-
-
Login
-
Persona Selection
-
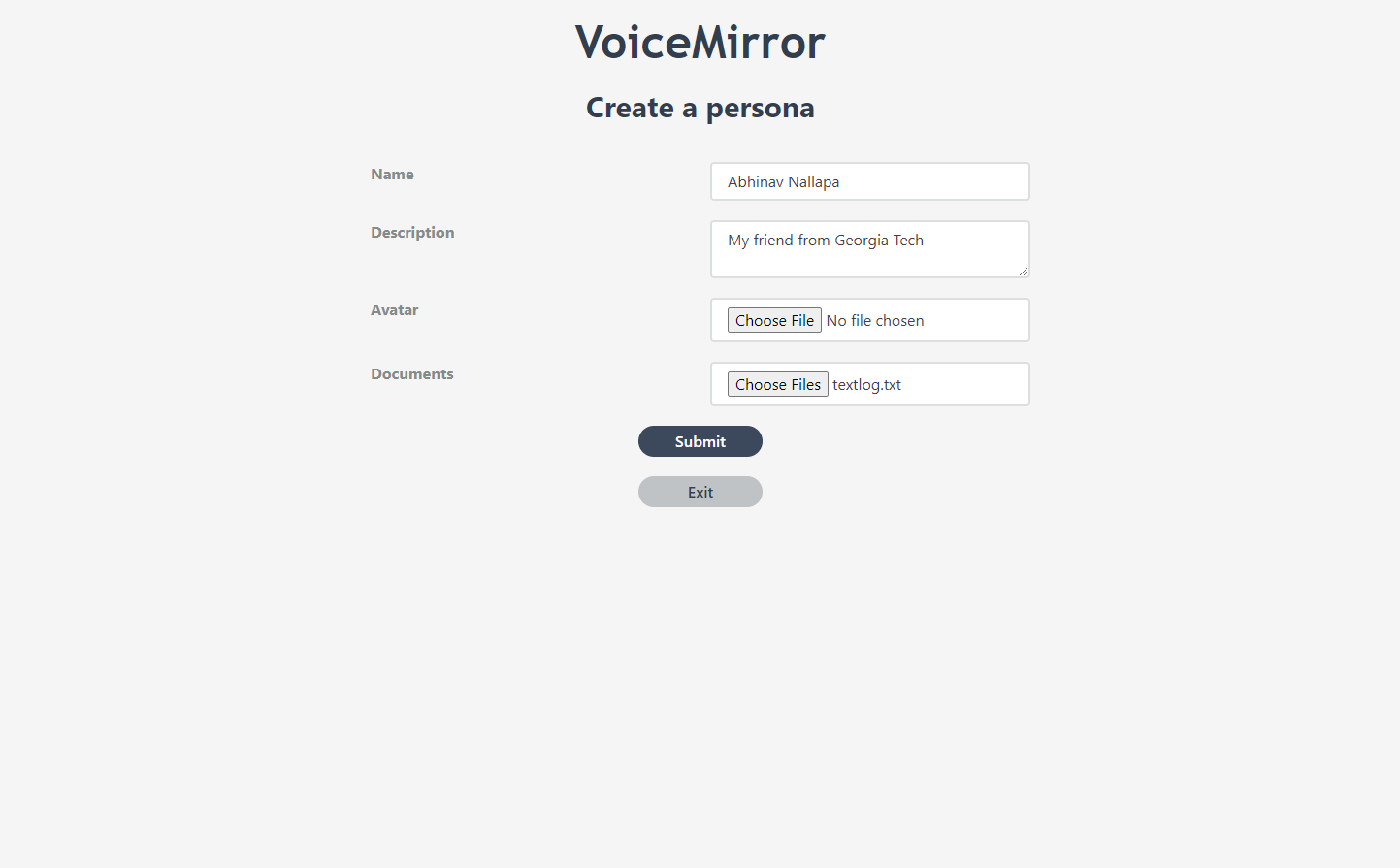
Adding a Persona
-

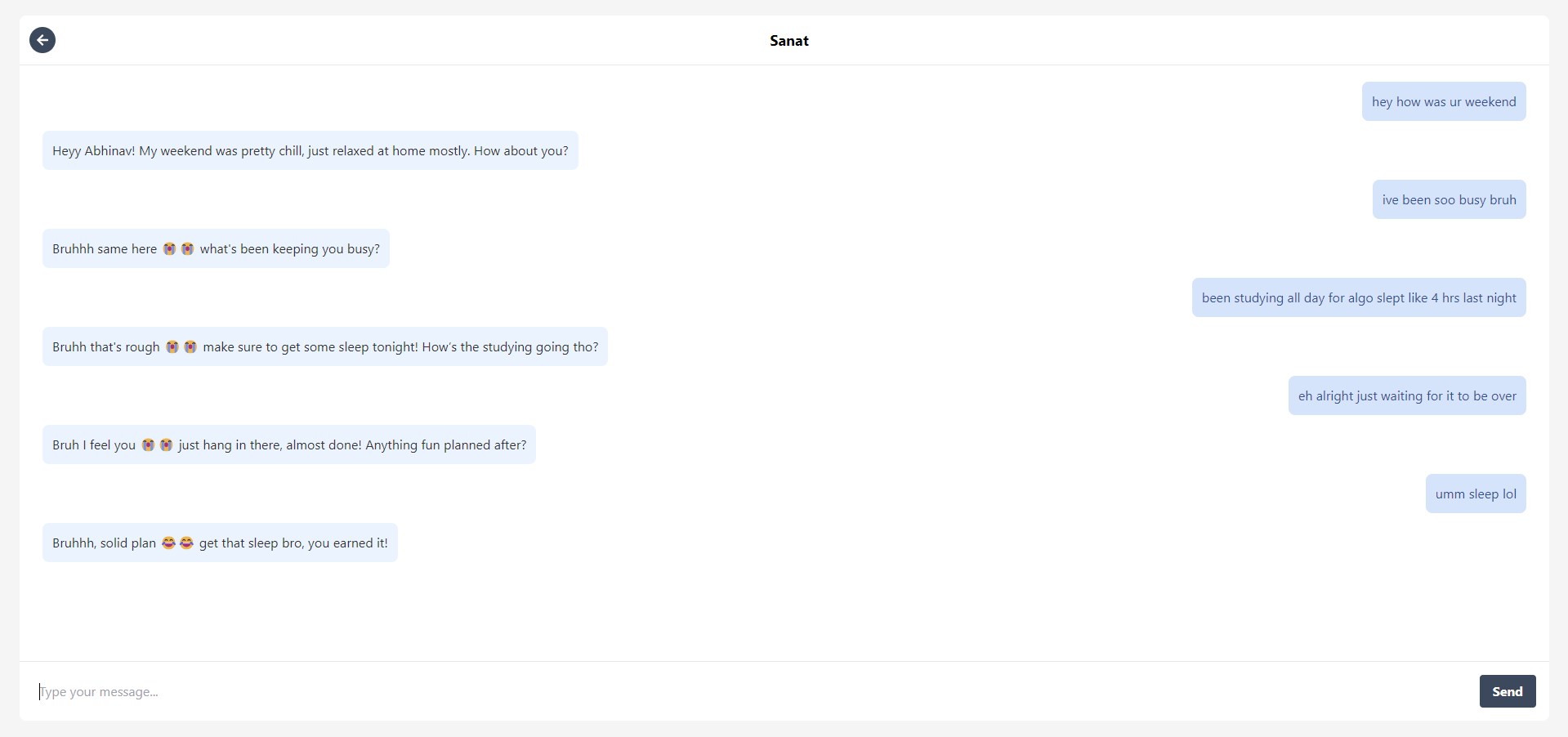
Conversations with a persona
-
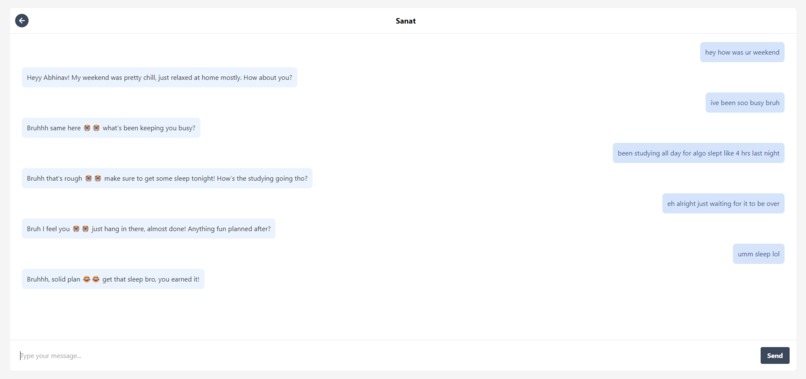
Conversations with a persona

Inspiration
When people text, they have unique texting styles that reflect who they are whether its TEXTING IN ALL CAPS or using an 😈 excessive 👿 amount 👹 of👺 emojis 🤡. We thought it would be interesting to see if we could get AI to match our personalities using our text conversations, so one day, we could emulate Gilfoyle and ignore all of our Slack messages. That's why we built VoiceMirror, a web application that lets people take documents of conversations and build their own personas that they can talk to and play around with.
What it does
When a user logs into our application, they will have the ability to upload text documents that have a persons conversation history in them, and when they do that, the conversations will be stored in a vector database. Then, when the user talks to the persona, the persona uses GPT-4 with Retrieval Augmentation Generation (RAG) to adopt the style and get relevant context to respond. Users will also be able to edit their personas by adding additional documents, and all raw text is encrypted to ensure security.
How we built it
