-
-

Problem
-
Solution
-
App Page
-
Priyas' story
-
Map
-
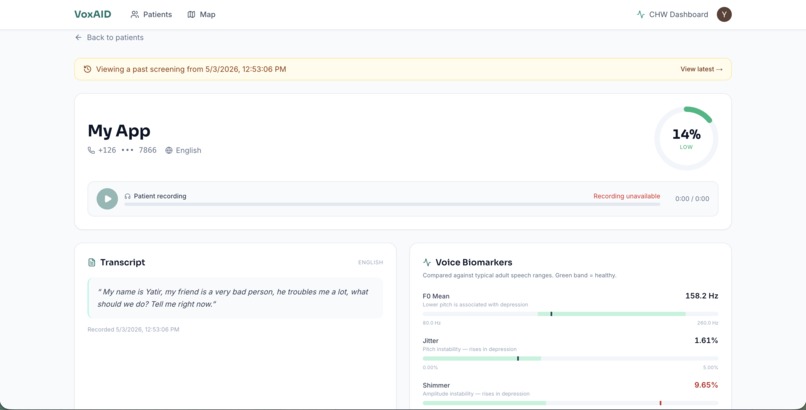
Caller Page 1
-
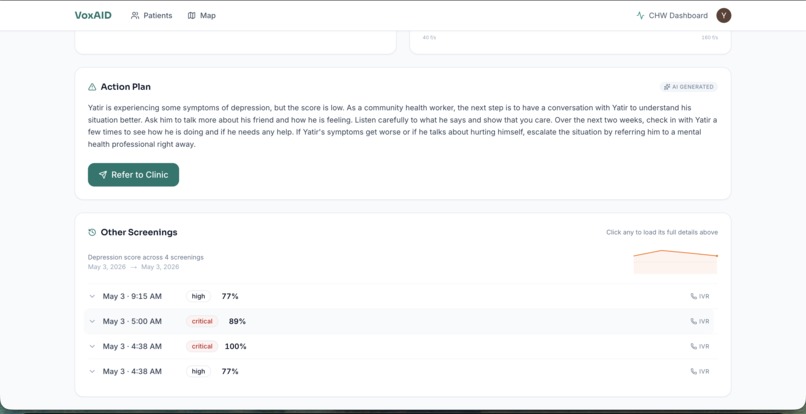
Caller Page 2
-
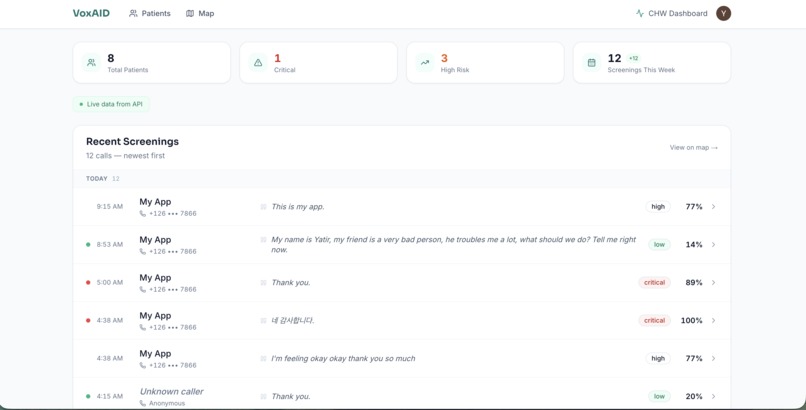
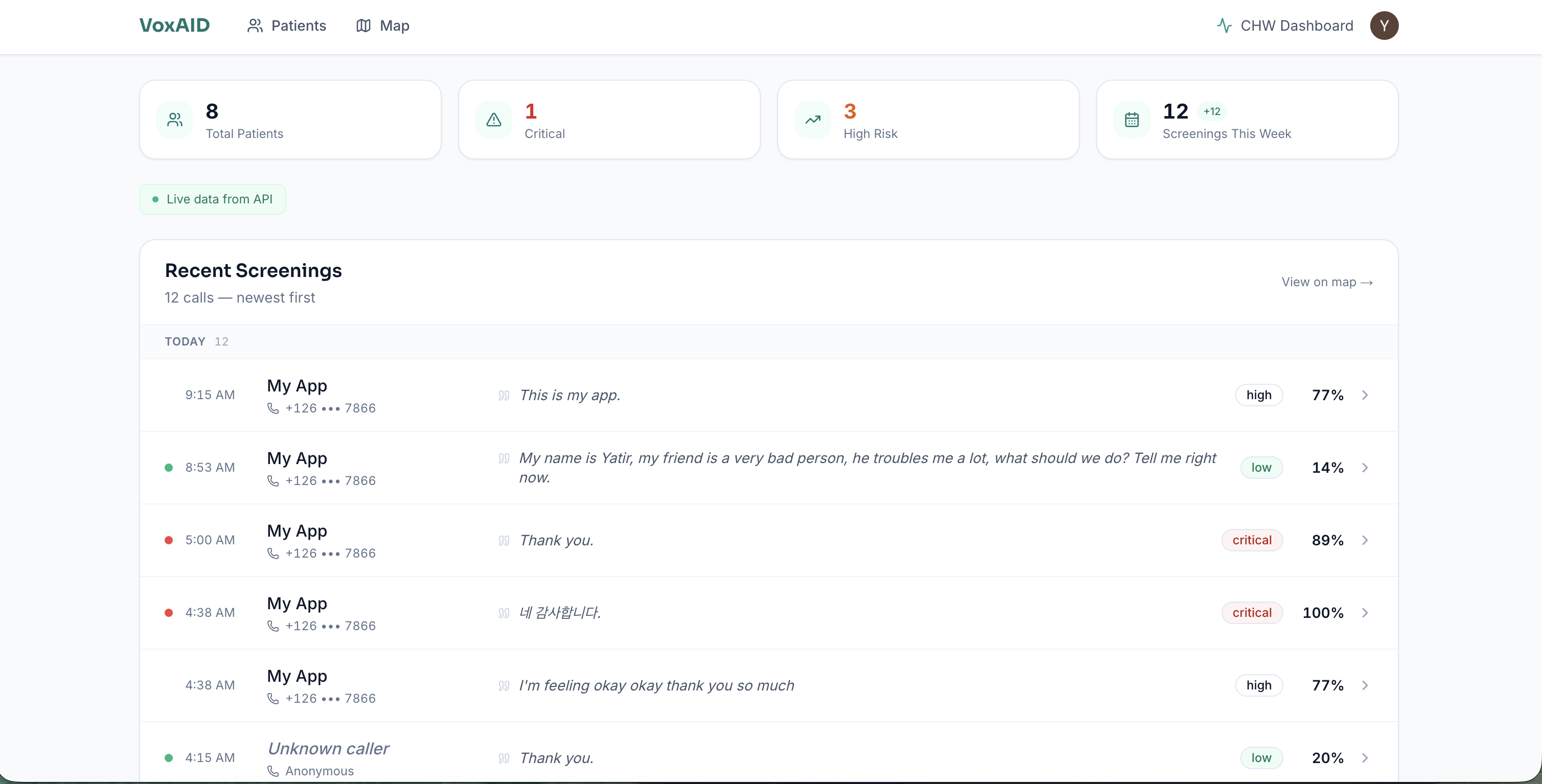
Dashboard


Inspiration
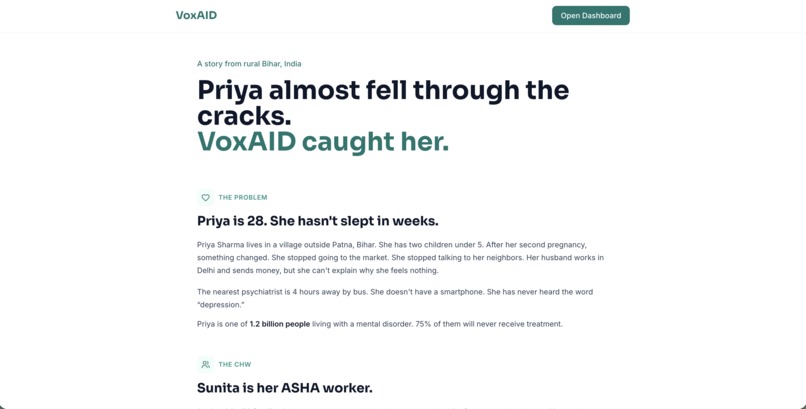
A close friend's mother lives in a village in Uttar Pradesh. The nearest psychiatrist is 4 hours away. When she stopped eating and stopped talking to neighbors, nobody knew what was wrong. An ASHA worker visited her house every month for immunization checks, but she had no tool to screen for depression. No questionnaire in Hindi. No app. Nothing.
