-
-

logo
-
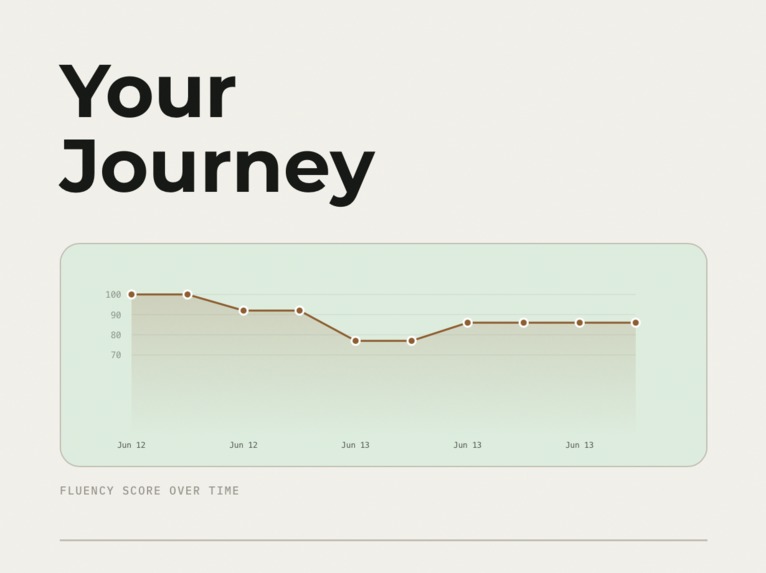
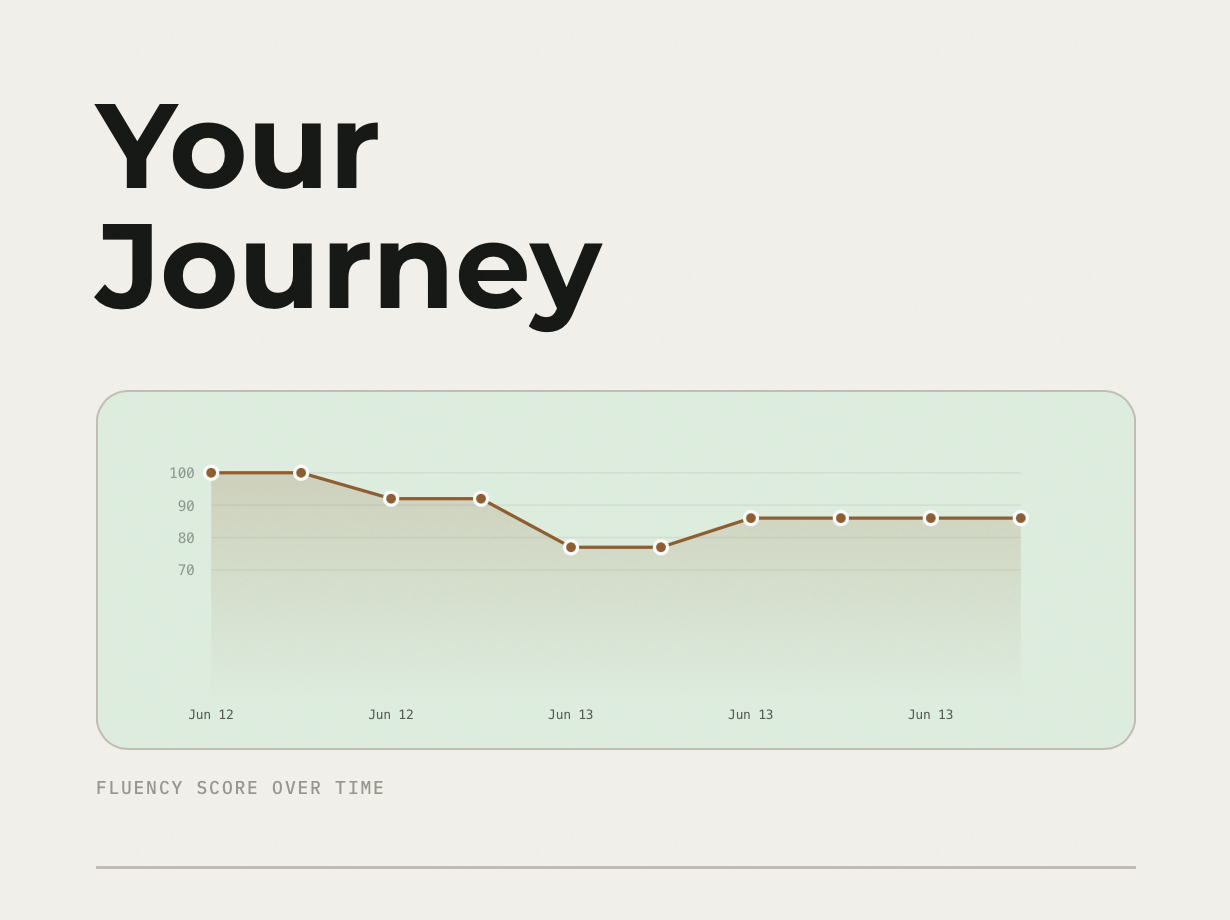
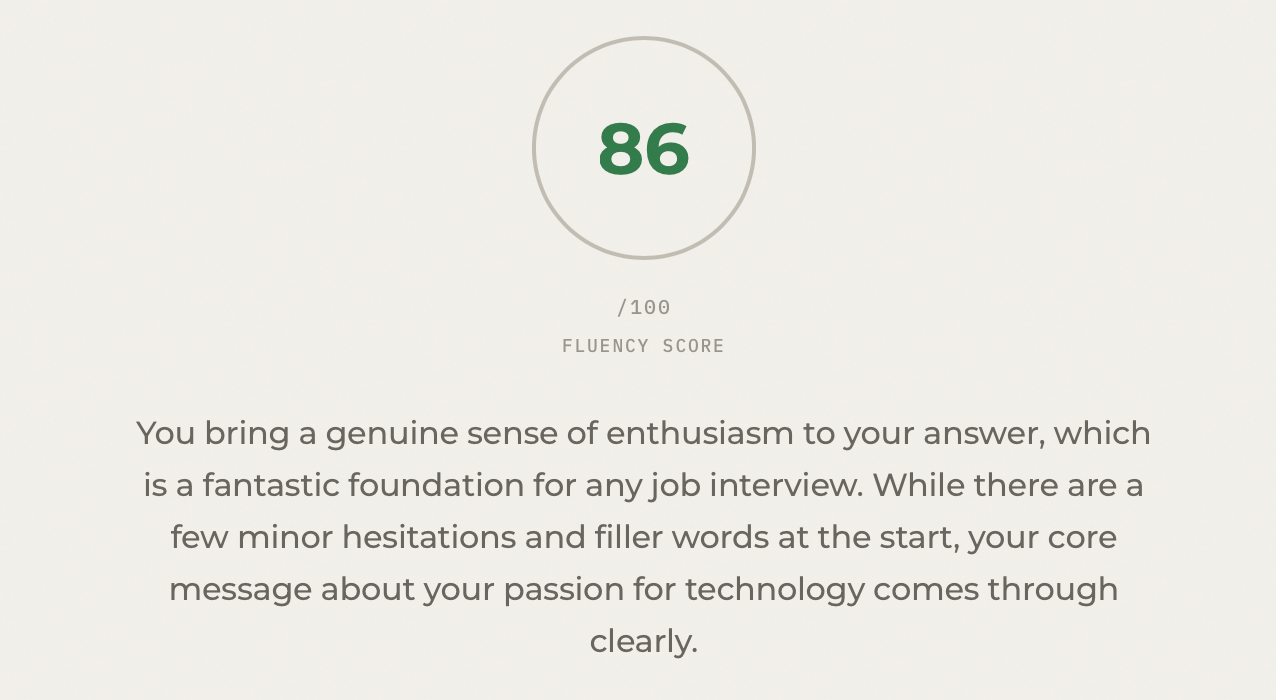
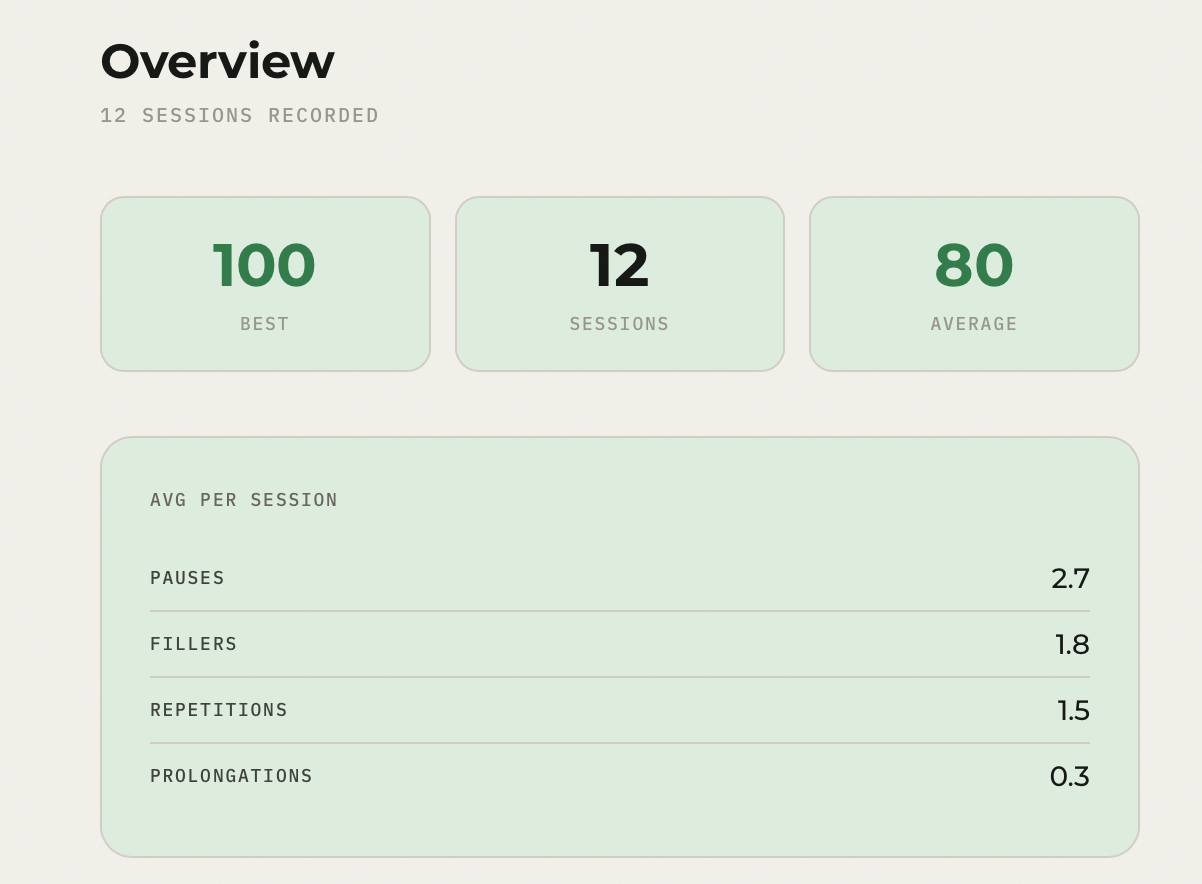
Analysis of your past sessions with Recharts
-
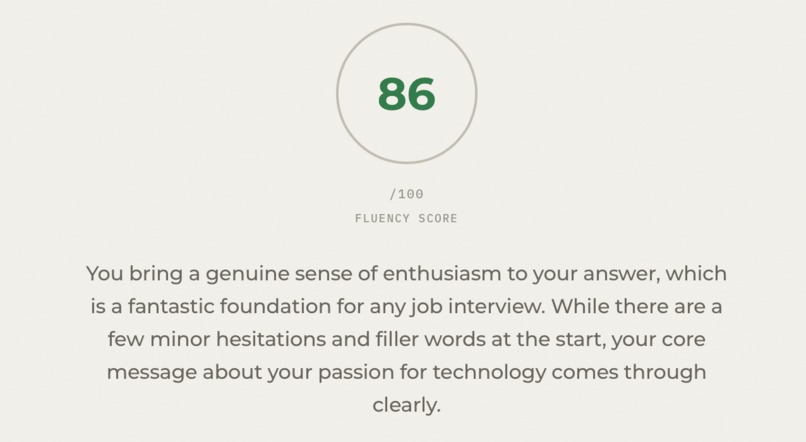
-
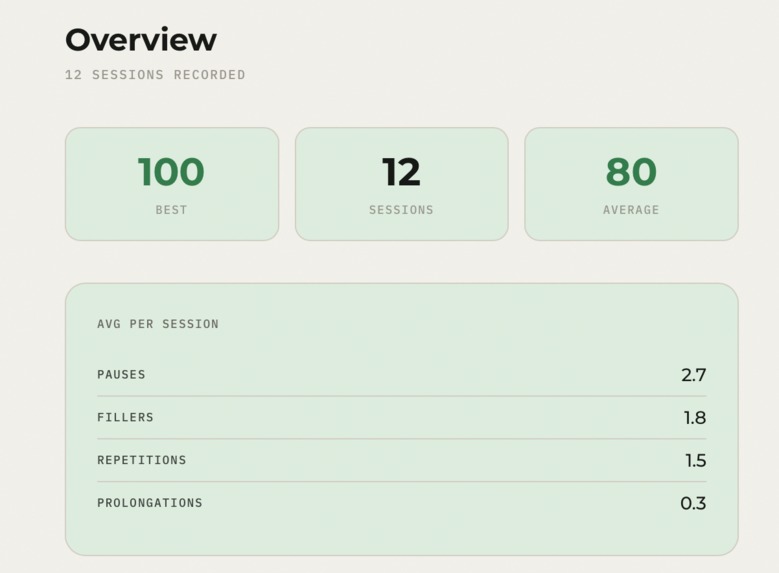
Overview of your past sessions

VoiceScribe Project Story
Inspiration
Speaking confidently is a skill. Like all skills, it requires practice and honest feedback. But for most people, students preparing for job interviews (InterviewCake will help in OA tho ;), professionals delivering