We built the web application's frontend using React, interfacing with a FastAPI server that handles several endpoints for parsing data, user authentication, and response retrieval. To process conversation history, we implemented a sliding window approach that chunks the data into smaller overlapping segments, ensuring more coherent retrieval of conversation pieces from the vector database. For the vector database, we used MongoDB Atlas’s VectorSearch, indexing the collection by persona. Finally, we applied standard prompting techniques to enable GPT-4 to leverage the retrieved documents as contextual information for generating more accurate responses.
Challenges we ran into
Initially, we considered fine-tuning a smaller base model to personalize it, but we realized that approach would be too time-consuming. Instead, we shifted to using retrieval-augmented generation, which required an efficient way to store conversation history for high-quality LLM context. Our goal was to treat each sub-conversation as its own document, but determining clear start and end points in variable-length conversations proved challenging. Ultimately, we adopted a fixed sliding window approach, ensuring that the LLM would always have sufficient context to capture the persona's style.
Working with MongoDB's VectorSearch was a learning curve since it was our first time handling vector databases, but we managed to get it working. Additionally, we were cautious about testing with our text conversation data, as we wanted to respect each other's privacy. To prevent any accidental exposure of private conversations (and gossip ☕), we encrypted all data to ensure complete confidentiality.
Accomplishments that we're proud of
We're proud to have completed this project despite the time constraints we faced over the weekend. We're also excited about the solid results we achieved and, above all, the fact that we had a great time working on it together.
What we learned
We learned more about the strengths and limitations of retrieval augmentation and learned how to effectively work with vector databases. We also discovered that, as a team, we're all pretty dry texters. 😅
What's next for VoiceMirror
In the future, we'd like to explore fine-tuning models to build more personalized personas and improve our conversation chunking method. Additionally, we’re curious to see how our personas adapt their communication styles based on different recipients. There’s also potential to evolve this project into a plugin, enabling features like autocomplete or other AI-driven enhancements.

Log in or sign up for Devpost to join the conversation.