I looked up the numbers. 1.2 billion people worldwide live with mental disorders. 75% get zero treatment. Not because we lack the science, but because the delivery infrastructure doesn't exist where they live. India has 1 million community health workers visiting homes every single month, carrying paper checklists for nutrition and immunization, but zero diagnostic tools for mental health.
Then I found the research. Cummins et al. (2015), Low et al. (2020). Depression changes your voice in measurable ways. Lower pitch. More pauses. Breathier quality. Higher jitter and shimmer. These aren't subtle. They're clinically validated biomarkers that can be extracted from 25 seconds of speech using signal processing.
The realization: you don't need a smartphone. You don't need internet. You don't need literacy. You just need a phone call.
What it does
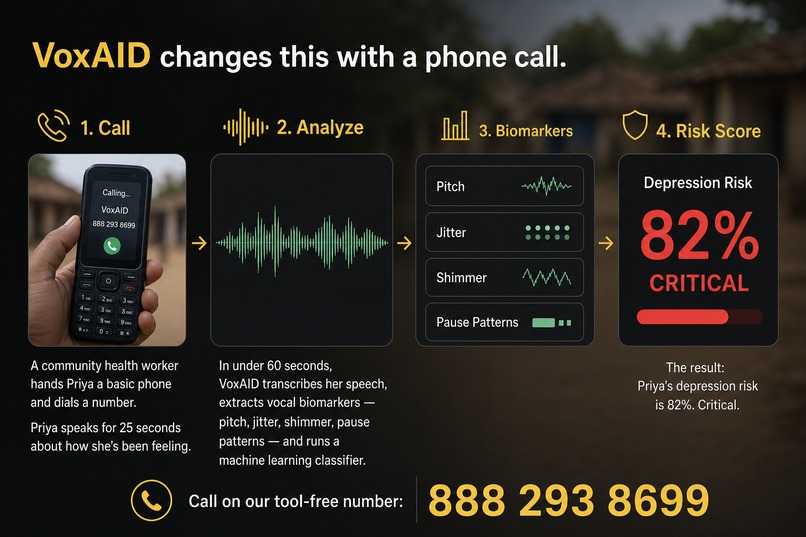
A community health worker hands a patient any phone and dials the VoxAID number. The patient speaks for 25 seconds about how they've been feeling. That's it.
