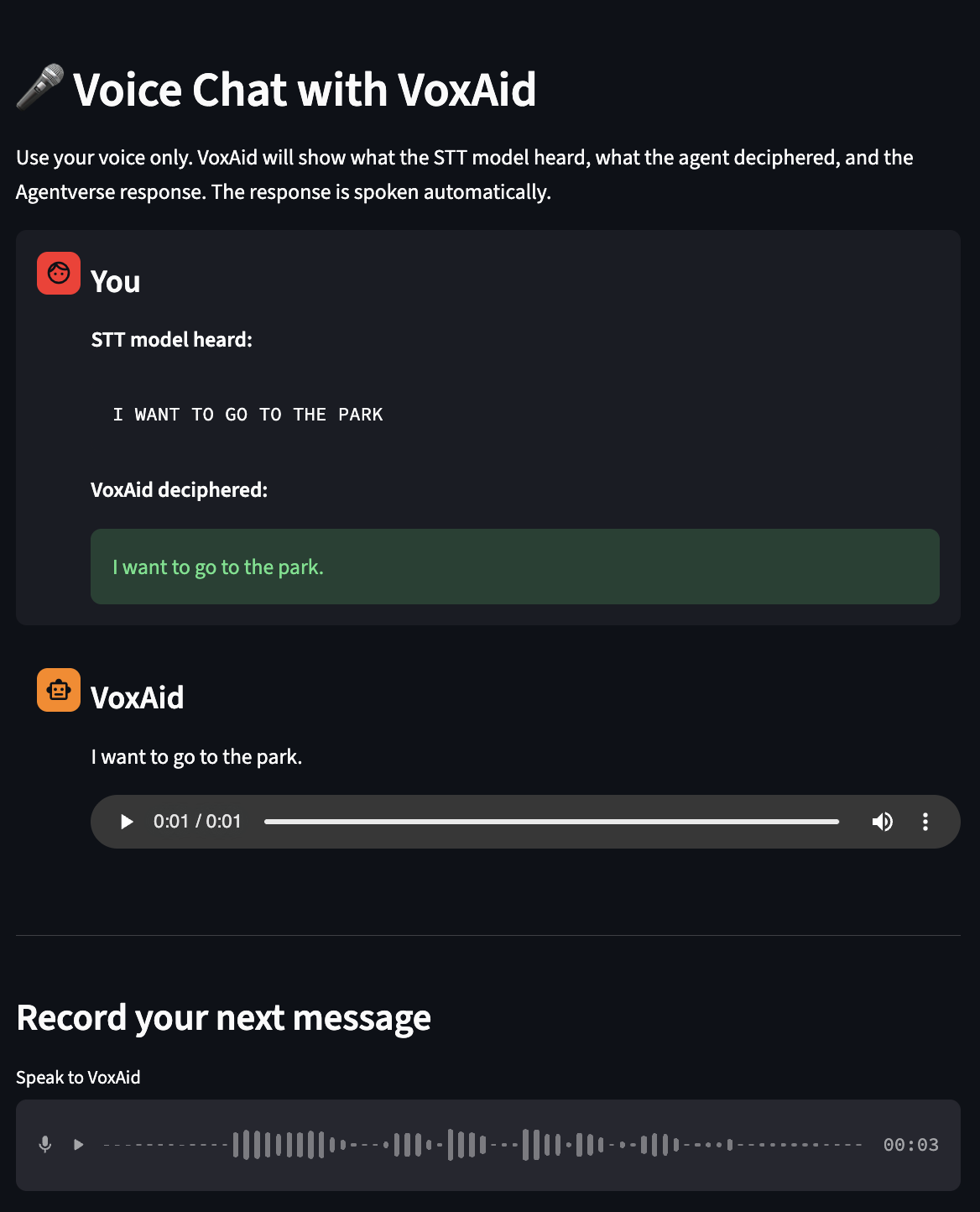
Example 1 of 3 for recordings of people with speech impediments, with the raw output, the Claude corrected output, and the Deepgram output.
-
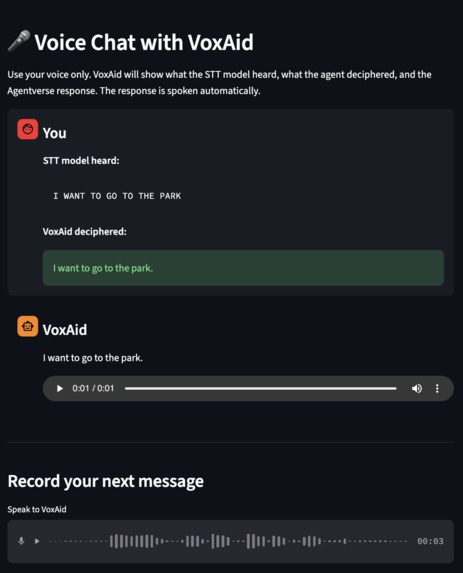
An example of a recording coupled with the raw output, Claude corrected output, and Deepgram's voice agent speaking the text back.

