-
-
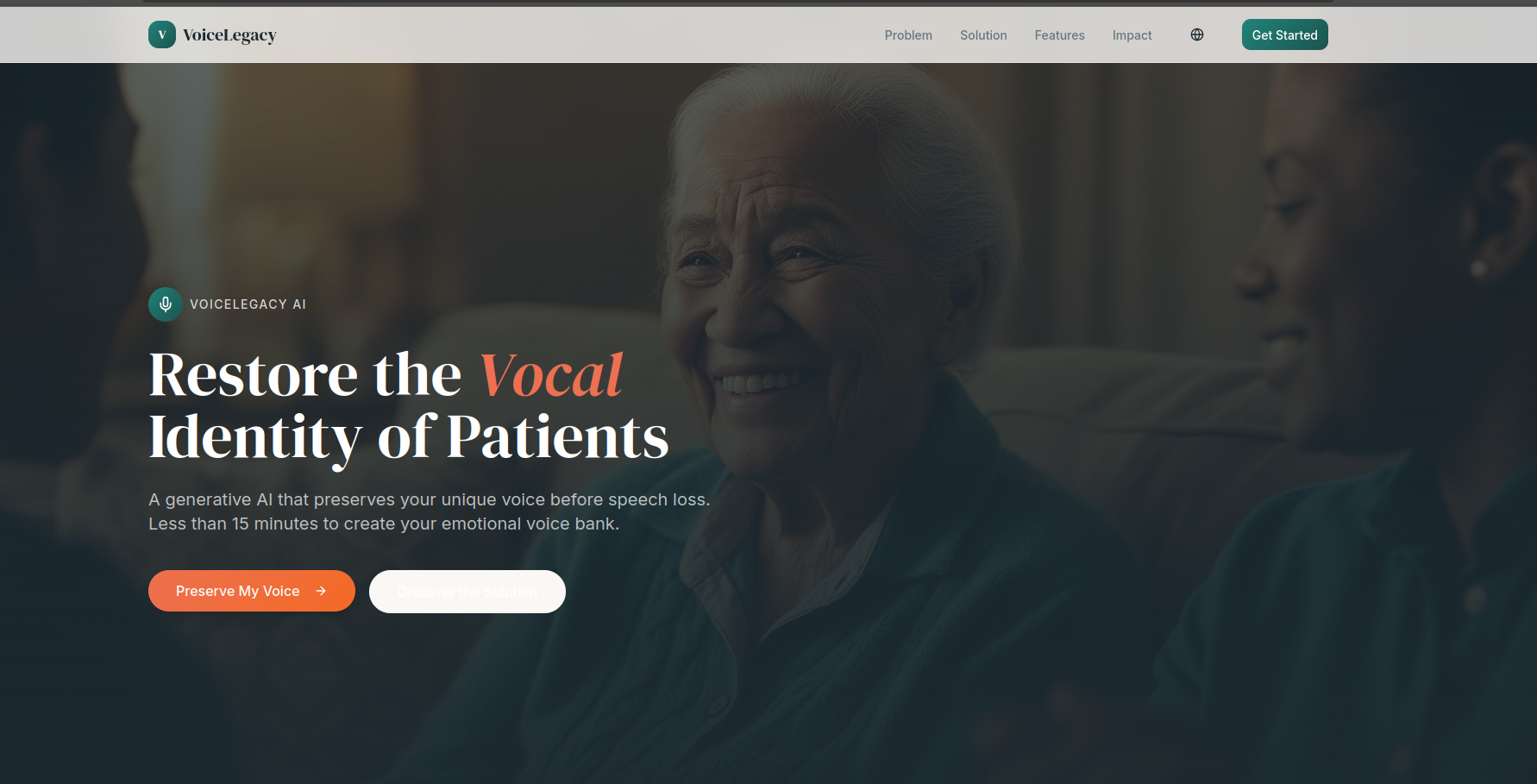
landing_page
-
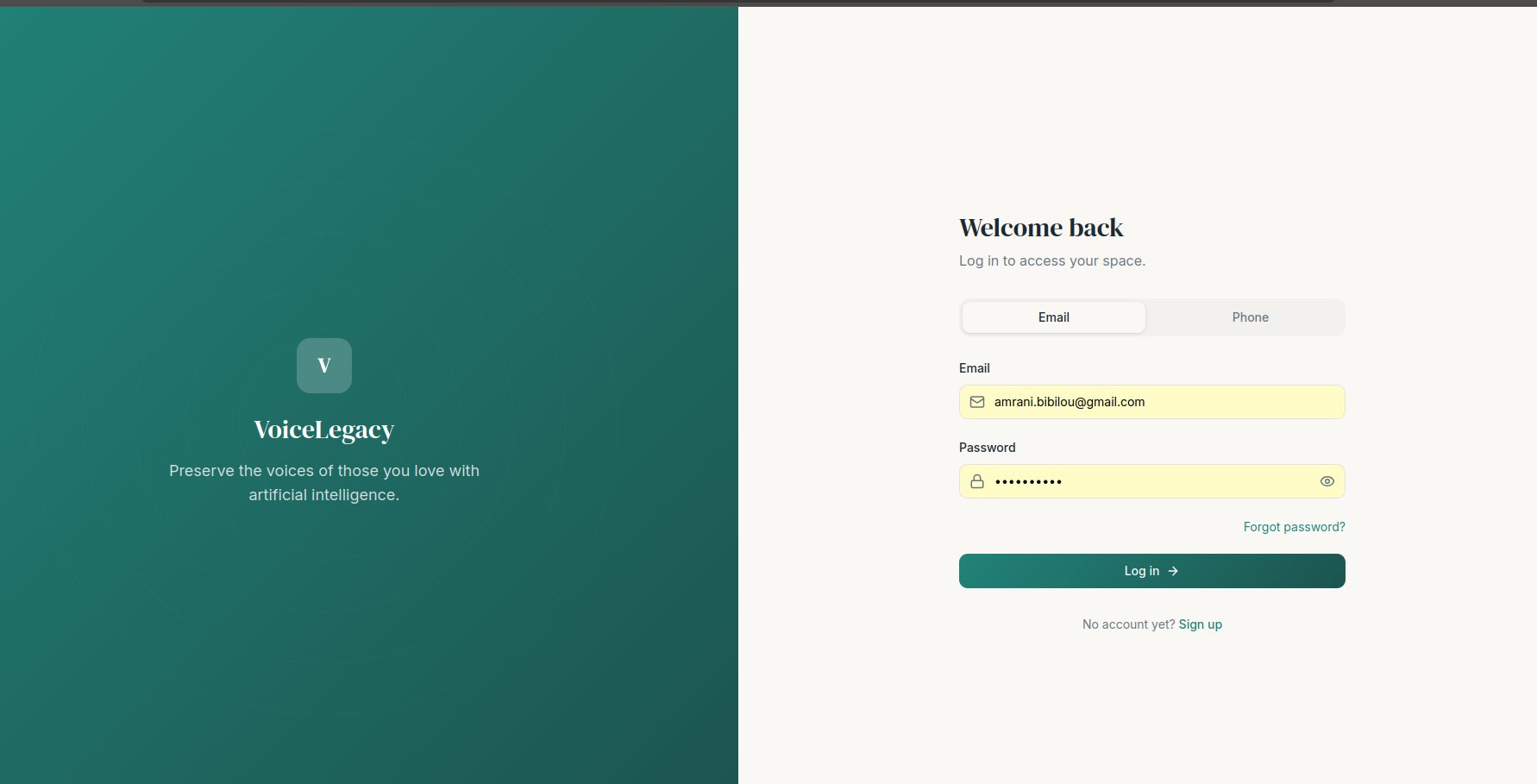
auth_page_with_email_verification
-
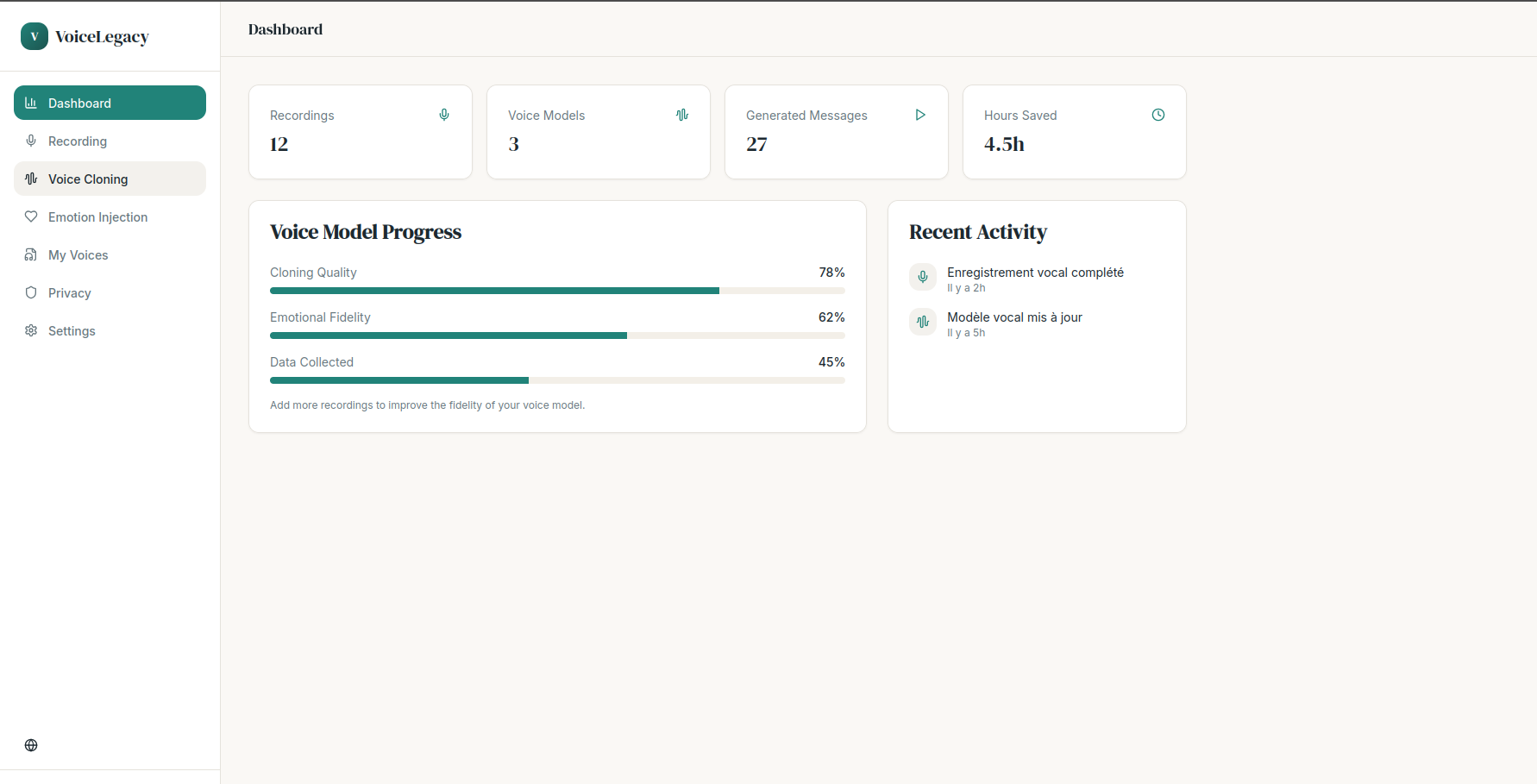
dashboard
-
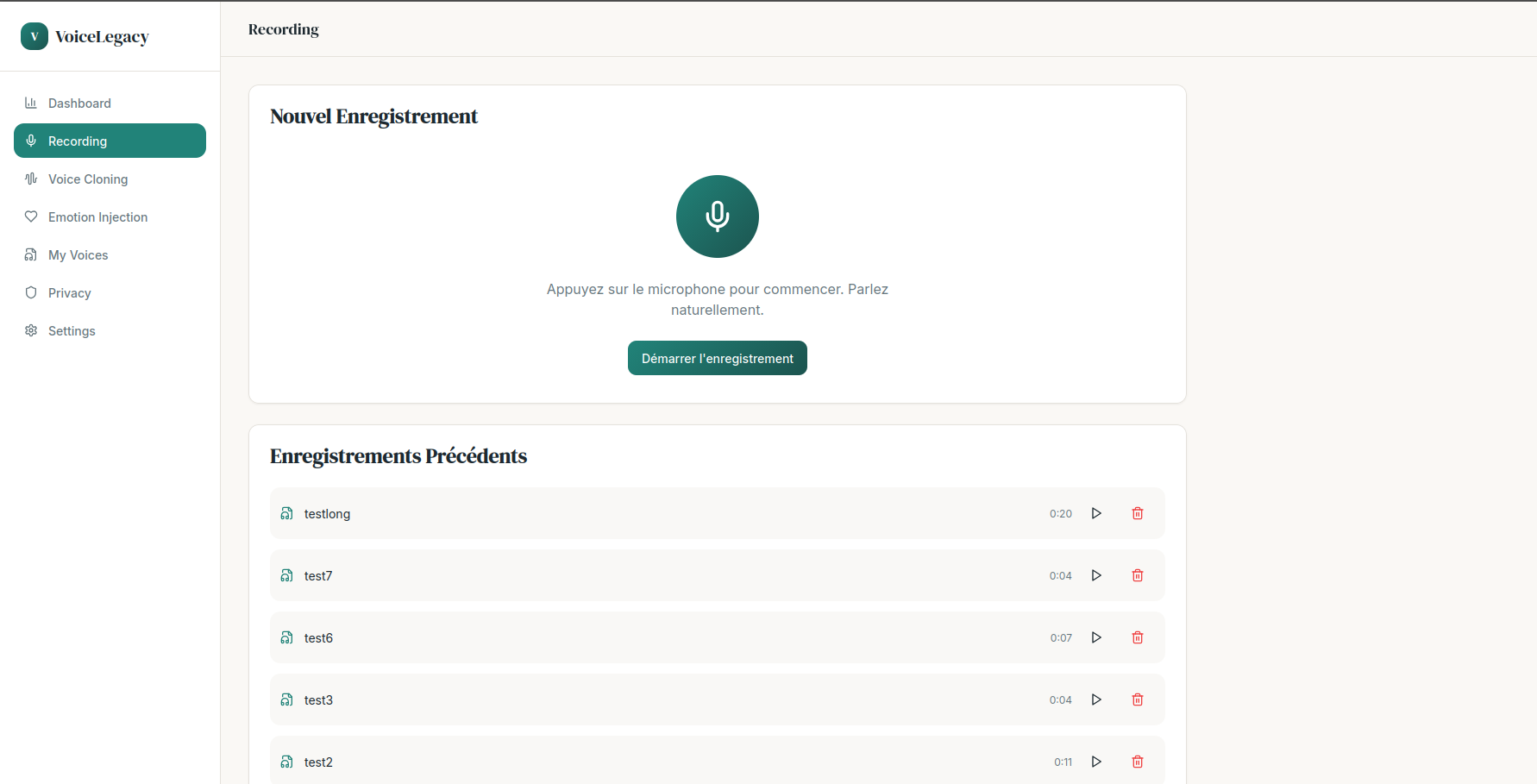
recording_page
-
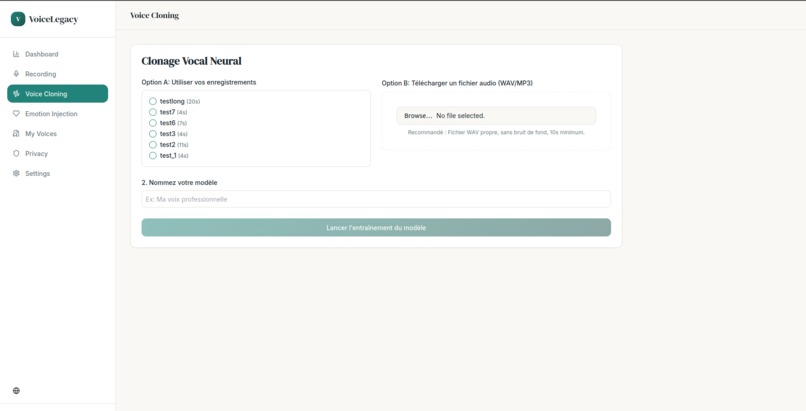
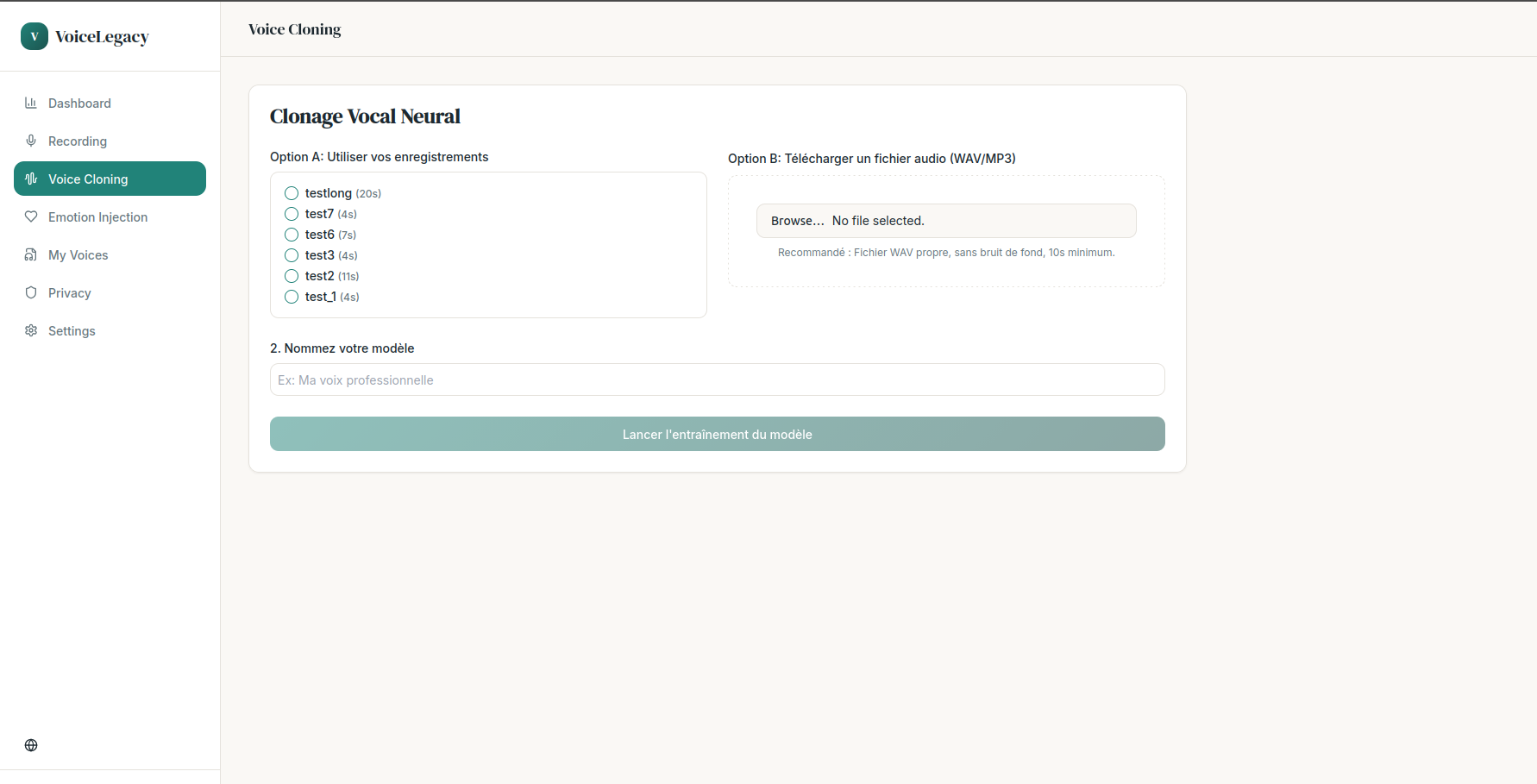
cloninig_page
-
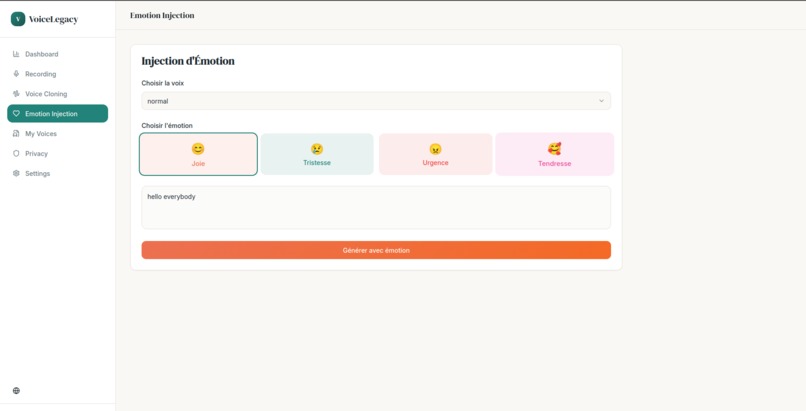
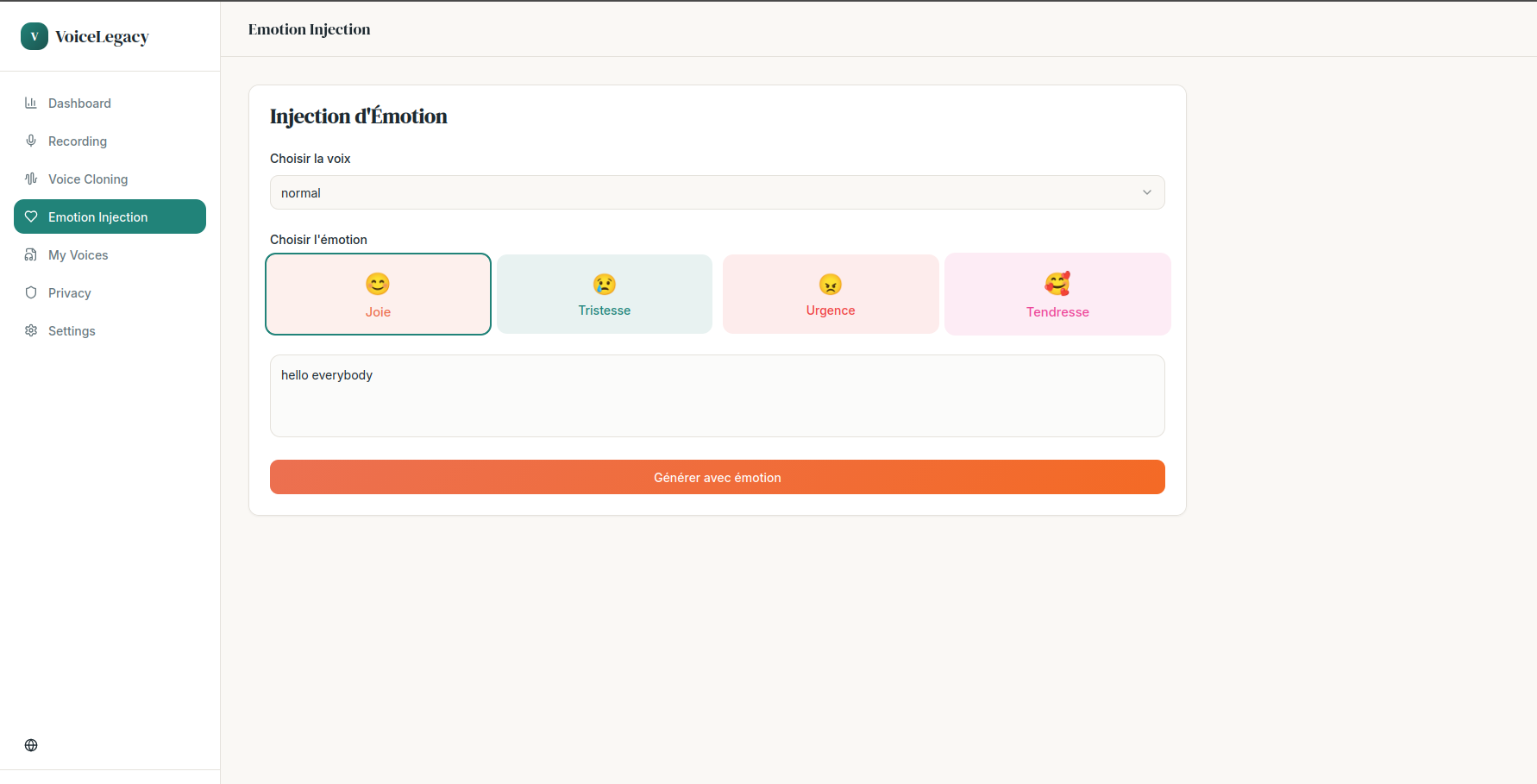
emotion_injection
-
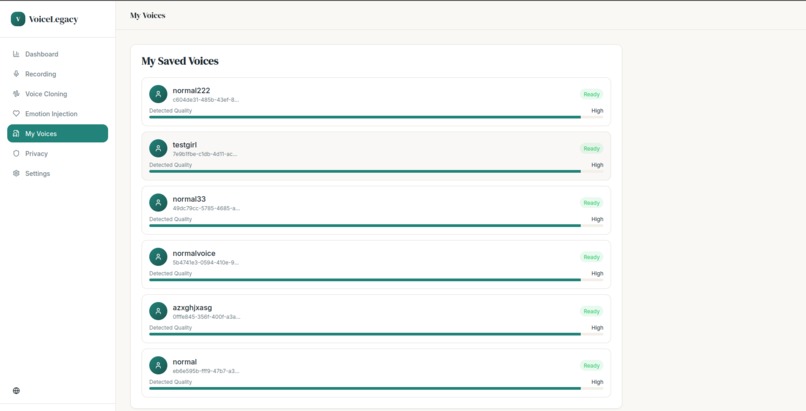
outputs_page
Inspiration
The idea for VoiceLegacy was born from a simple but profound realization: our voice is a fundamental part of our identity. For