In under 60 seconds, VoxAID:
- Transcribes the speech in the patient's language (99+ languages via Whisper, with bilingual code-switching preserved)
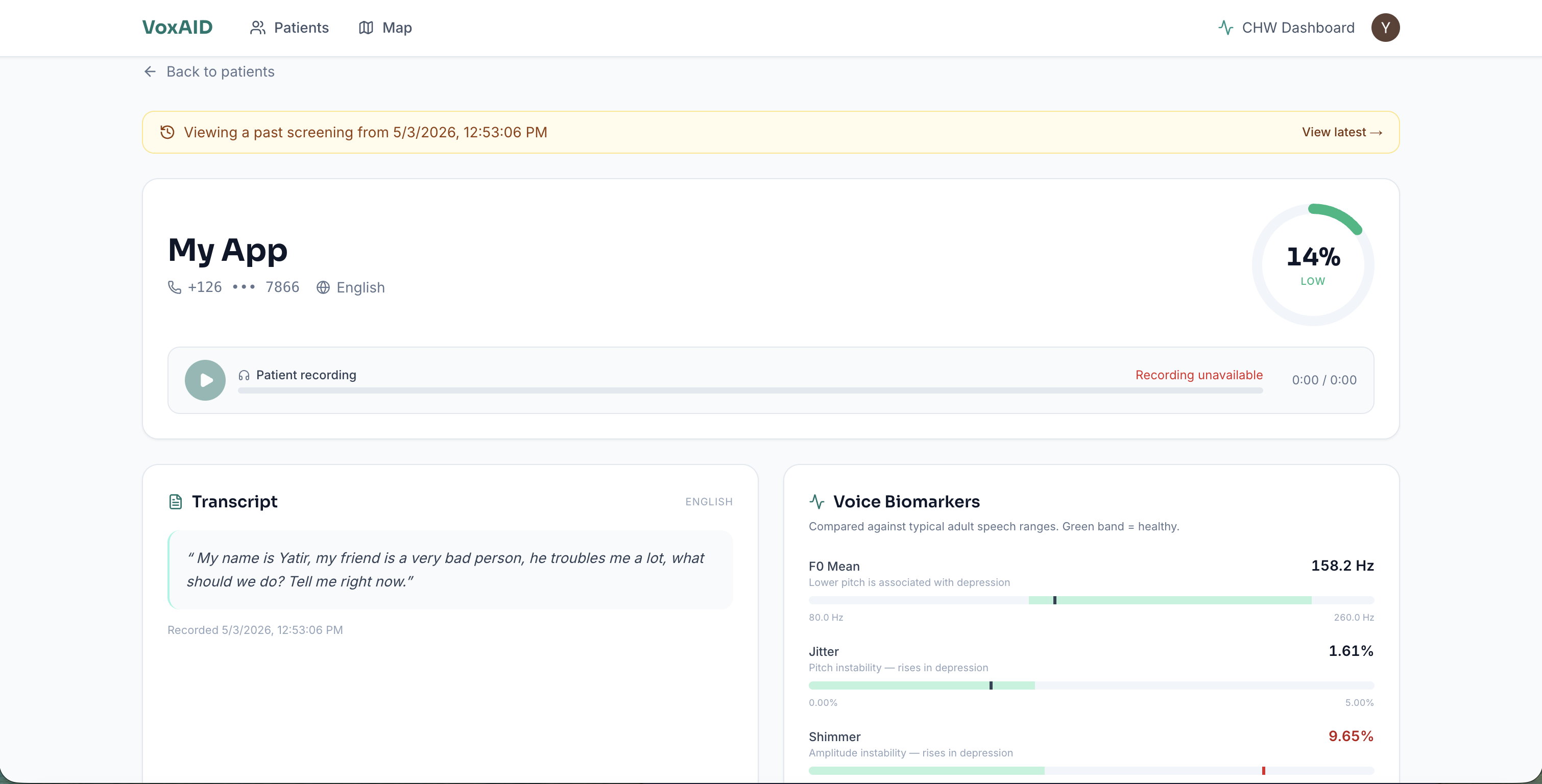
- Translates the transcript to English alongside the original, so a CHW or reviewing clinician sees both
- Extracts 35 vocal biomarkers from the audio (4 F0 statistics, jitter, shimmer, HNR, pause ratio, speech rate, 13 MFCC means + 13 MFCC stds)
