-
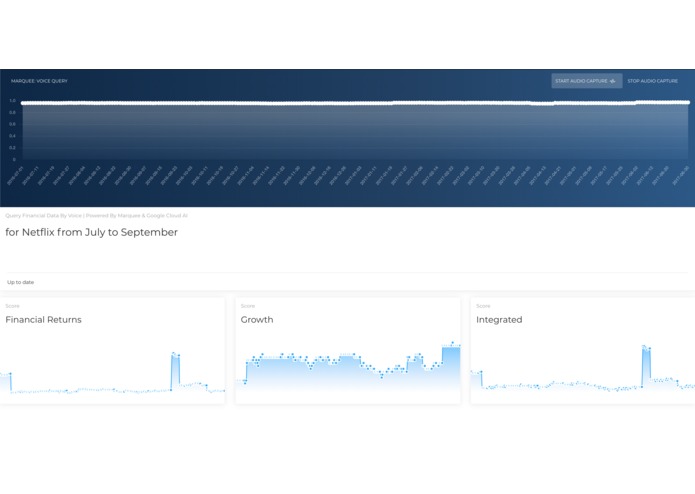
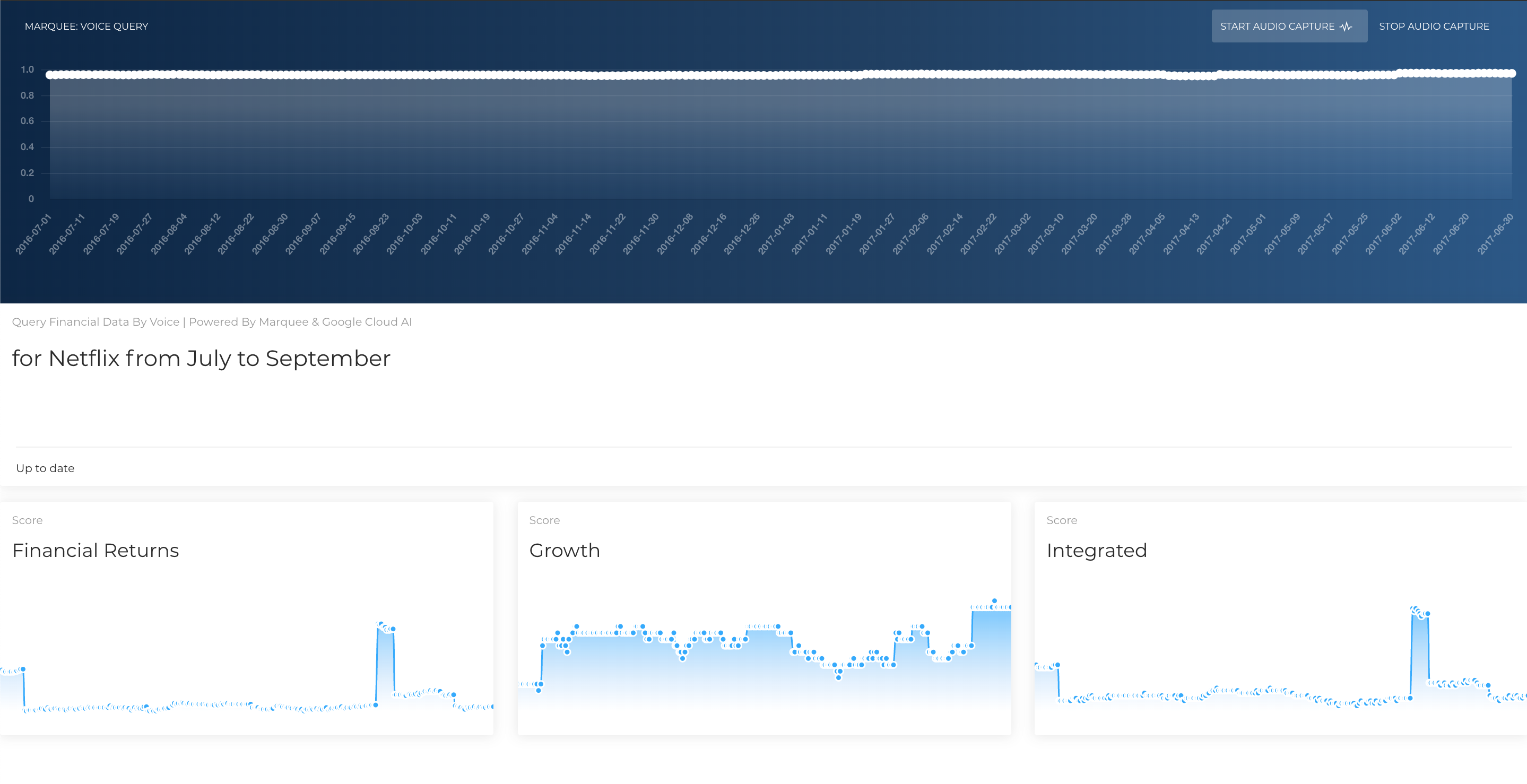
lots of data requested for 'Netflix' (since between two months)
-
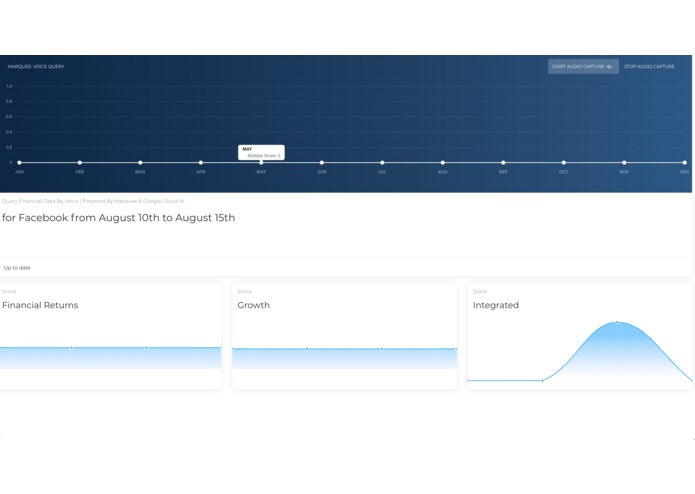
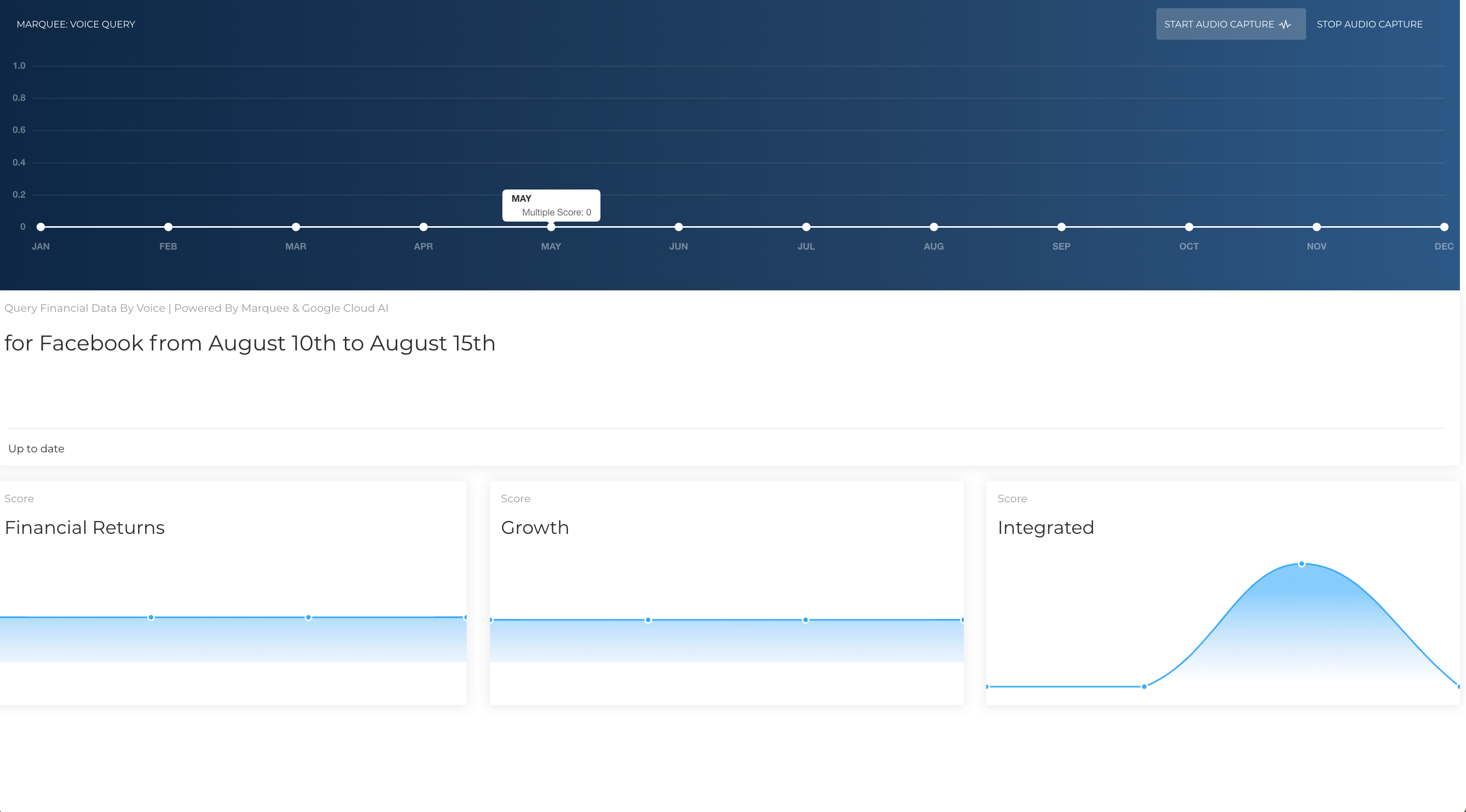
Facebook data for two close dates
-
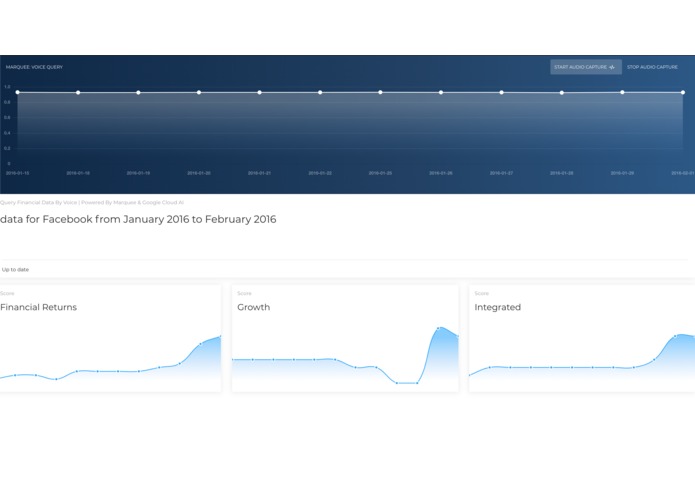
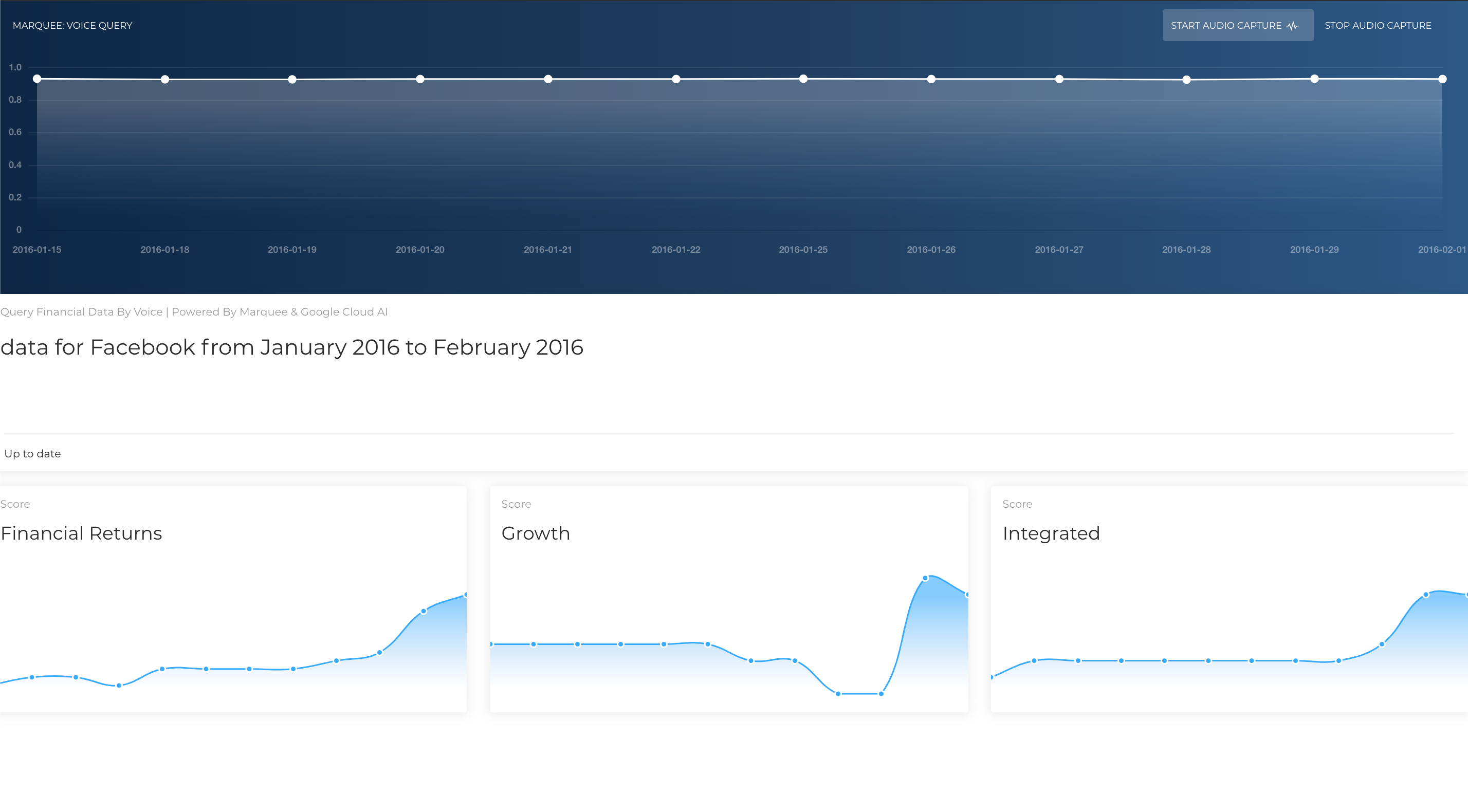
more sparse Facebook data
What it does
The app requests microphone access, initiates a stream of audio and listens. Then Google's Speech API detects when you start talking and when you end, the stream gets interrupted and the raw data is sent to the cloud for inference, and finally - text returns of what you said. The query follows a pretty simple format: just mention the company or that the query is for a "company" and a range of dates. My app reads the data (text transcript) back in, parses it, tries to understand what exactly you'd want returned and makes a query to my Python server.