presentations, individuals managing speech anxiety — that feedback has never been free, private, or immediate.
The deeper problem isn't just anxiety. It's invisibility. Most people have no idea how often they say "um" or "uh" mid-sentence, how long their silences actually run, or how many times they repeat a word when their brain stalls for time. These patterns are invisible to the speaker and painfully obvious to everyone else.
Traditional speech tools either require expensive clinical setups or give you passive metrics with no context. We built VoiceScribe to make your speech visible to you, in real time, and to turn that visibility into genuine, actionable coaching.
What It Does
VoiceScribe is an AI-powered communication training platform combining real-time speech annotation with context-aware AI coaching across three modes: Job Interview, Presentation, and Custom.
Real-Time Fluency Tracking: Every word is transcribed and classified instantly — fillers, repetitions, prolonged words, and long pauses are flagged and color-coded in an annotated transcript that updates live.
Context-Aware AI Coaching: When you click Analyse, your full tagged transcript, chosen mode, and specific prompt are sent to Gemini. Feedback is specific to what you said and what you were trying to say.
Continuous Progress Tracking: Every session is saved locally. A deterministic analytics engine tracks patterns across sessions without a single additional API call.
How We Built It
VoiceScribe runs on a three-stage pipeline engineered for low latency and privacy.
Stage 1 — Real-Time Audio Streaming
The browser opens a persistent WebSocket connection to Deepgram Nova-2. Audio streams in 250ms chunks. Deepgram returns every word with millisecond-precision timestamps in real time.
