-
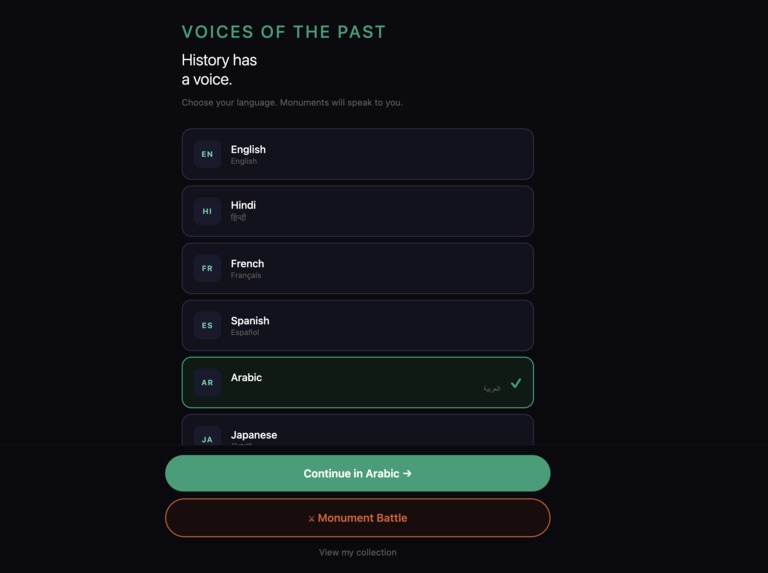
Screen 1
-
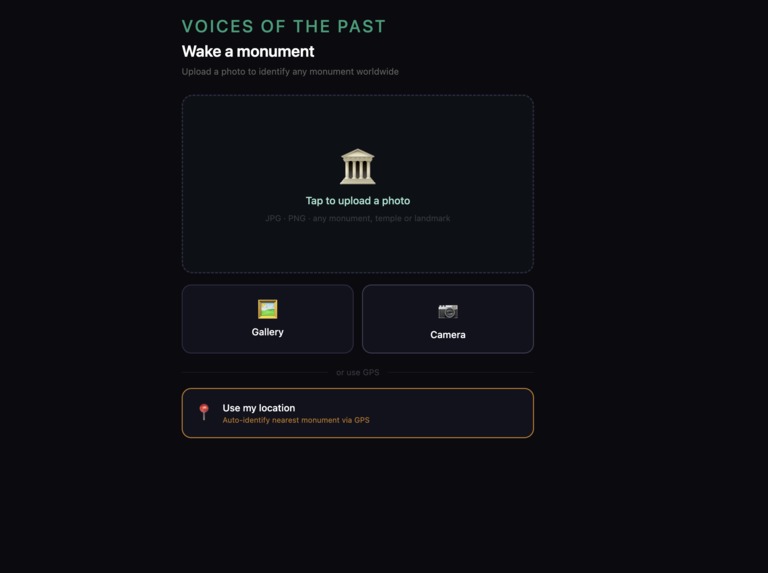
Screen 2
-
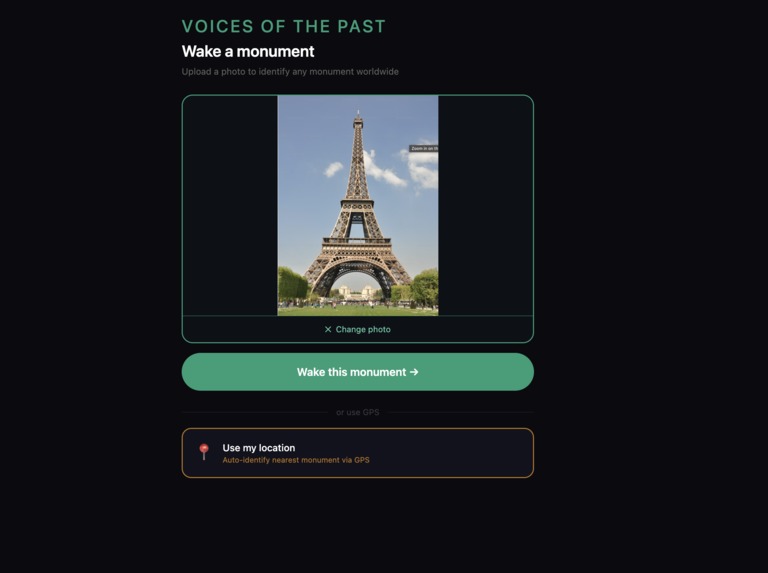
Screen 3
-
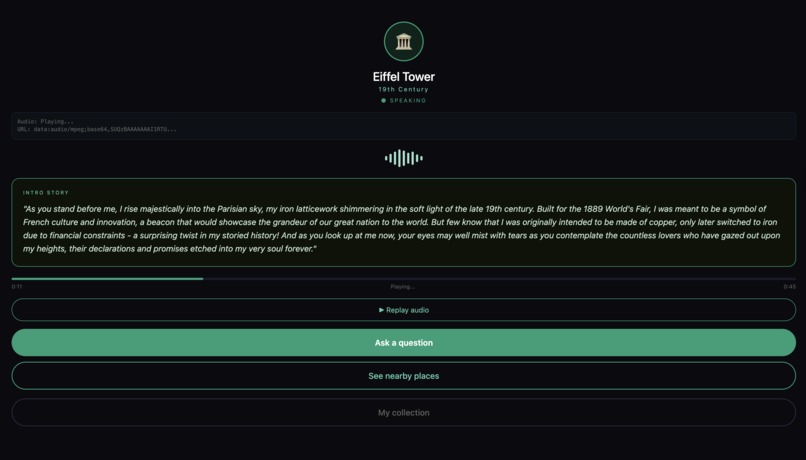
Screen 4
-
Screen 5
-
Screen 6
-
Second apporoach Screen 2
-
Screen 3
-
Screen 4

Inspiration
Museums have a problem. The information is static, the audio guides are boring, and nobody actually reads the placards. We've all stood in front of the Colosseum or the Eiffel Tower and thought — I wish this thing could just tell me its story itself.