- Classifies depression risk using XGBoost trained on distributions from the DAIC-WOZ depression literature
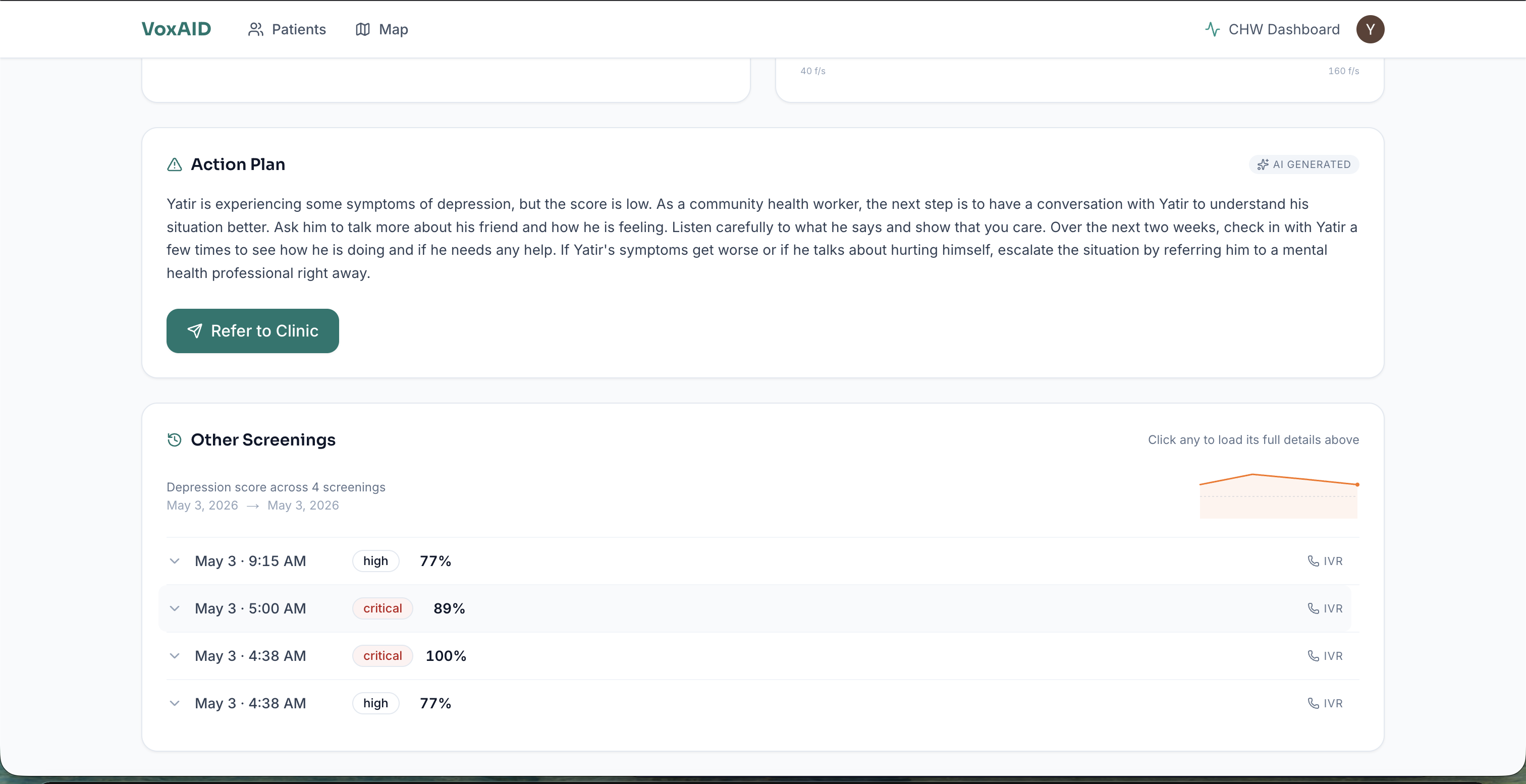
- Generates an action plan in the patient's own language using Llama 3.3 70B (via Groq)
- Calls high-risk patients back with their next steps via ElevenLabs multilingual TTS
- Flags them on a CHW dashboard with a one-click shareable referral slip
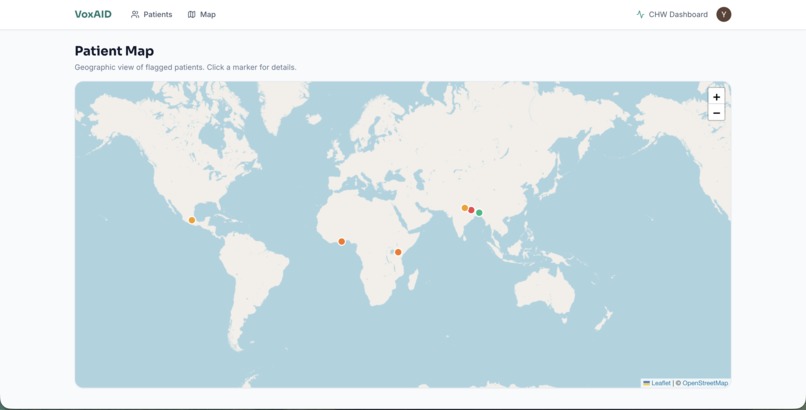
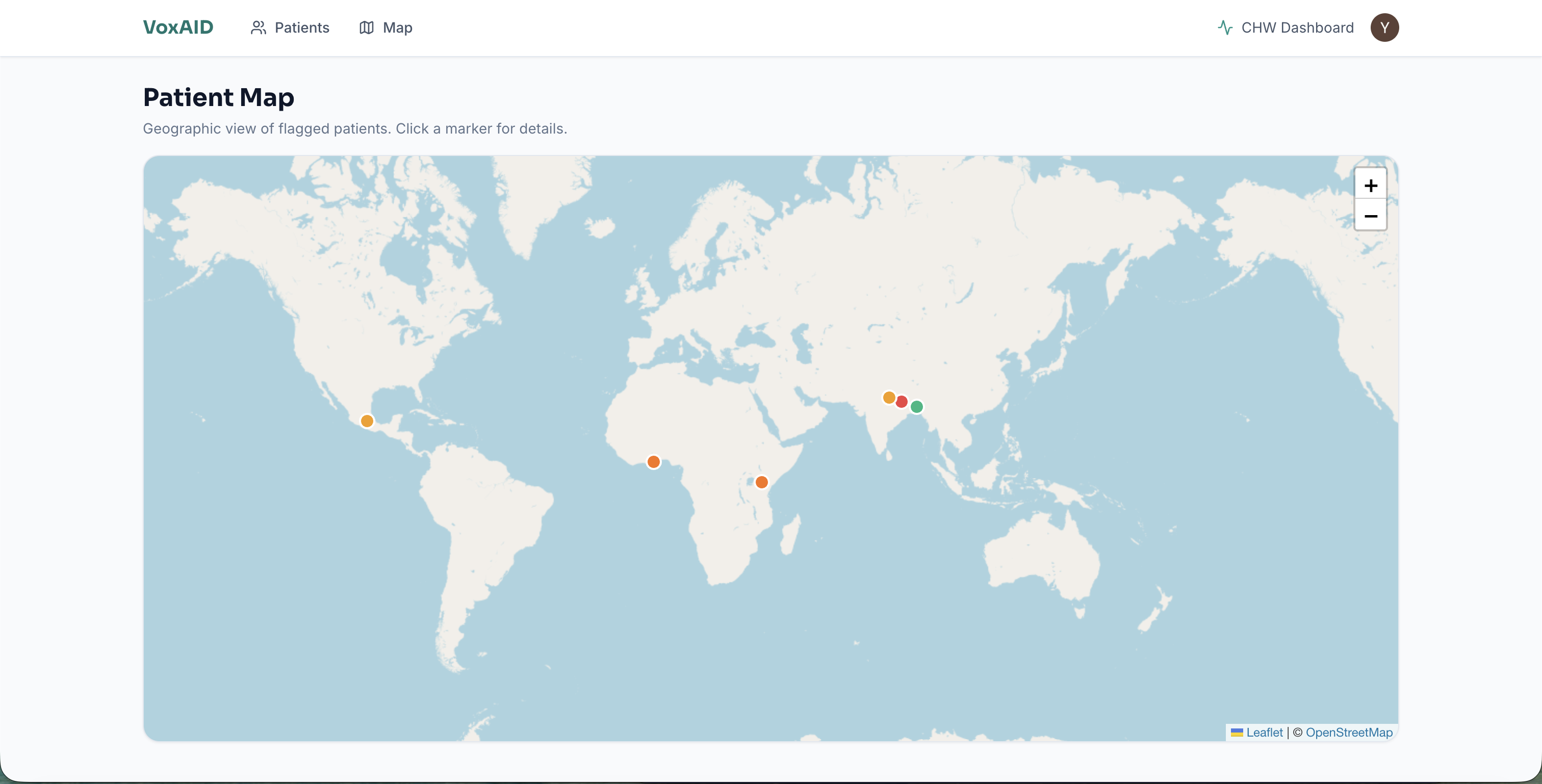
The CHW dashboard shows every screened patient with color-coded risk levels, a geographic map view (patients geolocated by phone country code with per-caller jitter), voice biomarker breakdowns, full transcripts in the original language with English translation side-by-side, and AI-generated action plans. The referral button generates a tokenized public URL the CHW can hand to the patient or share with a clinic — no SMS or email account required, works on any phone with a browser.
