
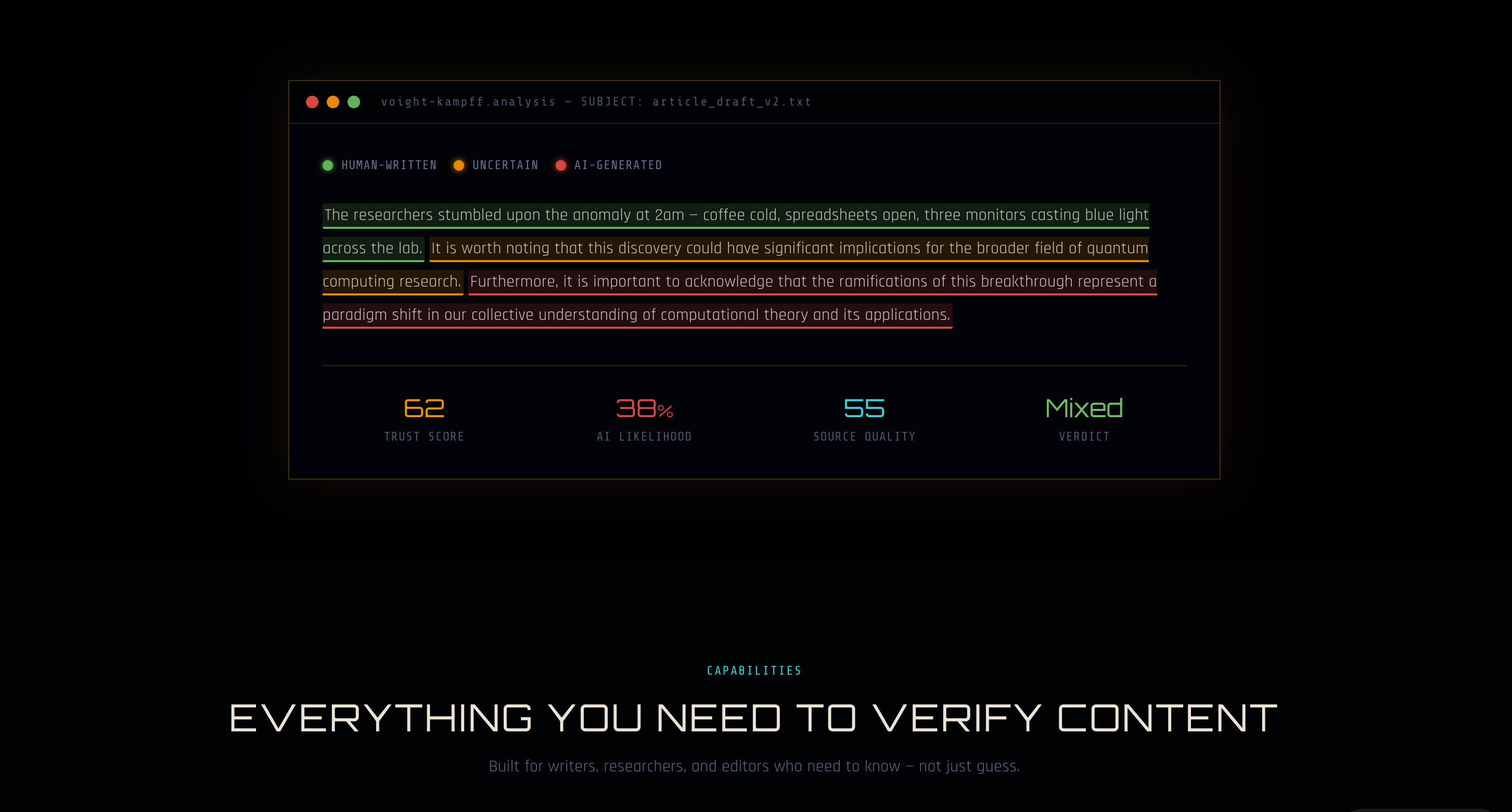
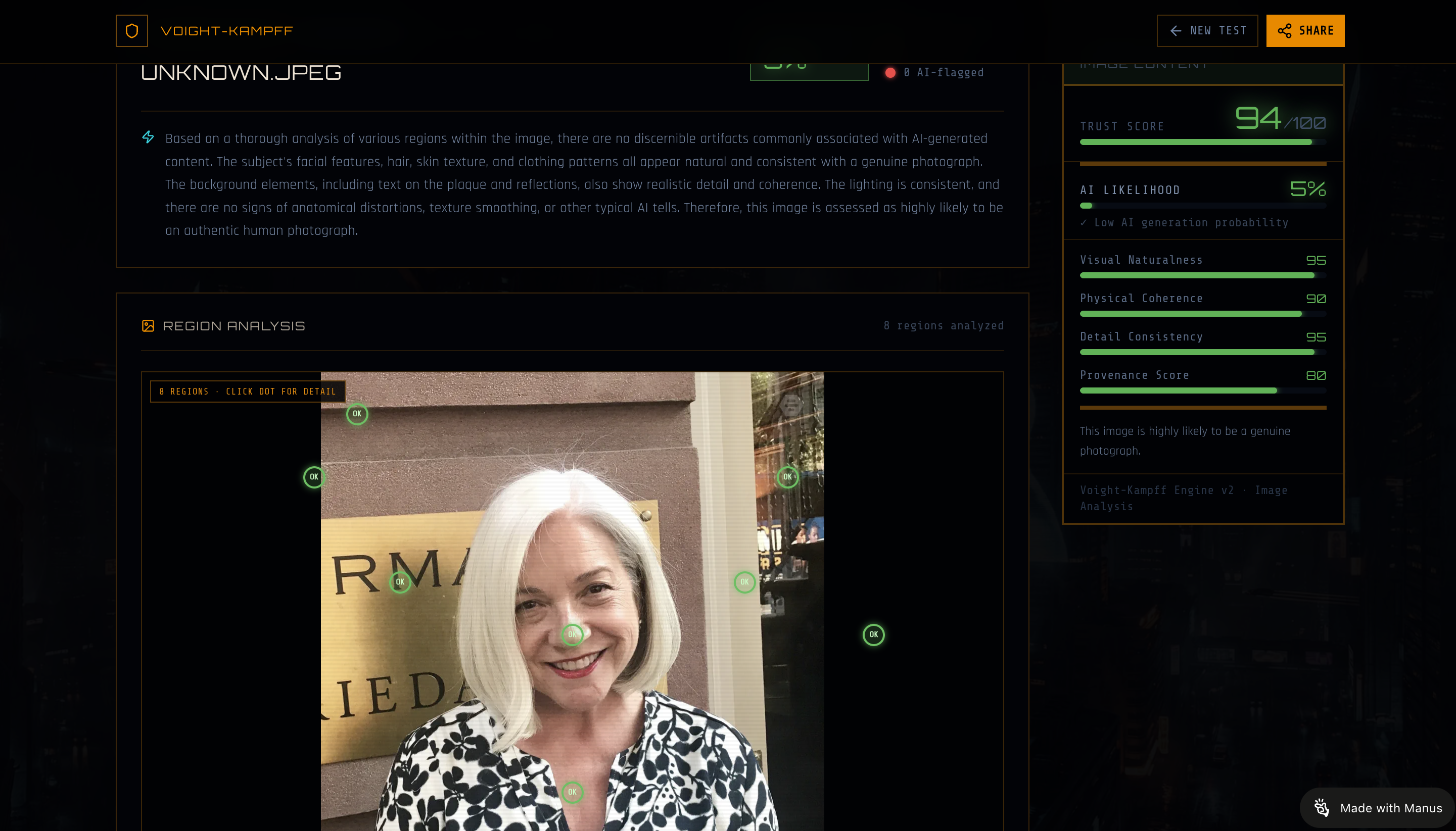
Most people encounter AI-generated content every day without knowing it — a news article that sounds authoritative but was written in seconds, a product photo that never existed, a social post engineered to feel personal. The tools to detect this have existed in research labs and enterprise security teams, but never in a form that a journalist, a teacher, a designer, or a curious reader could actually use. Voight-Kampff was built to close that gap. Named after the fictional empathy test from Blade Runner used to distinguish humans from replicants, the app applies the same interrogation logic to content: submit anything — text or image — and the system returns a colour-coded Proof of Person score that shows exactly where the machine left its fingerprints. The result is displayed as a nutrition label for content: structured, scannable, and brutally honest about what is human and what is not.
The stack is a full-service TypeScript monorepo: React 19 with Tailwind CSS 4 and shadcn/ui on the frontend, Express 4 and tRPC 11 on the backend, Drizzle ORM over a MySQL/TiDB database, and Vite as the build tool. The detection engine is built on top of a multimodal LLM API — text analysis uses structured JSON Schema output enforcement with response_format: json_schema to extract per-segment AI likelihood scores, source quality ratings, and factual consistency metrics; image analysis uses the vision API's high-resolution tile mode to identify 8–14 spatial regions per image and classify each against a controlled taxonomy of eight named artifact types. State management is handled entirely through TanStack Query via tRPC hooks, with optimistic updates on history mutations and session persistence via localStorage for anonymous session-scoped history. The Blade Runner visual identity — neon amber on deep black, Orbitron display type, rain-soaked AI-generated cityscape hero, scanline CSS overlays — was designed from scratch using Tailwind CSS custom design tokens and OKLCH colour values.
