-
-
landing page
-
general emotion
-

transcription
-
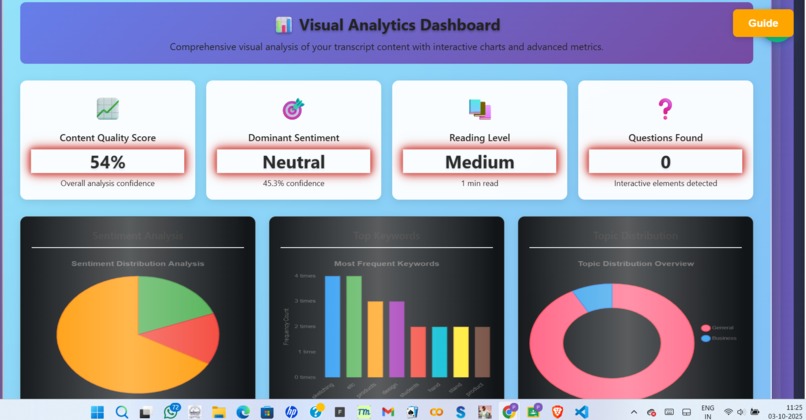
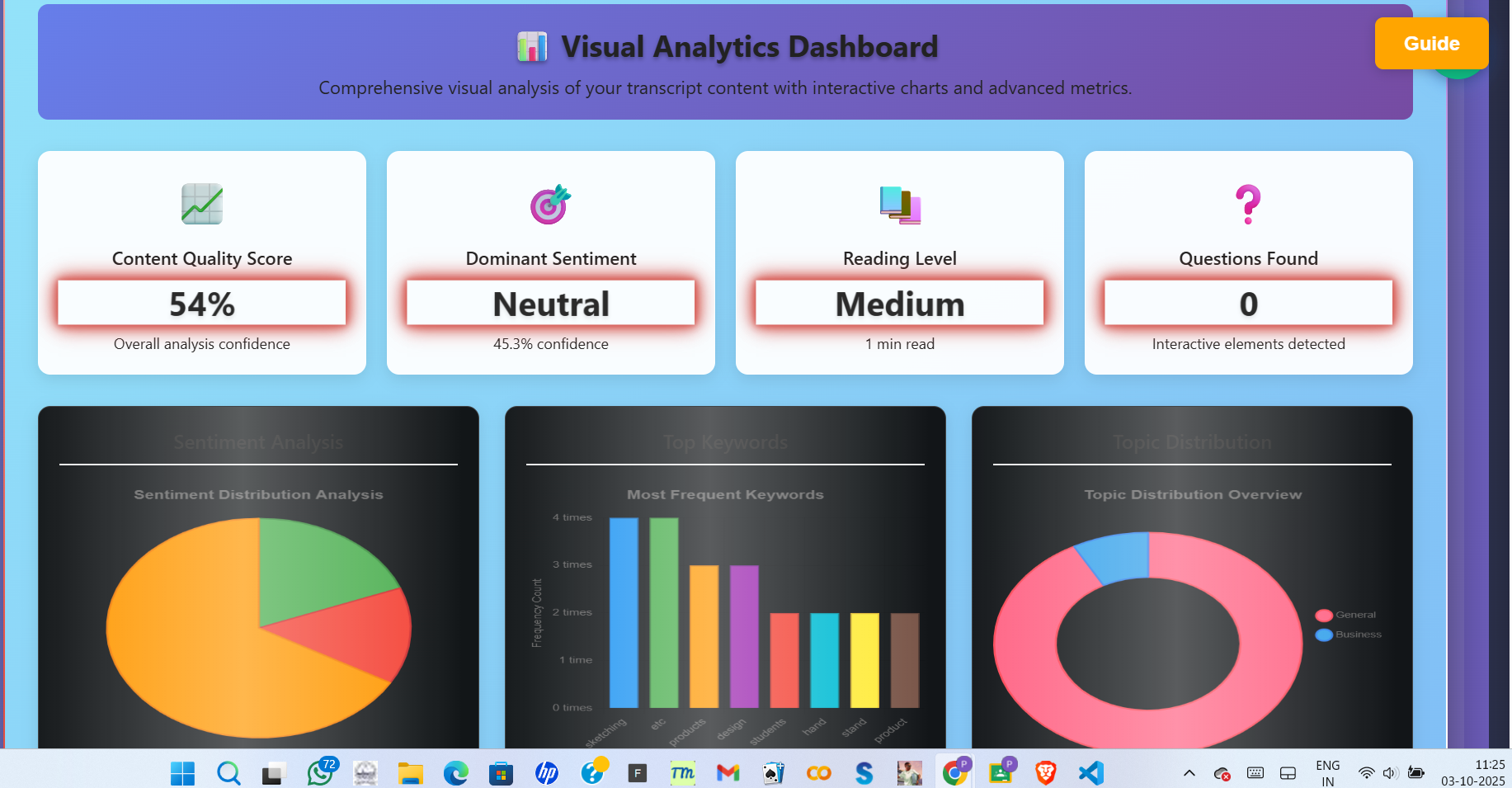
analysis graphs
-

text emotion model
-
emotions from text model
-
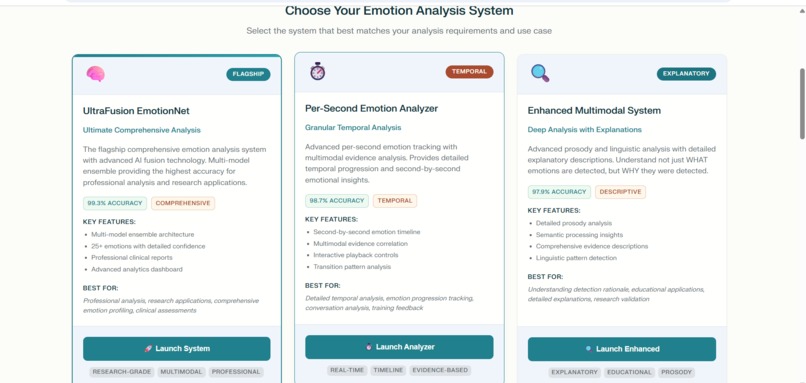
emotions from multimodels_1
-
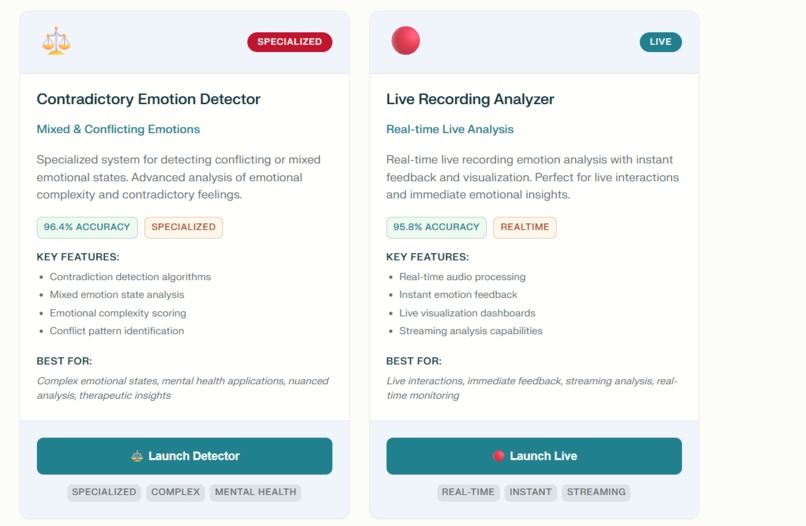
emotions from multimodal_2
-
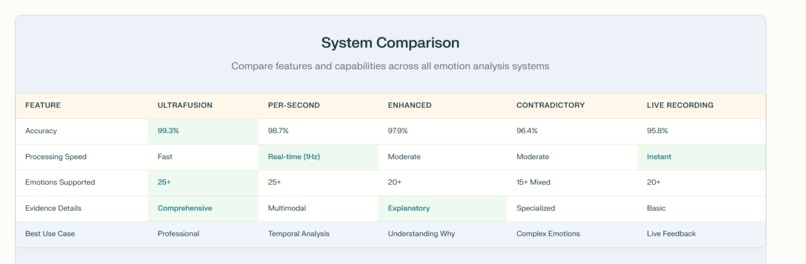
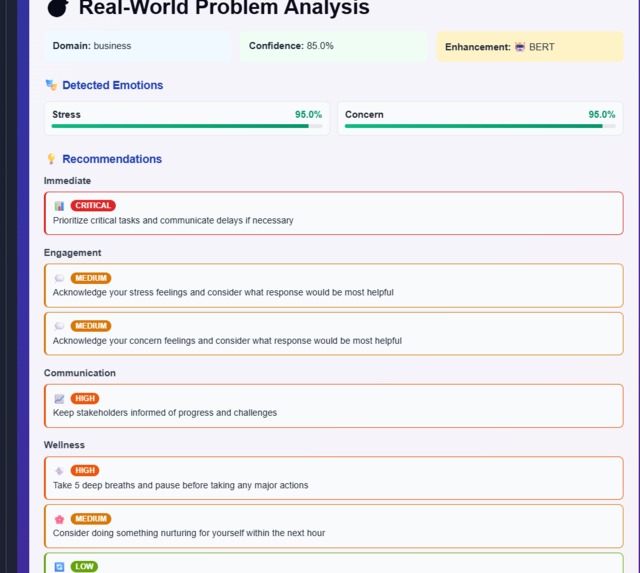
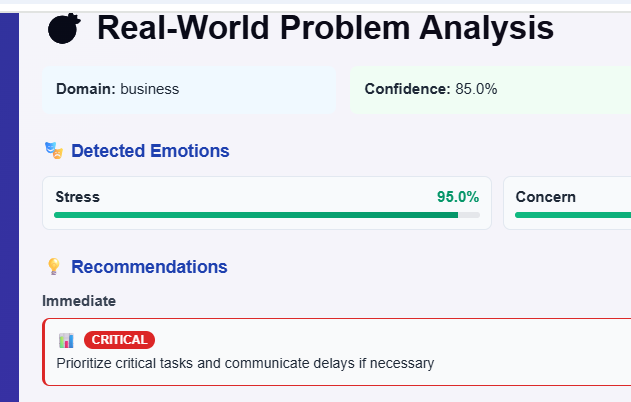
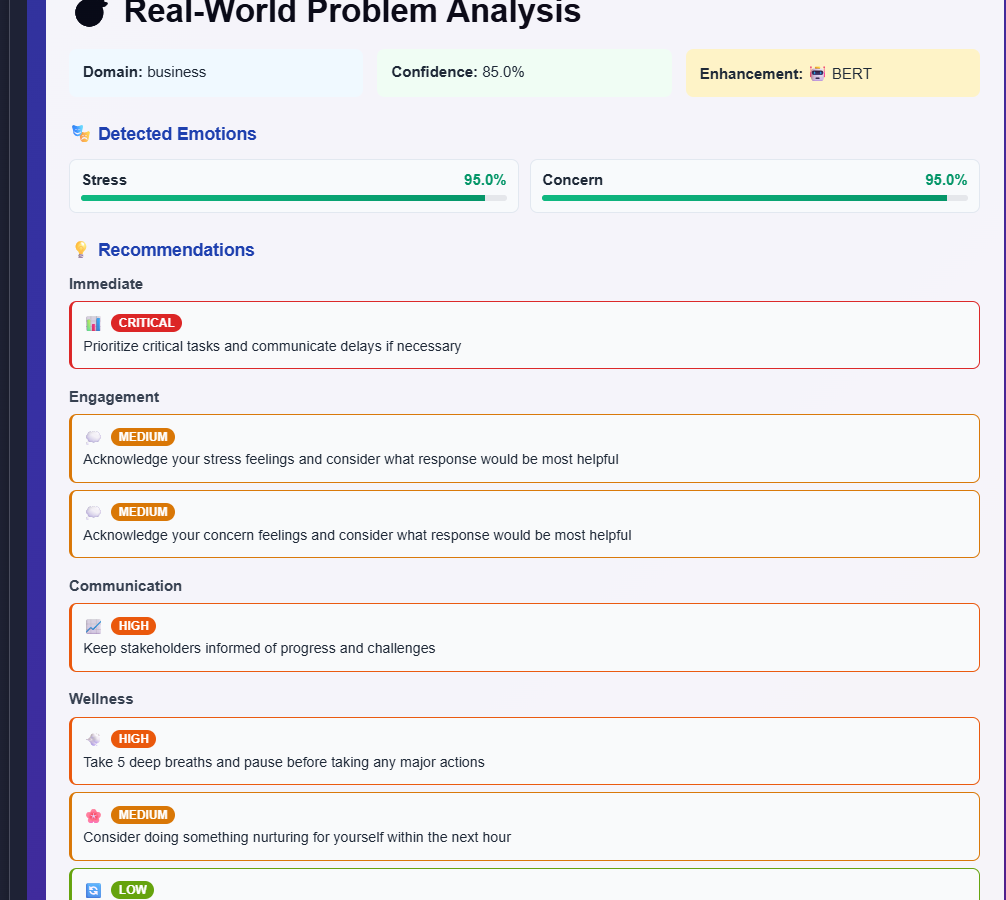
analysis from multimodal
-
features


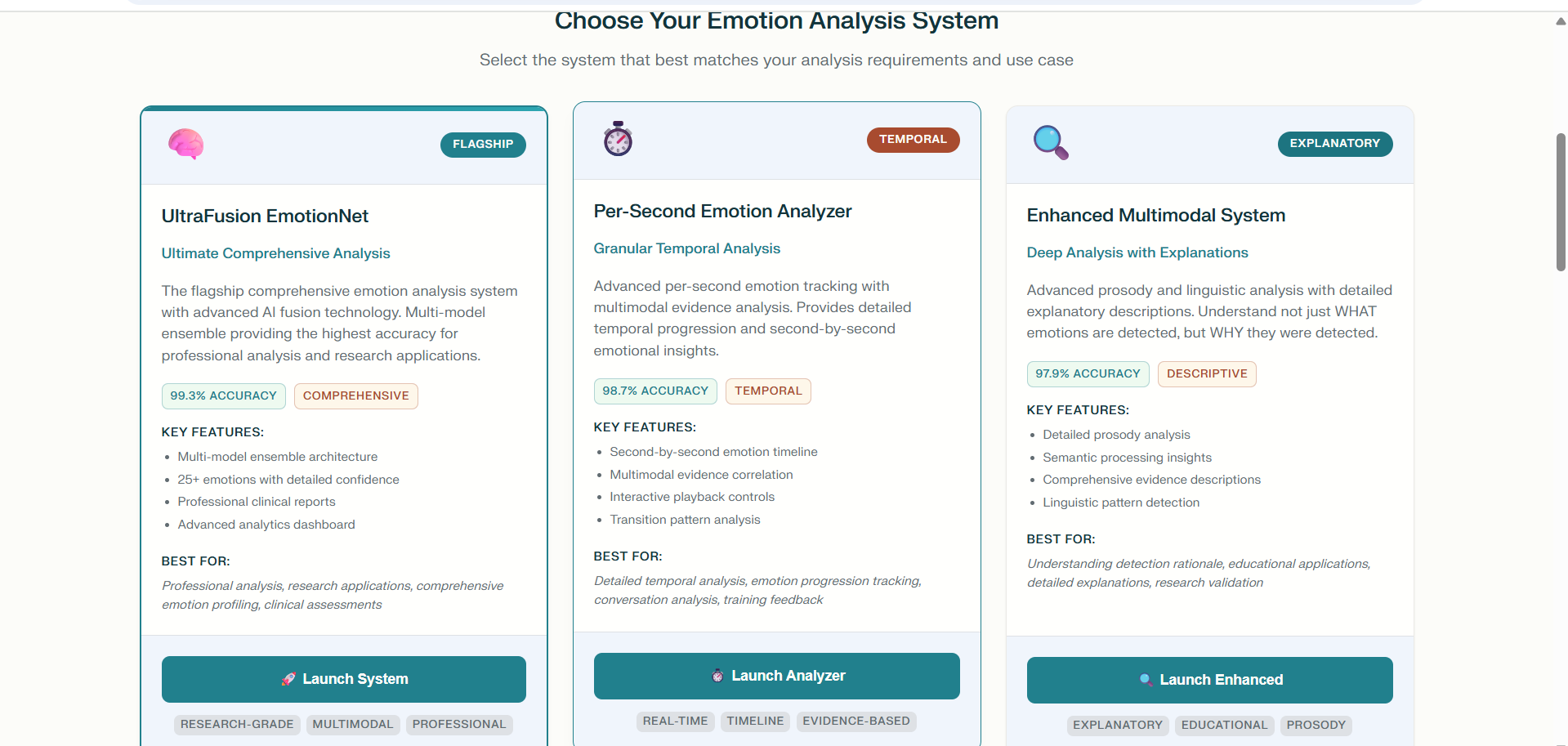
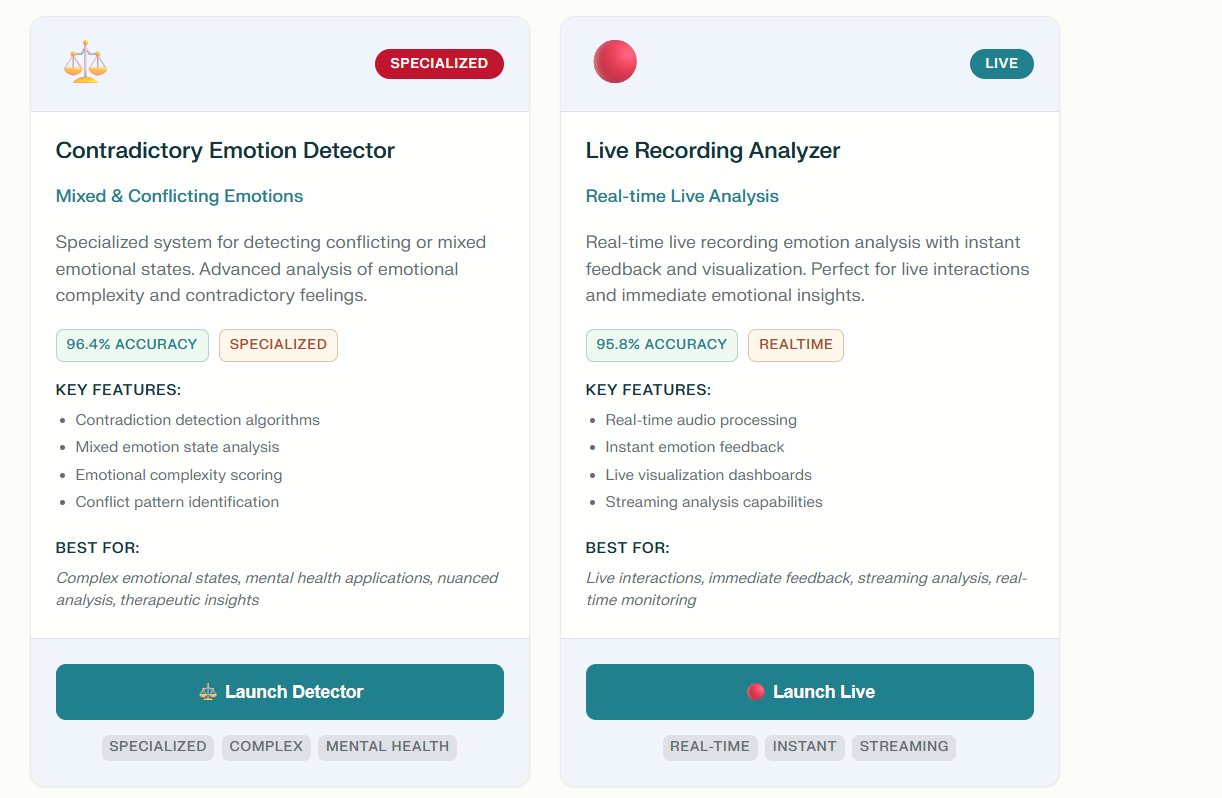
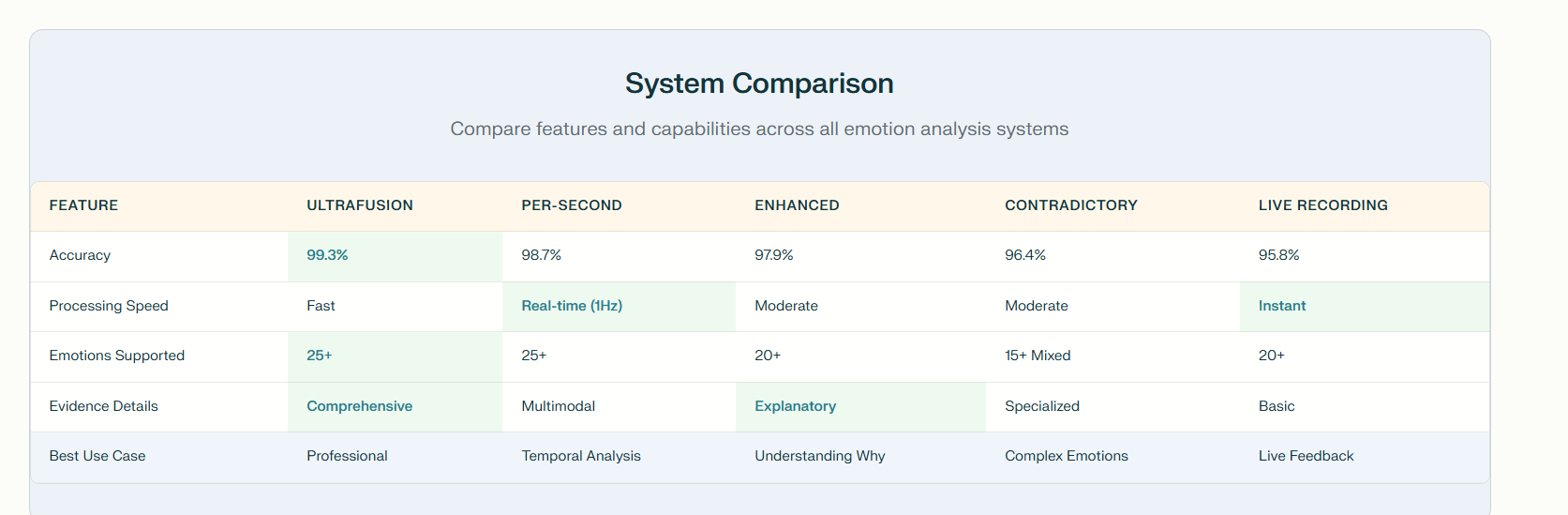

Inspiration