In the process of parsing the data, I'm performing a mapping from the keyword that was used in the spoken query to a ticker, or more exactly a unique id that Marquee uses to identify resources. (Ex: Facebook -> 'FB' -> 1001 and visa versa). I wrote a couple helper lambda functions to fetch the "coverage" of the set (i.e. all the resources/companies and their metadata that I might be interested in for the purposes of hack). The data now comes back from server, and the UI is updated with the 4 key metrics plotted as described in the Marquee dataset. The horizontal axis scales with the number of datapoints / dates, so if you request data from dates that are far apart, there will be plenty of datapoints on the 4 graphs.
The UI also changes as you speak to show you what Google AI thinks you're saying.
The queries currently tested:
Saying only the name of company: returns a random slice of a dataset (this is just for fun to see different graphs): For example: "Facebook", "IBM", "Netflix"
Query spoken in format of:
data for from to
Years are a bit tricky since the dataset limits some dates.
How I built it
Node.js server, socket.io for streaming audio data, some html/css/bootstrap on front end, Python Flask server to query the Marquee API efficiently. Finally, Google Cloud Speech to Text API and App Engine Deployment!
The Node server is responsible for serving some static content and also has the scripts that parse the text from Google Speech to determine the dates that the user is asking for and the company name.
I would say that I divided my hack into 3 categories as I was working on it: Marquee queries, audio streaming + text-to-speech, and text parsing / analysis to extract the meaning from a text-to-speech transcript and build up the next request - effectively looping back to category 1, i.e. make the next query to get the data that the user is speaking of.
Challenges I ran into
Figuring out how to stream the audio from the laptop microphone and send it to cloud in correct format was a nightmare and thank you to Google Cloud team for helping out where they could. Also updating the graphs on the UI was difficult to make smooth.
Parsing the text is still a work in progress and I hope to improve it so that all spoken queries are answered correctly. My idea for a reasonable addition to the hack would be to deploy a full language model on this, to see if we can extract multiple resources / companies / tickers at the same time and build up complex queries that can return lots of combined data from Marquee.
Accomplishments that I'm proud of
Proud of figuring out audio and parsing text to determine what the user is asking for

Log in or sign up for Devpost to join the conversation.