-
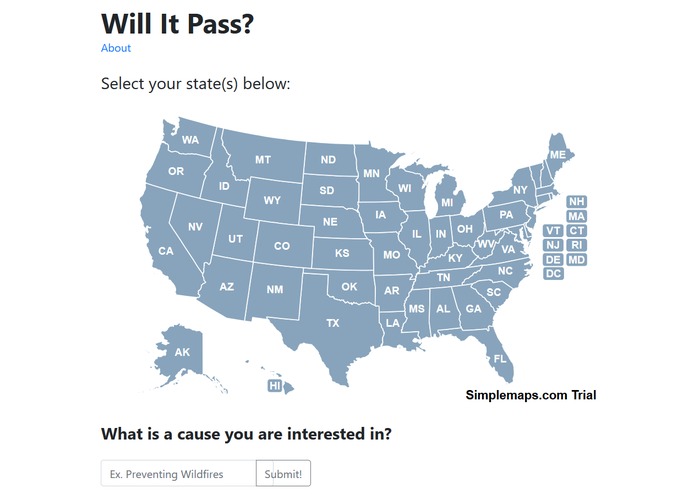
The main screen.
Inspiration
Initially, we were going to go in a very different direction: fighting wildfires using swarms of drones. Though we didn't have any drones on hand, we could create software to detect and coordinate drone swarms that could put out fires. About an hour in, we started having some problems. For one, we realized that a lot of companies with more resources and time were already working on solving this problem. We also realized that the problem wasn't so much forest fires, but the human irresponsibility preceding it. The best solution was simply to clean up and not live too close to the woods, but lawmakers were unwilling to regulate. Since the problem of wildfires (and a lot of other problems, too) is one of leadership, we decided to make a website that could hold legislators responsible.
What it does
WillItPass is a website where you can search for issues and have AI predict how likely different representatives would support legislation for it. Even when we went out of our way during our research phase to find congressional archives and analysis tools, they were difficult to use and too out of the way. If someone really wanted to figure out how well their representative was representing them, they would have to sift through pages of data and confusing figures to reach a basic conclusion. Using the power of Google's AI tools, WillItPass analyzes how legislators voted on previous bills to create predictions on how they would react to future bills.
How we built it
Our main app is a Flask web app running on Google App Engine. To fetch data on voting patterns, we used the ProPublica Congressional API. Tensorflow was used to create our prediction models, and we ran them on both local notebooks and Google Colaboratory.
Challenges we ran into
We thought it might be over when we tested one model, and it ended up taking an hour to train it. Fortunately, we attended the Google talk and remembered Google Natural Language processing. Our old method threw entire summaries of bills at the models, which caused extremely slow performance. Using Google's API, we changed our data sets to use a couple keywords instead of long summaries. After making the change, the time it took to train for a single epoch went from over 3 minutes to ~8 seconds!
Accomplishments that we're proud of
We're proud that we were able to create, at the very least, a working prototype with such new technologies and so short a time limit.
What we learned
We had never used Flask before tonight, but we were able to create a nice little web app with it. We also had never met each other before but ended up synergizing pretty well.
What's next for WillItPass
Directly releasing it onto the Internet afterwards could be problematic, since lots of research has been spent getting closer to accurate decision prediction, and if the models are wrong, it could give people the wrong impression of an unfortunate representative. Still, better tools that hold our leaders responsible are a real need, especially today, so we may pick it up in the future.

Log in or sign up for Devpost to join the conversation.