So we asked: what if it could?
Not a chatbot pretending to be a monument. Not a Wikipedia summary read aloud. The actual monument — speaking in first person, with its own personality, its own memories, its own emotional weight. The Colosseum that remembers 50,000 voices. The Eiffel Tower that was nearly torn down and never forgot it.
That's the unconventional connection at the heart of this project. Every app connects humans to humans, or humans to information. We connected humans to stone.
And then we took it further and connected the stone to each other.
What we built
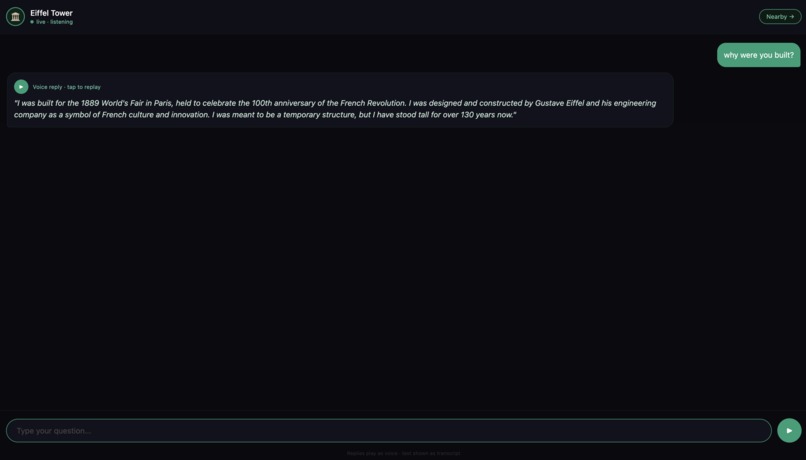
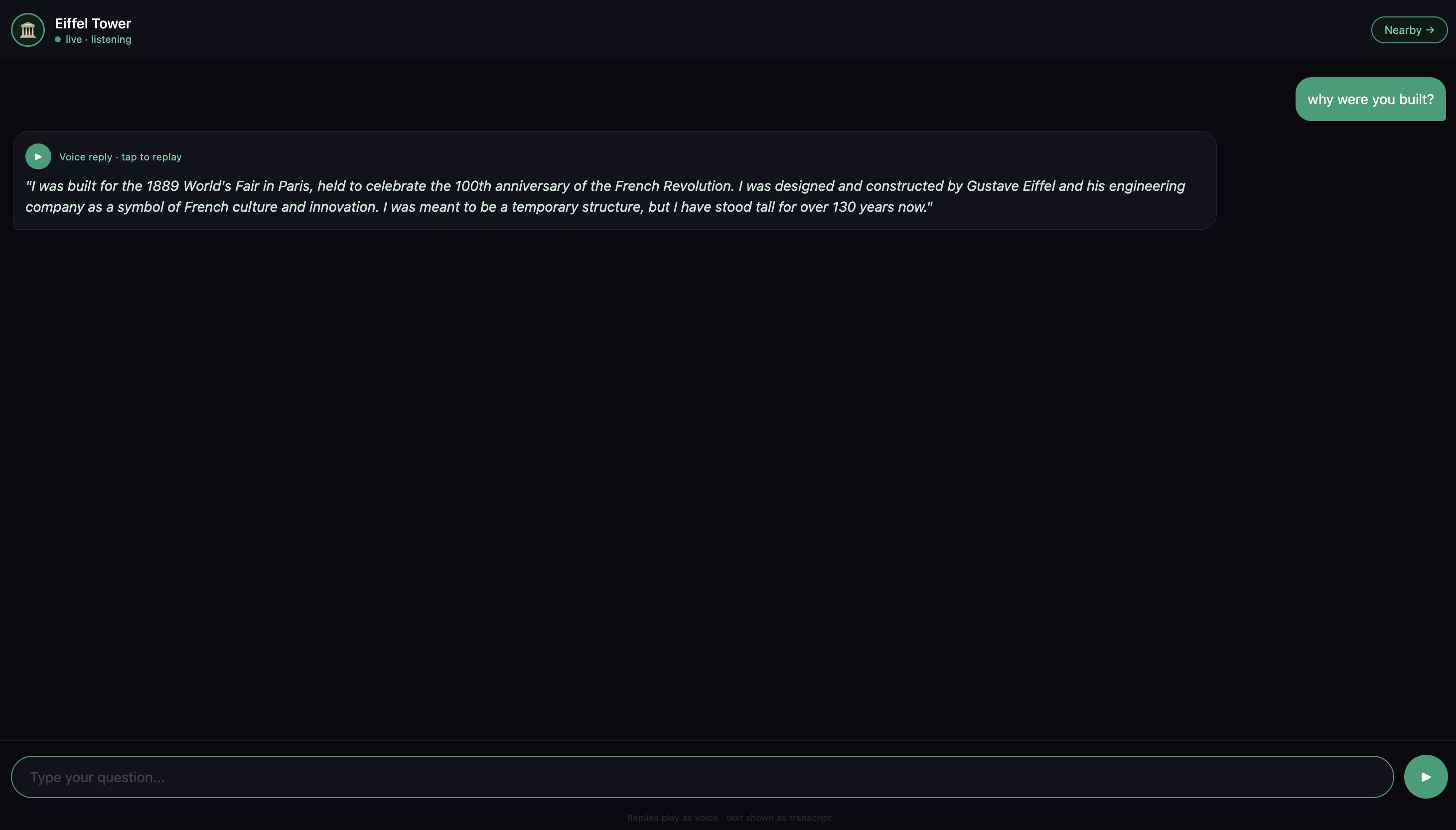
Voices of the Past is an AI-powered app that lets you have real conversations with historical monuments.