Total cost per screening: $0.03.
What makes this different
Voice-AI mental health screening already exists — for the developed world. Kintsugi, Ellipsis, and Sonde all sell into US clinical workflows: smartphone-only, English-only, priced for US payers. The 4 billion people in low- and middle-income countries — the population most cut off from psychiatric care — are locked out of every existing tool.
VoxAID is the first to combine voice biomarkers, IVR + WhatsApp ingest, multilingual action plans, a CHW workflow, and LMIC pricing in a single screening pipeline:
- Feature-phone first. A patient dials in from a $20 Nokia. No app, no internet, no literacy required.
- 99+ languages via Whisper auto-detect, with action plans in the patient's own language and an English translation alongside for any reviewing clinician.
- CHW workflow, not clinician workflow. Built for an ASHA worker on a $50 Android tablet, with a tokenized public referral slip that works without SMS or email on the patient side.
- $0.03 per screening. A state government or NGO can run 500K screenings a month for ~$5K — designed for the budgets that actually exist in LMIC public health.
The signal processing (librosa + Praat + XGBoost on DAIC-WOZ-derived features) is well-established science. The novelty is the productization for the population every existing tool ignores.
How we built it
Three services in a Turborepo monorepo:
Voice pipeline: Twilio handles inbound IVR calls. The recording hits our NestJS API, which queues a BullMQ job on Redis. The worker fetches the audio, sends it to Whisper large-v3 (hosted on Groq) for transcription, and pipes the same audio to our FastAPI ML service. We deliberately pass no language hint to Whisper — auto-detect with temperature: 0 and a domain prompt is reliable on 10-30s screening audio, and a strict hint causes Whisper to silently drop the non-hinted half of code-switched speech (English ↔ Tamil/Hindi/Spanish).
ML service: Built in Python with librosa and praat-parselmouth. We extract F0 statistics (mean, std, min, max), jitter, shimmer, harmonics-to-noise ratio, pause ratio, speech rate, and 13 MFCC coefficients with mean + std — 35 features total — and feed them into an XGBoost classifier trained on synthetic data generated from DAIC-WOZ literature distributions. The model outputs a depression probability score from 0 to 1, mapped to four risk tiers. A defensive layer catches NaN/Inf from Praat on edge-case audio so the pipeline degrades gracefully instead of crashing.
Action plans, translation, and name extraction: All three LLM calls run on Llama 3.3 70B via Groq. After transcription, we ask Llama to extract the speaker's name from the transcript (returning null when no name is given — no regex, no hardcoded filler list, handles non-Latin scripts and code-switched intros). In parallel, the biomarkers + transcript + risk score go to Llama for a localized action plan in the patient's own language, and a separate Llama call translates the transcript to English so the dashboard shows both languages side-by-side. Translation is best-effort and never blocks the screening. The architecture keeps a Claude Sonnet 4.6 path wired up for production, but the demo runs entirely on Groq — fast, free, no credit card needed. For high-risk and critical patients, ElevenLabs generates multilingual speech audio and Twilio calls the patient back to deliver their next steps.