millions of people facing conditions like ALS, throat cancer, or simply the natural aging process, the fear of losing their ability to speak—and to sound like themselves—is overwhelming. We wanted to build a tool that doesn't just generate speech, but preserves the person behind the voice. We believe that technology should be used to safeguard our human legacy, ensuring that even if the physical ability to speak is lost, the unique warmth and emotion of a person's voice remains.
What it does
VoiceLegacy is a privacy-first AI platform that allows users to create a faithful digital replica of their voice. By recording just a short audio sample, users can "bank" their voice while they are healthy. The system then uses this data to generate authentic, emotionally resonant text-to-speech. Unlike standard robotic TTS, VoiceLegacy captures the unique timbre, accent, and prosody of the user. It empowers users to communicate with their loved ones in their own voice, maintaining that critical emotional connection.
How we built it
We built VoiceLegacy with a hybrid architecture prioritizing performance and privacy:
Frontend: We used React with TypeScript and Vite for a responsive, modern interface. Tailwind CSS and Shadcn UI were used to ensure accessibility and a clean aesthetic. We implemented a custom in-browser audio recorder using the Web Audio API to capture high-fidelity samples. Backend: The core AI logic runs on a FastAPI (Python) server. We integrated Coqui TTS (XTTS v2) for its state-of-the-art zero-shot voice cloning capabilities. Detailed audio processing and normalization are handled server-side with ffmpeg. Storage & Security: We leveraged Supabase for its robust PostgreSQL database and Auth system. We implemented strict Row Level Security (RLS) to ensure that a user's biometric voice data is cryptographically isolated and accessible only to them.
Challenges we ran into