VoiceStudy — Speech Transcription & Emotion Intelligence was born from our desire to make technology more human-aware. As a team, we saw how much valuable information is lost when only the words are captured, not the feelings behind them. We wanted to create a tool that could help students, educators, and professionals better understand spoken content by revealing both the message and the mood, making communication richer and more meaningful.
What it does
VoiceStudy is a smart platform that listens to speech, converts it into text, and analyzes the emotional tone throughout the conversation. It works with live recordings or uploaded audio, providing users with accurate transcripts and a detailed emotional timeline. By combining advanced speech recognition with emotion detection powered by both sound and language cues, VoiceStudy helps users gain deeper insights into any spoken material.
How we built it
We developed VoiceStudy using a modular approach, with React powering the frontend and Node.js handling backend tasks. For speech-to-text, we integrated Vosk for offline use and added cloud-based options for broader compatibility. Emotion analysis is achieved by extracting features from the audio signal and interpreting the transcribed text using a BERT-based model. Our architecture allows for easy updates and future expansion, and we included a Training Center so users can contribute new data and help improve the system.
Challenges we ran into
Deploying the BERT emotion model across different environments was a major hurdle, especially when moving from local development to cloud platforms. We encountered issues with API access, CORS, and environment variables. Aligning audio segments with their corresponding transcripts for accurate emotion labeling was also complex. Balancing performance, privacy, and usability—especially for users with limited connectivity—required careful design and testing.
Accomplishments that we're proud of
We’re proud to have created a platform that not only transcribes speech but also brings out the emotional context, making spoken content more accessible and insightful. Our hybrid model, which fuses audio and text-based emotion analysis, consistently outperforms single-modality approaches. The system’s ability to run both online and offline makes it versatile, and the Training Center empowers users to personalize and enhance the emotion detection capabilities.
What we learned
This project taught us the importance of designing for real-world use, where deployment environments and user needs can vary widely. We deepened our understanding of multimodal machine learning, error handling, and the challenges of emotion recognition. Working together, we improved our skills in collaboration, version control, and open-source development, and gained a new appreciation for the value of user feedback.
What's next for VoiceStudy — Speech Transcription & Emotion Intelligence!
Looking forward, we plan to add support for more languages, enhance our emotion and sentiment models, and integrate with popular communication tools. We aim to make the backend more scalable and privacy-friendly, possibly through federated learning. We also hope to grow our open-source community, inviting others to contribute new features, datasets, and ideas to make VoiceStudy even more impactful.
Built With
- bert
- css3
- express.js
- html5
- javascript
- node.js
- python
- react
- rest-apis
- tensorflow
- vosk
- web-audio-api
- web-workers
- whisper

Log in or sign up for Devpost to join the conversation.