In src/services/deepgramService.ts, we construct the connection URL with the required query parameters, including filler_words: 'true':
const params = new URLSearchParams({
model: 'nova-2',
language: 'en-US',
smart_format: 'true',
filler_words: 'true', // ensures filler words are transcribed
// ... other parameters
});
Once the socket opens in our custom hook src/hooks/useDeepgram.ts, the MediaRecorder slices audio into chunks and sends them over the WebSocket connection:
socket.onopen = () => {
const mimeType = getSupportedMimeType();
const mediaRecorder = new MediaRecorder(stream, { mimeType });
mediaRecorder.ondataavailable = (event) => {
if (socket.readyState === WebSocket.OPEN && event.data.size > 0) {
socket.send(event.data);
}
};
mediaRecorder.start(250);
};
Stage 2 — Local Classification Engine
As each timestamped word arrives, our frontend classifier in src/hooks/useWordProcessor.ts runs checks using pure arithmetic — no AI, no API call, zero latency.
Filler detection is checked using a normalized match against a curated list, vocalized pattern regexes, and two-word combinations:
export const FILLER_WORDS: string[] = [
'um', 'uh', 'er', 'ah', 'oh', 'uhm', 'like', 'basically', 'literally',
'actually', 'honestly', 'right', 'okay', 'so', 'well',
'you know', 'i mean', 'kind of', 'sort of'
];
export const isVocalizedFiller = (word: string): boolean => {
return (
/^u+h+$/.test(word) ||
/^u+m+$/.test(word) ||
/^u+h+m+$/.test(word) ||
/^e+r+$/.test(word) ||
/^a+h+$/.test(word) ||
/^o+h+$/.test(word)
);
};
const TWO_WORD_FILLERS = ['you know', 'i mean', 'kind of', 'sort of'];
// Inside the processWords loop:
const isTwoWordFiller =
(i + 1 < words.length && TWO_WORD_FILLERS.includes(`${normalized} ${normalizedWords[i + 1]}`)) ||
(i - 1 >= 0 && TWO_WORD_FILLERS.includes(`${normalizedWords[i - 1]} ${normalized}`));
if (FILLER_WORDS.includes(normalized) || isVocalizedFiller(normalized) || isTwoWordFiller) {
processedWord.type = 'filler';
isClassified = true;
}
Repetitions are caught by comparing each word against the previous two:
const matchPrev1 = i >= 1 && normalized === normalizedWords[i - 1];
const matchPrev2 = i >= 2 && normalized === normalizedWords[i - 2];
if (matchPrev1 || matchPrev2) processedWord.type = 'repetition';
Pauses are injected as synthetic tokens wherever the gap between consecutive word timestamps exceeds 1.5 seconds:
const gap = processedWord.start - lastRealWord.end;
if (gap > PAUSE_THRESHOLD_SECONDS) {
result.push({ word: '[pause]', start: lastRealWord.end, end: processedWord.start, type: 'pause' });
}
Prolongations are detected by comparing a word's duration against the rolling session average:
const duration = processedWord.end - processedWord.start;
if (duration > avgDuration * PROLONGATION_MULTIPLIER) {
processedWord.type = 'prolongation';
}
Stage 3 — Gemini Coaching
After the session, the full classified transcript, statistics, and context are sent to Gemini (gemini-3.5-flash), which returns a structured JSON response.
In src/services/geminiService.ts, the prompt logic is structured as follows:
const systemPrompt = `You are a brutally honest, no-nonsense speech coach...`;
const userPrompt = `
The user was practising: ${options.mode}
Their speech transcript: ${JSON.stringify(options.transcript)}
Return ONLY a valid JSON object with exactly these fields:
{
"overallFeedback": "...",
"questionFeedback": "...",
"coachingTip": "...",
"strengths": [...],
"improvements": [...],
"fluencyScore": <number 0-100>
}
`;
Challenges We Ran Into
The filler word problem — the words most tools ignore
This was our hardest technical challenge.
Most speech recognition systems are trained to suppress disfluencies. "I um I think that uh basically the answer is" would come back as "I think that the answer is." Perfectly clean. Completely useless for our purposes.