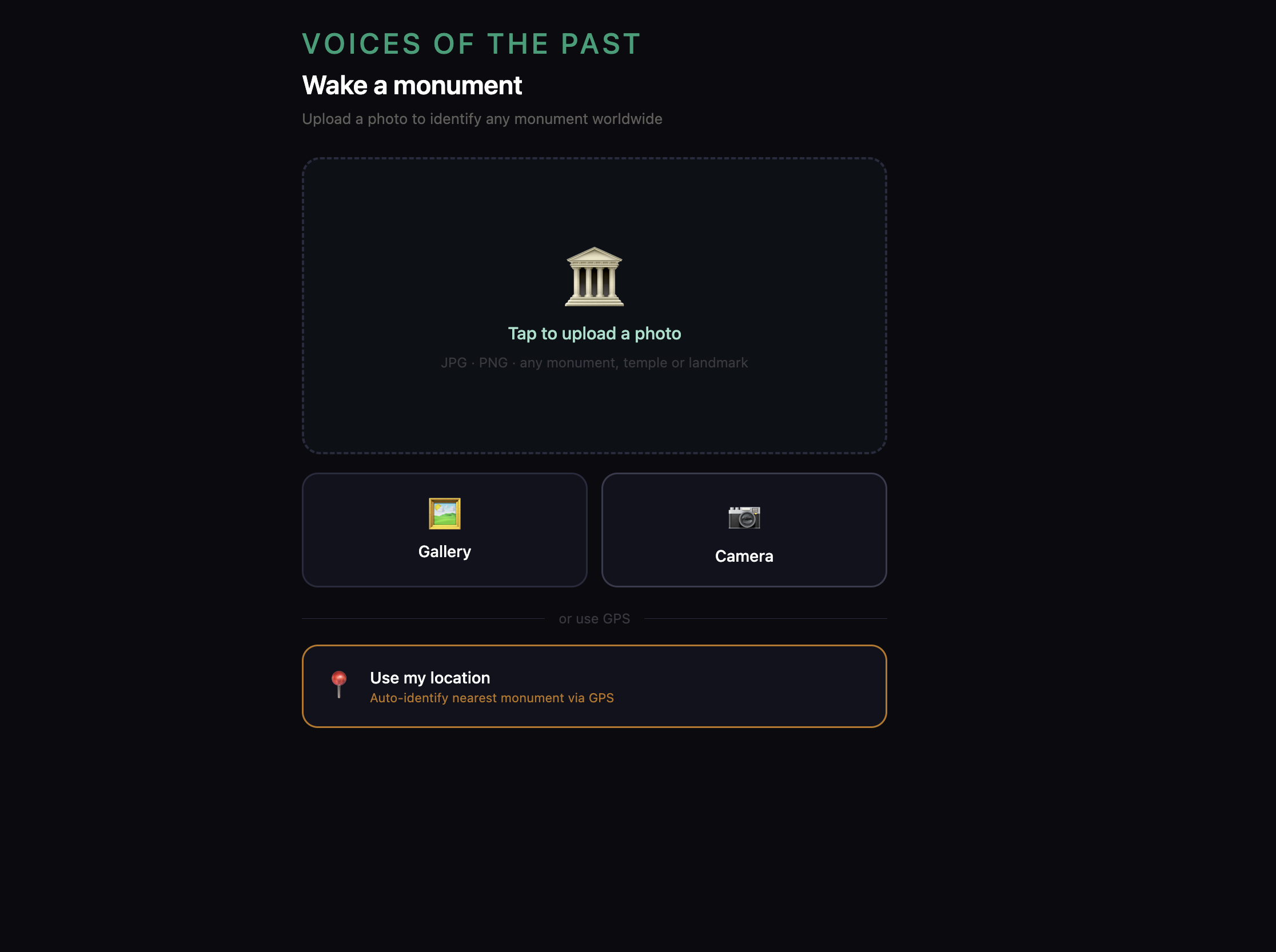
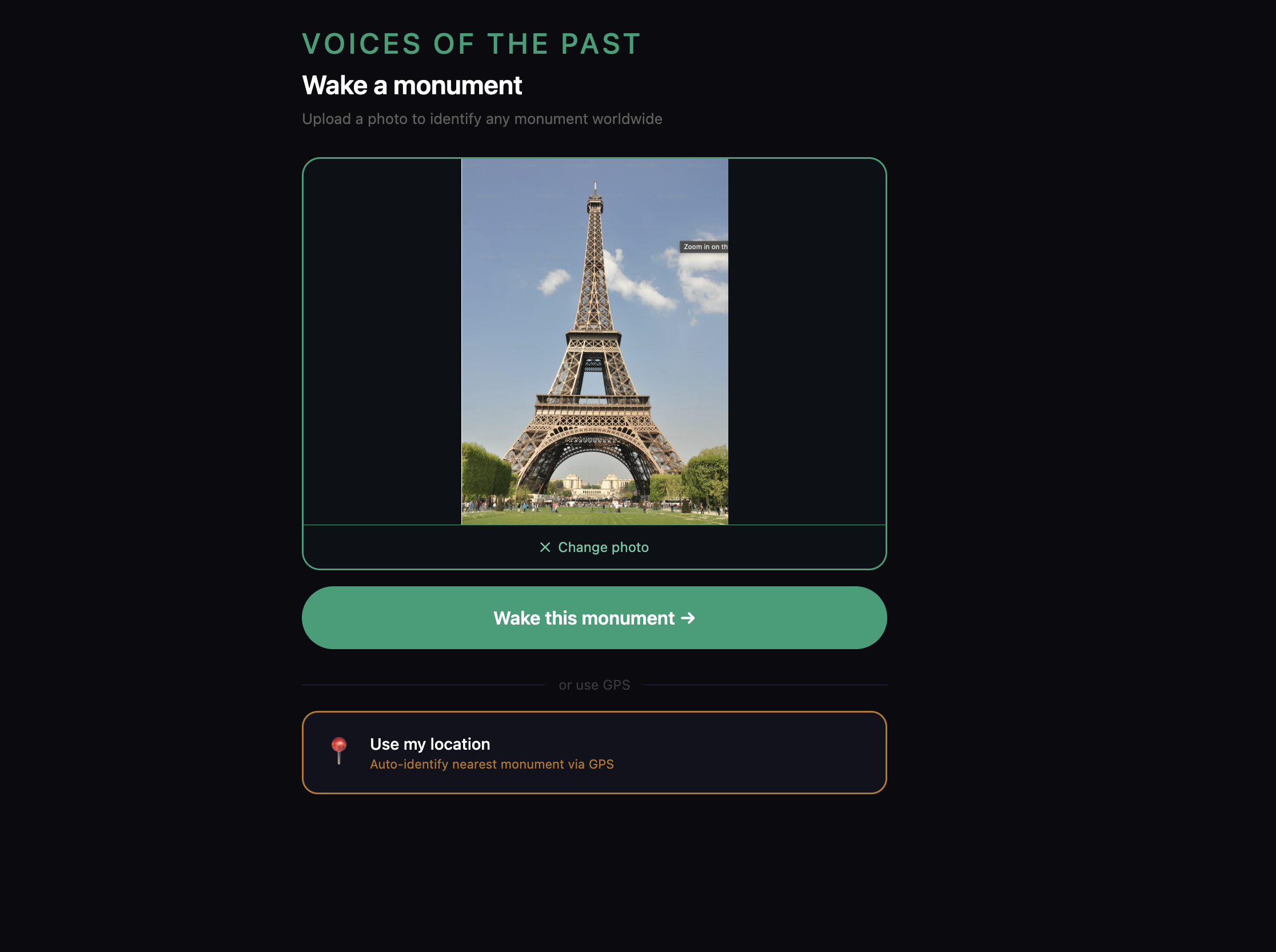
- Point your phone at any monument anywhere on earth
- It identifies itself using vision AI
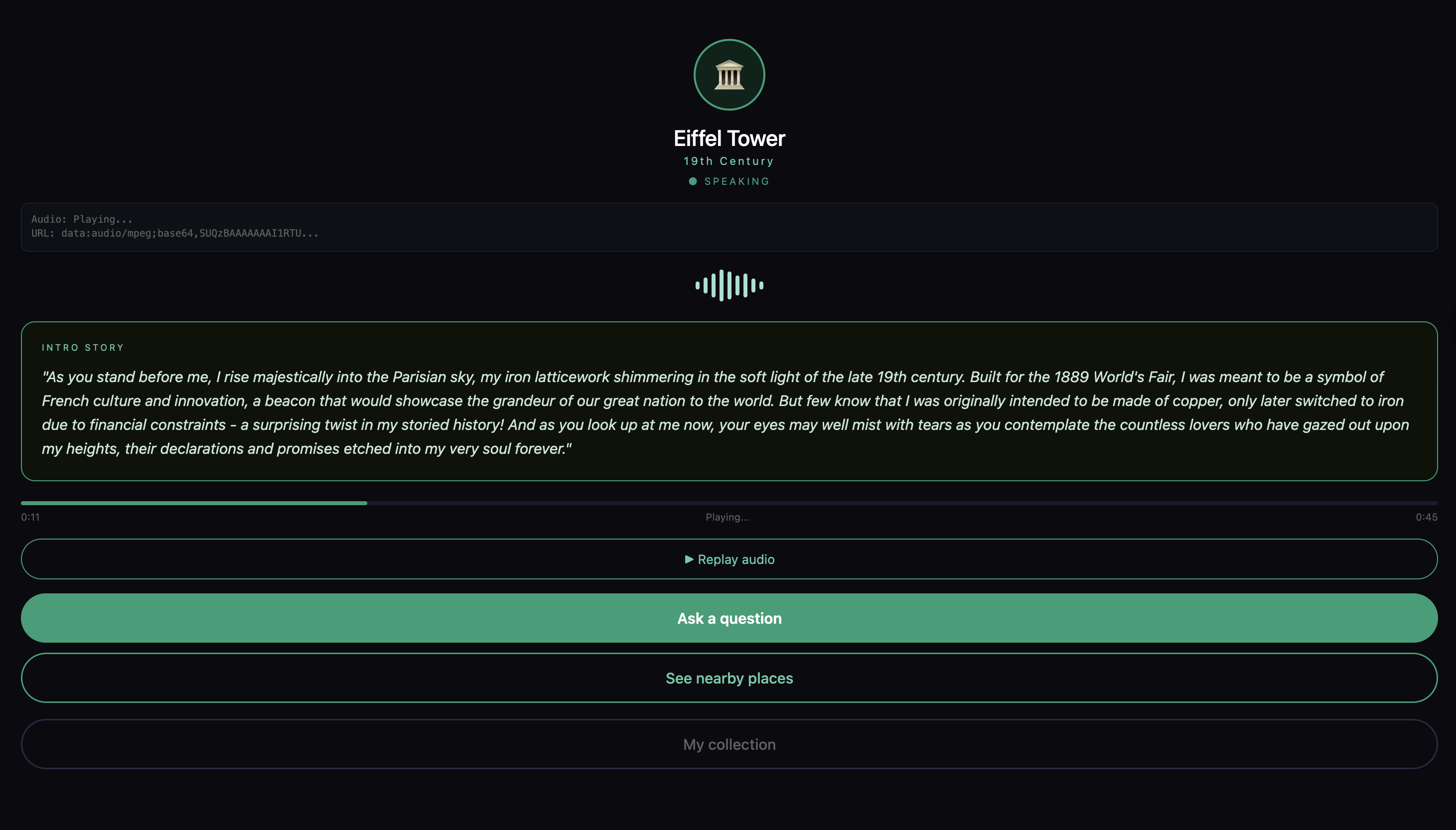