One of the biggest challenges was handling the audio format compatibility between the browser and the AI model. Browsers typically record in compressed formats like WebM/Ogg, while the XTTS model requires specific 24kHz mono WAV files. We had to build a robust transcoding pipeline using ffmpeg to essentially "clean" and normalize every upload before it touched the AI model. Another challenge was managing the inference latency of the large AI models while keeping the UI responsive, which we solved with asynchronous processing and optimistic UI updates.
Accomplishments that we're proud of
Accomplishments that we're proud of We are incredibly proud of the "privacy-first" implementation. In an era where AI often feels invasive, we built a system that gives users ownership of their biometric data. We're also proud of the quality of the voice cloning—hearing the AI speak with the unique emotional inflection of the original user for the first time was a magical moment for us.
What we learned
We learned a tremendous amount about the intricacies of digital signal processing and the current state of generative voice AI. We also gained deep experience in architecting full-stack applications that bridge the gap between heavy Python AI backends and lightweight Javascript frontends.
What's next for voicelegacy
We plan to implement real-time streaming audio to reduce latency further, allowing for near-instant conversation. We also want to explore "Emotion Sliders" to give users fine-grained control over the emotional weight of the generated speech (e.g., whispering, shouting, or speaking tenderly). Finally, we aim to bundle the application into a mobile app to make voice banking accessible to anyone with a smartphone.
Built With
- coqui-tts
- docker
- fastapi
- ffmpeg
- postgresql
- python
- react
- supabase
- tailwind-css
- typescript
- vite

Log in or sign up for Devpost to join the conversation.