Dashboard: Next.js 14 with App Router, Clerk authentication, Tailwind CSS, and Framer Motion. Server components fetch from the NestJS API backed by Supabase Postgres via Prisma. The map view uses Leaflet with OpenStreetMap tiles to plot patients by approximate location (derived from phone country code with per-caller jitter so multiple callers from one country don't stack on the same pixel). The referral flow generates a tokenized public URL — no SMS or email account on the patient's side — so a CHW can hand the patient a printed slip or share the link directly.
Challenges we ran into
Praat crashes on edge-case audio. The parselmouth library (Python bindings for Praat) throws NaN and infinity values on very short or very quiet recordings. We had to build a sanitization layer that catches these and degrades gracefully instead of crashing the entire pipeline.
Bilingual code-switching. Our first version forced a Whisper language hint based on phone country code (e.g. +1 → English). On a real test call mixing English and Tamil, Whisper transcribed only the English half and silently dropped the Tamil. We dropped the country-code hint table entirely and now rely on Whisper auto-detect with temperature: 0 and a domain prompt — preserving the original language without losing the non-hinted speaker.
Name extraction without a regex. Our first version used a regex with a hardcoded list of intro phrases and filler words. It mis-extracted "this is my app" as the patient name "My App", and it had no chance against names in non-Latin scripts or code-switched intros. We replaced it with a one-shot Llama call that returns {"name": <string|null>} — no list to maintain, never invents a name, works in any language.
Connecting the pipeline end-to-end. Each service worked individually early on, but wiring Twilio webhooks through BullMQ to Whisper to the FastAPI ML service to Llama to ElevenLabs to Prisma was the real challenge. One broken link and the whole screening fails silently. We spent significant time on error handling at every junction and on the right concurrency model — running ML biomarker extraction in parallel with name extraction, and action-plan generation in parallel with English translation.
Making it work on feature phones. The entire UX constraint is that the patient side requires zero technology beyond voice. No app downloads, no internet, no literacy. Twilio IVR handles this, but designing the voice prompts and recording flow to be natural across languages and cultures required careful thought. The shareable referral slip — a tokenized public URL — was the answer to "how does a CHW give a patient a referral if the patient doesn't have email or reliable SMS?"
Accomplishments that we're proud of
This is not a wrapper around an LLM. The core of VoxAID is real signal processing. We extract clinically validated voice biomarkers using the same techniques used in published psychiatric research. The XGBoost classifier, the Praat feature extraction, the 32-dimensional biomarker vector: this is actual science applied to a real problem.
The full pipeline works end-to-end. A real phone call produces a real transcription (with English translation alongside), real biomarkers, a real risk score, a real action plan in the patient's language, a real ElevenLabs callback for high-risk cases, and a real shareable referral slip. Every piece is connected.
And it costs $0.03 per screening. At scale, you could screen a million patients a month for under $30,000. That's cheaper than a single psychiatrist's salary.
What we learned
Voice carries more clinical information than most people realize. The research on vocal biomarkers for depression is robust and goes back decades. Jitter and shimmer alone have been shown to differentiate depressed from non-depressed speakers with meaningful accuracy.
We also learned that the hardest part of building for low-resource settings isn't the AI. It's the infrastructure assumptions. Every modern dev tool assumes smartphones, internet, and English. Building something that works on a $10 Nokia over a cellular voice call forces you to rethink everything.
What's next for VoxAID
Clinical validation: Partner with NIMHANS (India's National Institute of Mental Health) to validate against PHQ-8 scores on real patient populations.
Expand conditions: The same vocal biomarker pipeline can screen for anxiety (GAD-7 correlation), PTSD, and even pre-eclampsia in pregnant women (vocal biomarker research by MIT).
ASHA worker pilot: Deploy with 100 ASHA workers in Bihar for a 3-month pilot measuring screening rates, referral completion, and patient outcomes.
Self-hosted Whisper: Move from Groq-hosted to self-hosted Whisper to eliminate rate limits and data-sovereignty concerns for clinical deployments.
FHIR integration: Connect to India's ABDM (Ayushman Bharat Digital Mission) health records system so screenings flow into the national health stack.

Log in or sign up for Devpost to join the conversation.