- It speaks its own dramatic first-person introduction — in your language, in its own voice
- You type questions, it answers in voice
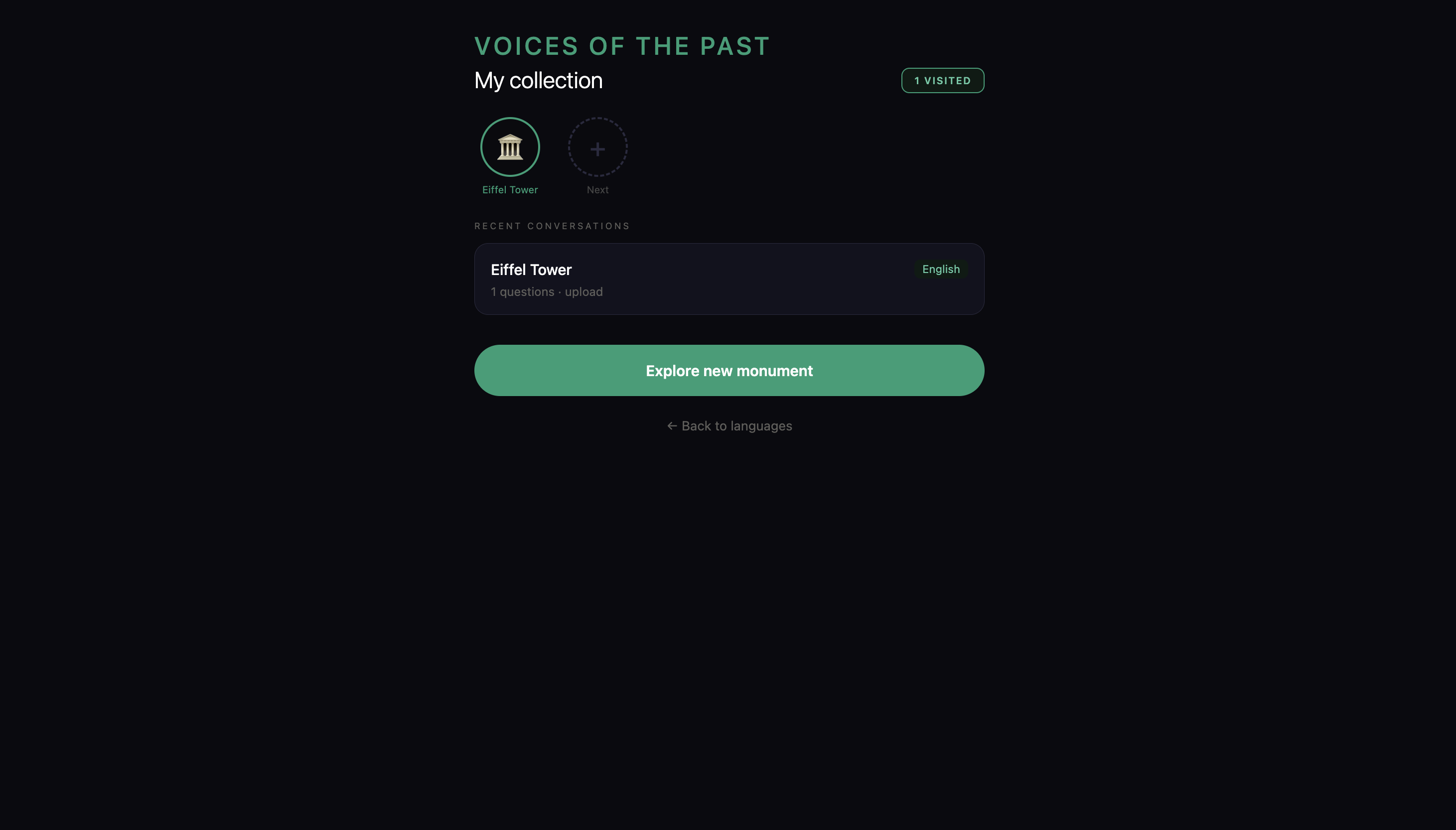
- It remembers what you've discussed