Inspiration
People with ALS, cerebral palsy, stroke, and other conditions that cause dysarthria often rely on human interpreters to communicate in daily life - a dependency that limits independence and isn't always available. Existing voice recognition software is trained almost exclusively on typical speech, making it largely unusable for this population. We wanted to build a tool that bridges that gap: a digital interpreter that anyone can access.
What it does
VoxAid takes audio input from a user with a speech impairment, runs it through a Wav2Vec2 speech recognition model fine-tuned on dysarthric speech, passes the raw transcript to Claude for semantic reconstruction, and returns both a cleaned text output and a natural-sounding voice response generated by Deepgram Aura. The result is a full speech-to-speech pipeline that takes unclear input and produces clear, natural output.
How we built it
We built a FastAPI backend that orchestrates three AI systems: a Wav2Vec2 model with a LoRA adapter fine-tuned on the TORGO dysarthric speech dataset - the exact architecture proposed in a June 2026 Interspeech paper published two days before the hackathon - for transcription, Claude for semantic correction and reconstruction of the raw transcript, and Deepgram Aura for text-to-speech output. The frontend is a Streamlit app that records audio in the browser, sends it to the backend, and displays the raw transcript, corrected text, and generated audio side by side. We used the TORGO database, containing 5,500+ audio clips from dysarthric speakers paired with correct transcriptions, as our training data.
Challenges we ran into
Training a full fine-tuned model proved far more difficult than anticipated. We spent several hours training a Wav2Vec2 model on Google Colab, repeatedly running into GPU out-of-memory errors, Google Drive storage limits from checkpoint accumulation, and Colab session crashes that wiped in-memory data. After implementing workarounds for all of these, we discovered the model had been training on corrupted labels - a tokenization mismatch between the large and base model vocabularies caused every label to map to , so the model minimized loss by learning to output only blank tokens. Six hours of compute produced a model that transcribed nothing. We pivoted to a LoRA adapter approach, which fine-tunes only a small set of adapter weights rather than the full 90M parameter model, resolving both the compute and stability issues, while potentially sacrificing the accuracy potential of our original approach.
Accomplishments that we're proud of
We're proud of building a working end-to-end speech accessibility pipeline, and for attempting to tackle a problem that no current STT model can accurately do at the level that we are trying to do it. We attempted to optimize for something that nearly every other STT model doesn't, and in the process we learned why this is the case: it's incredibly difficult to decipher audio that even the human ear has a hard time deciphering. The Claude correction step produces genuinely impressive results - recovering words like "February," "checkup," "therapist," and "injection" from nearly unintelligible phonetic input. We're also proud of engaging seriously with the academic literature, building on architecture from a June 2026 Interspeech paper released two days before the hackathon. Most of all, we're proud of building a prototype that, if developed further, could meaningfully improve the daily lives of people with dysarthria and other speech impairments.
What we learned
Fine-tuning speech recognition models for dysarthric speech is a hard, data-hungry problem that requires significantly more compute than a hackathon environment provides. We learned that CTC-based models have a failure mode called CTC collapse where they optimize for blank token output rather than learning real transcriptions - and that preventing it requires careful learning rate tuning and correct label tokenization from the start. We also learned that LLM post-processing is a powerful and underexplored complement to ASR - Claude's semantic reasoning recovers meaning that acoustic models miss entirely, and no academic benchmark we found measures this combined approach.
What's next for VoxAid
The immediate next step is collecting higher quality dysarthric speech data and training a properly fine-tuned model with sufficient compute. Beyond that, the most impactful feature would be per-user personalization, which would consist of a calibration session where a user records 50-100 short phrases, allowing the model to adapt to their specific speech patterns. For users who have recordings of their voice before their impairment developed, voice cloning via ElevenLabs or a similar service could allow VoxAid to speak in their own voice rather than a generic synthetic one, restoring not just communication, but identity.
Built With
- claude
- deepgram
- fetchai
- googlecolab
- lora
- python
- streamlit
- vscode
- wav2vec2



Log in or sign up for Devpost to join the conversation.