The hardest engineering challenge was making the scoring system trustworthy rather than just plausible. Early versions passed the trust score computation entirely to the LLM, which produced results that were internally inconsistent — a segment labelled "human" with an aiScore of 80, or a high-AI-likelihood article that somehow received a high trust score because the model also rated its structure highly. The solution was to strip all scoring authority from the model and enforce a deterministic weighted formula server-side: trustScore = (100 − aiLikelihood) × 0.55 + sourceQuality × 0.20 + factualConsistency × 0.10 + styleNaturalness × 0.10 + structuralCoherence × 0.05. Every label, threshold, and colour assignment is computed from the numbers after the LLM responds, never from the LLM's own label suggestions. A second major challenge was database payload size — the full image analysis JSON, including base64 image data, region coordinates, artifact explanations, and aggregated artifact details, routinely exceeded MySQL's default TEXT column limit of 64KB. This required migrating the results and image URL columns to LONGTEXT (4GB limit) and pushing a live schema migration without data loss. A third challenge was tab-state coherence across navigation: ensuring that selecting "Image Content" on the landing page carried that intent through the URL (?tab=image) into the Analyze page, and that every CTA, nav button, feature card, How It Works step, and final call-to-action updated in sync — requiring a single shared heroTab state that drove all downstream content rendering rather than duplicating copy across components.
Built With
- css
- express.js
- manus
- mysql
- react
- tailwind
- trpc
- vite

Log in or sign up for Devpost to join the conversation.