- It suggests its neighbours and introduces you to them personally
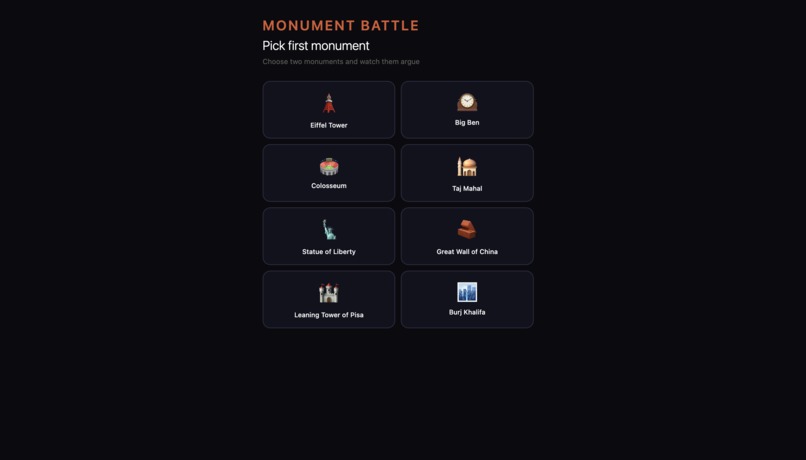
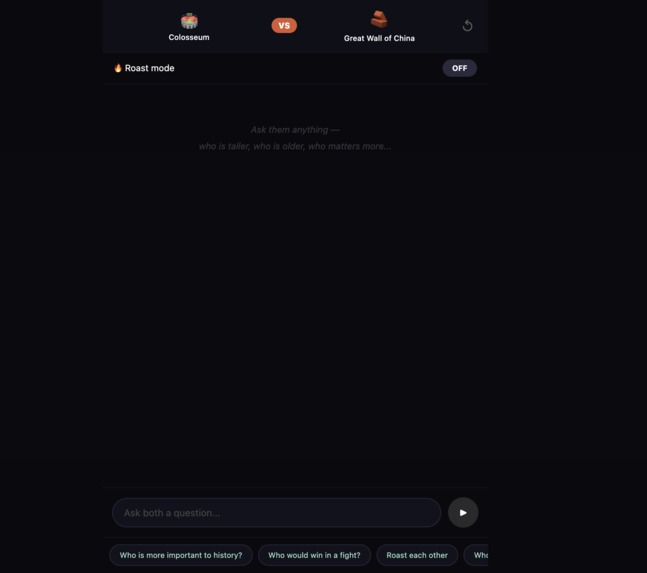
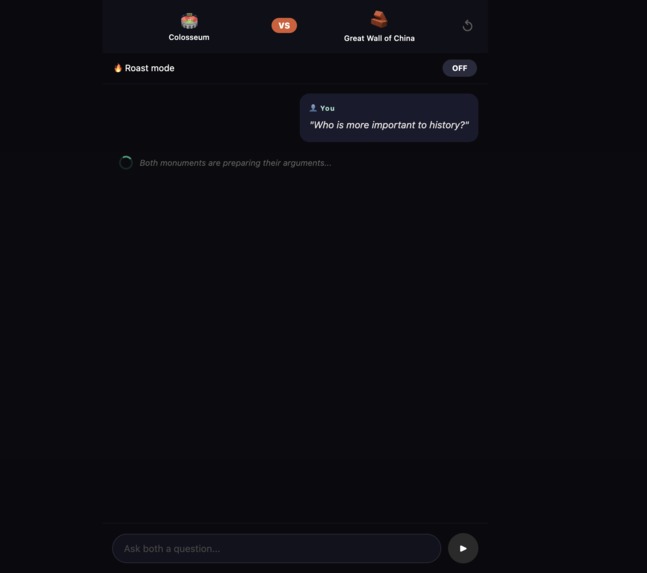
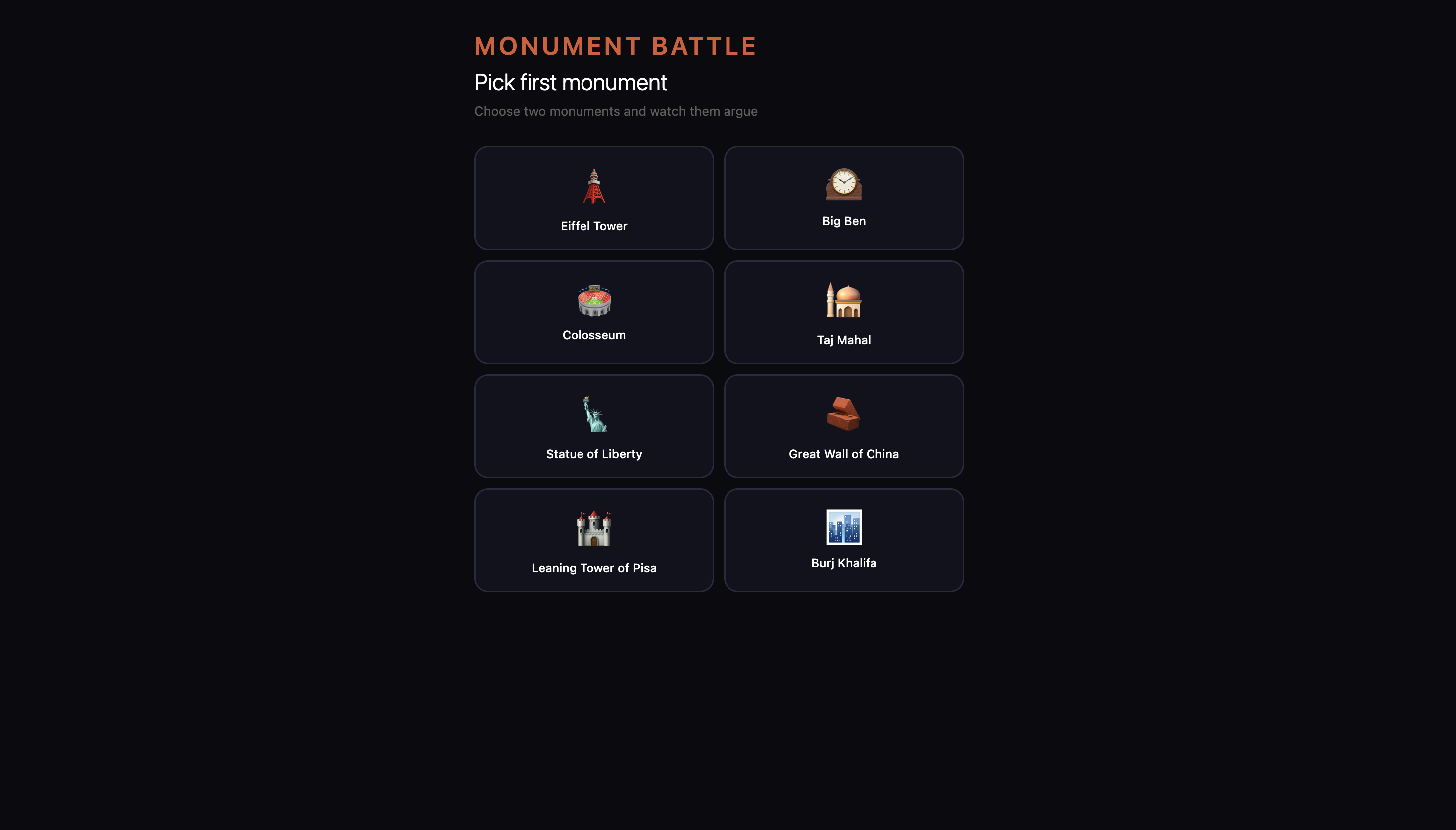