We solved this in two layers. First, we configured Deepgram to preserve disfluencies rather than clean them by passing filler_words: 'true' via the connection options:
const params = new URLSearchParams({
// ...
filler_words: 'true', // Deepgram Nova-2 option to return filler words
});
Second, even if Deepgram occasionally drops a filler word, our local classifier catches them in two ways: exact text checks against a curated FILLER_WORDS list (including multi-word patterns like "you know" or "i mean"), and a regular expression helper isVocalizedFiller to catch phoneme modifications ("uhh", "ummm", "errr", etc.):
// Match variable length filler phonemes
/^u+h+$/.test(word) || /^u+m+$/.test(word) // ... etc.
Removing bias from Gemini's feedback
Without context, Gemini produces coaching advice that sounds wise but is contextually wrong. A three-second pause during "tell me about yourself" is a red flag. The same pause while switching slides in a presentation is completely normal.
We restructured our prompt to force contextual grounding before Gemini forms any judgment:
const systemPrompt = `You are a brutally honest, no-nonsense speech coach...`;
We tested outputs iteratively — comparing Gemini's responses with and without context — until the feedback was indistinguishable from what a human coach would say after watching the same session.
Cross-browser audio reliability
MediaRecorder behaves differently across operating systems and browsers. Early builds would silently fail — the WebSocket would open, the mic would activate, and nothing would arrive at Deepgram. No error. Just silence.
We built a codec detection fallback that tests formats in order of preference:
const types = ['audio/webm;codecs=opus', 'audio/webm', 'audio/ogg;codecs=opus', ''];
const mimeType = types.find(type => type === '' || MediaRecorder.isTypeSupported(type)) || '';
And granular logging at every WebSocket stage in src/hooks/useDeepgram.ts so failures surfaced immediately:
socket.onopen = () => console.log('[Deepgram] WebSocket connected');
socket.onmessage = (event) => console.log('[Deepgram] message received');
socket.onerror = (ev) => console.error('[Deepgram] WebSocket error', ev);
socket.onclose = (ev) => console.log('[Deepgram] WebSocket closed');
Accomplishments We're Proud Of
The filler detection pipeline working reliably across browsers — catching what Deepgram highlighted and what our custom processor categorized — was the moment the product became real. Before that, we had a transcript viewer. After that, we had a coach.
The Gemini feedback going from generic to genuinely useful was the second turning point. When the feedback started referencing the actual question rather than abstract advice, we knew the system was working.
And the decision to keep all historical analysis local — building a deterministic engine instead of burning API calls — meant the progress tracking feels instant and trustworthy.
By running comparison logic entirely offline in src/components/app/ProgressSidebar.tsx, the application computes rolling averages of a user's recent sessions against older sessions to surface immediate, privacy-first trends on their dashboard.
What We Learned
Disfluencies are signal, not noise. Every other tool treated filler words as something to clean up. We built a tool where they are the entire point.
Context defines the value of feedback. The same pattern means different things in different situations. Building that context into the Gemini prompt as a structural requirement — not an afterthought — was the difference between feedback that felt useful and feedback that felt like a horoscope.
Pivoting your audience mid-build is hard but necessary. We started building for people who stutter. We finished building for anyone who has ever frozen mid-sentence in a high-stakes moment. That pivot required rethinking the copy, the modes, the framing, and the social impact story. We're glad we made it.
What's Next
Stress pattern mapping — identifying which question types trigger the most disfluency so users can target their practice specifically.
Environmental simulation — time limits, visible audience indicators, countdown timers — to build resilience for real high-stakes moments.
Psychological well-being integration — moving from tactical speech training toward genuine self-understanding, helping users recognize the emotional patterns behind their speech, not just the acoustic ones.
Our ultimate goal isn't to make everyone sound like a polished presenter. It's to help people say what they mean, clearly and confidently, in the moments that matter most.
Built With
- css
- deepgram
- geminiapi
- next.js
- react
- recharts
- typescript


Log in or sign up for Devpost to join the conversation.