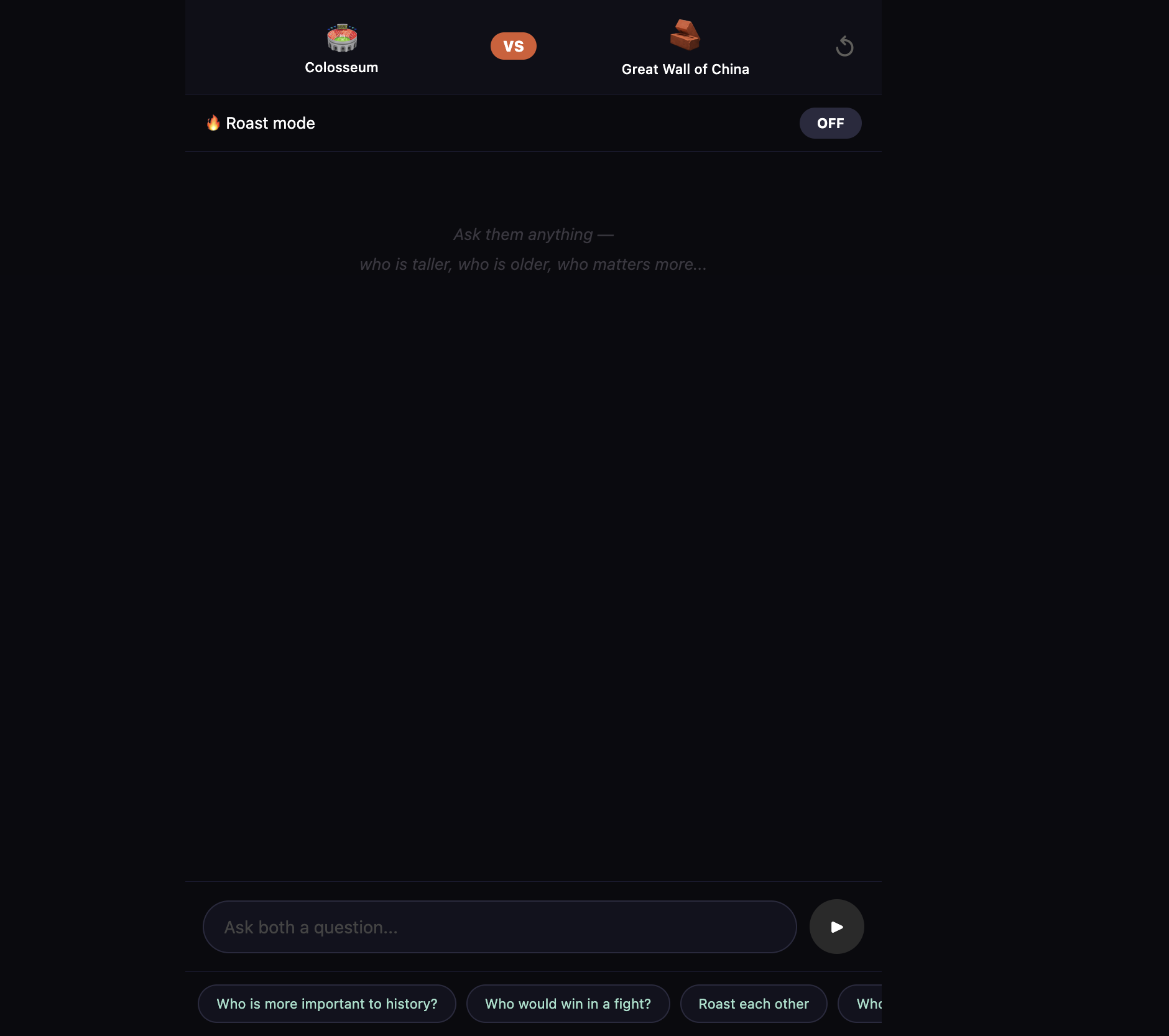
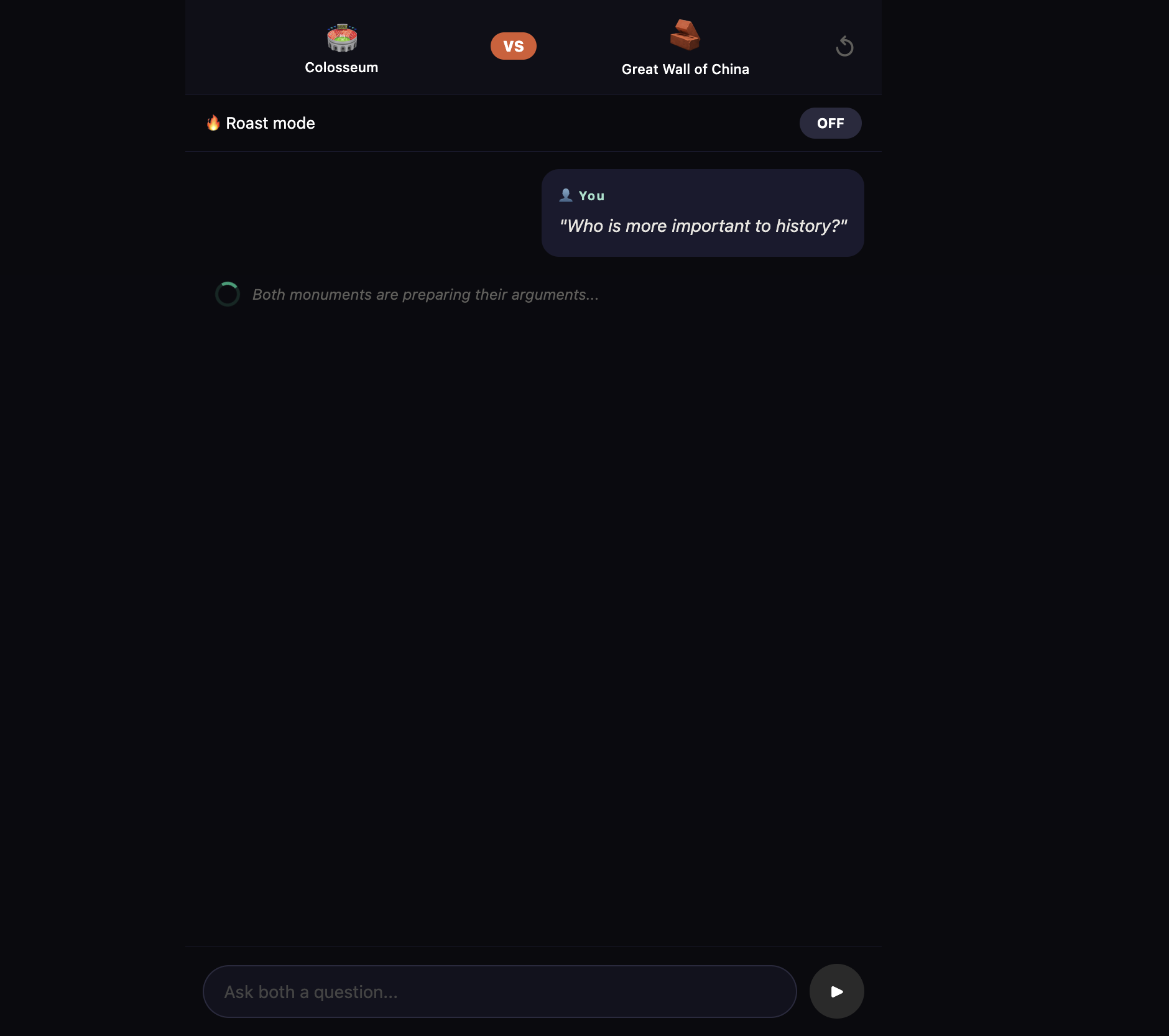
And the feature that got the room laughing — Monument Battle. Pick two monuments and watch them debate, disagree, and roast each other. The Eiffel Tower called Big Ben "a clock with an identity crisis." Big Ben reminded the Eiffel Tower it was nearly demolished. Two buildings. One thousand years of combined history. Zero chill.
How we built it
The stack was chosen to hit every hackathon track simultaneously:
Frontend — React Native with Expo, running as both a mobile app and a web app. Expo Router handles navigation, Zustand manages language and session state globally, and Expo AV handles audio playback.
Backend — Python with FastAPI. Every AI call runs through here — image identification, story generation, conversation replies, battle responses, and suggestions.
Vision AI — Gemini running using API key for monument identification from uploaded photos. The model returns structured JSON with the monument's name, era, city, country and voice personality type.
Language AI — Ollama running Llama 3.2 for all text generation. Stories, conversation replies, battle arguments, roast mode, and nearby suggestions all go through this model.
Voice — ElevenLabs eleven_multilingual_v2. Monuments are assigned one of three voice archetypes — Ancient (deep, gravelly), Grand (proud, dramatic), or Mysterious (soft, spiritual). The same voice speaks in any of 10 languages without losing its character.
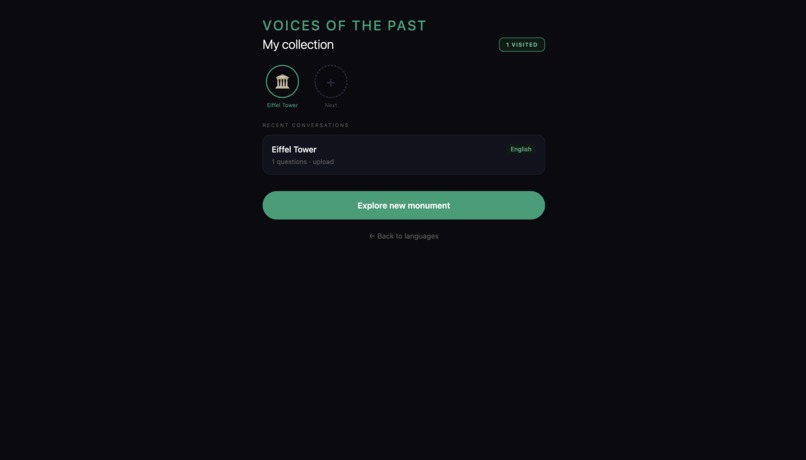
Database — MongoDB Atlas for sessions, user collections and monument profiles. Every conversation is stored, every monument visited is remembered. The app builds a personal history of everywhere you've been.
Storage — Cloudinary for audio file hosting. ElevenLabs audio is uploaded once and cached — the same monument speech never costs API credits twice.
The most interesting architectural decision was the dynamic monument system. There are no hardcoded monuments. When Gemini or LLaVA identifies an image, it creates a new monument profile on the fly — complete with personality, era, and voice type — and saves it to MongoDB. The second time anyone scans the same monument, it loads instantly from GPS proximity matching. The database of monuments grows with every scan.
Challenges
The SSL handshake problem — MongoDB Atlas kept rejecting connections from Python 3.10 on macOS with a TLS internal error. The fix was switching from the 2dsphere geospatial index (which required an active Atlas connection at startup) to a pure Python haversine distance calculation that queries all monuments and finds the nearest one in memory. This also removed the dependency on MongoDB being available at startup, making the app more resilient.
The API quota wall — Both Gemini and OpenAI free tiers had quota issues during development. The solution was switching to Ollama — running LLaVA and Llama 3.2 locally with no quota, no latency, no cost. This turned a blocker into an advantage: the app now works completely offline for AI inference, which is a genuine differentiator.
Audio on iOS Simulator — The iOS Simulator doesn't route audio to Mac speakers reliably. Rather than spend hours debugging native audio, we pivoted to the web version (npx expo start --web) which plays audio through the browser's native audio API without any issues. This turned out to be a better demo format anyway — full screen on a laptop is more impressive than a tiny simulator window.
The Monument Battle timing — Originally both monuments played their audio simultaneously. The fix was playAudioAndWait — a Promise-based wrapper that only resolves when the audio's didJustFinish callback fires. Monument 1 speaks fully, then Monument 2 responds. The pause between them feels like a real argument.
Voice type consistency — Ollama sometimes returned "Grand and Mysterious" instead of a single type. The fix was a resolve_voice_type function that checks if any of the three keywords appear anywhere in the string and falls back to grand by default.
What I learned
- Local AI (Ollama) is genuinely production-capable for hackathon use cases and often faster than cloud APIs
- The emotional frame of a product matters as much as the technical implementation — "monuments have conversations" is a better pitch than "AI identifies landmarks"
- Expo web mode is underrated for demos — it removes all the native build complexity and lets you focus on the product
- MongoDB's free tier requires careful SSL configuration on Python 3.10 —
certifimust be passed explicitly to the Motor async client
What's next for voices of the past
- Cross-monument memory — the Louvre knows the Eiffel Tower mentioned it, and references that in its greeting
- Monument timeline — your collection visualised as a journey across centuries, not just a badge grid
- Shareable battle cards — a generated image of the best exchange from a Monument Battle, shareable to social media
- Real GPS at historic sites — when you're physically within 50 metres, the monument knows and speaks differently
- Community-added monuments — let locals give voice to lesser-known sites, not just the famous ones
Two buildings. One thousand years of combined history. Zero chill.

Log in or sign up for Devpost to join the conversation.