Inspiration
Hundreds of insurance advisory calls happen every day — yet evaluating whether agents truly follow the script, disclose the right information, and speak authentically is still done manually, inconsistently, and slowly.
We asked: what if AI could read the rulebook and grade every call automatically?
That became VoiceIQ.
What it does
Two things, end to end:
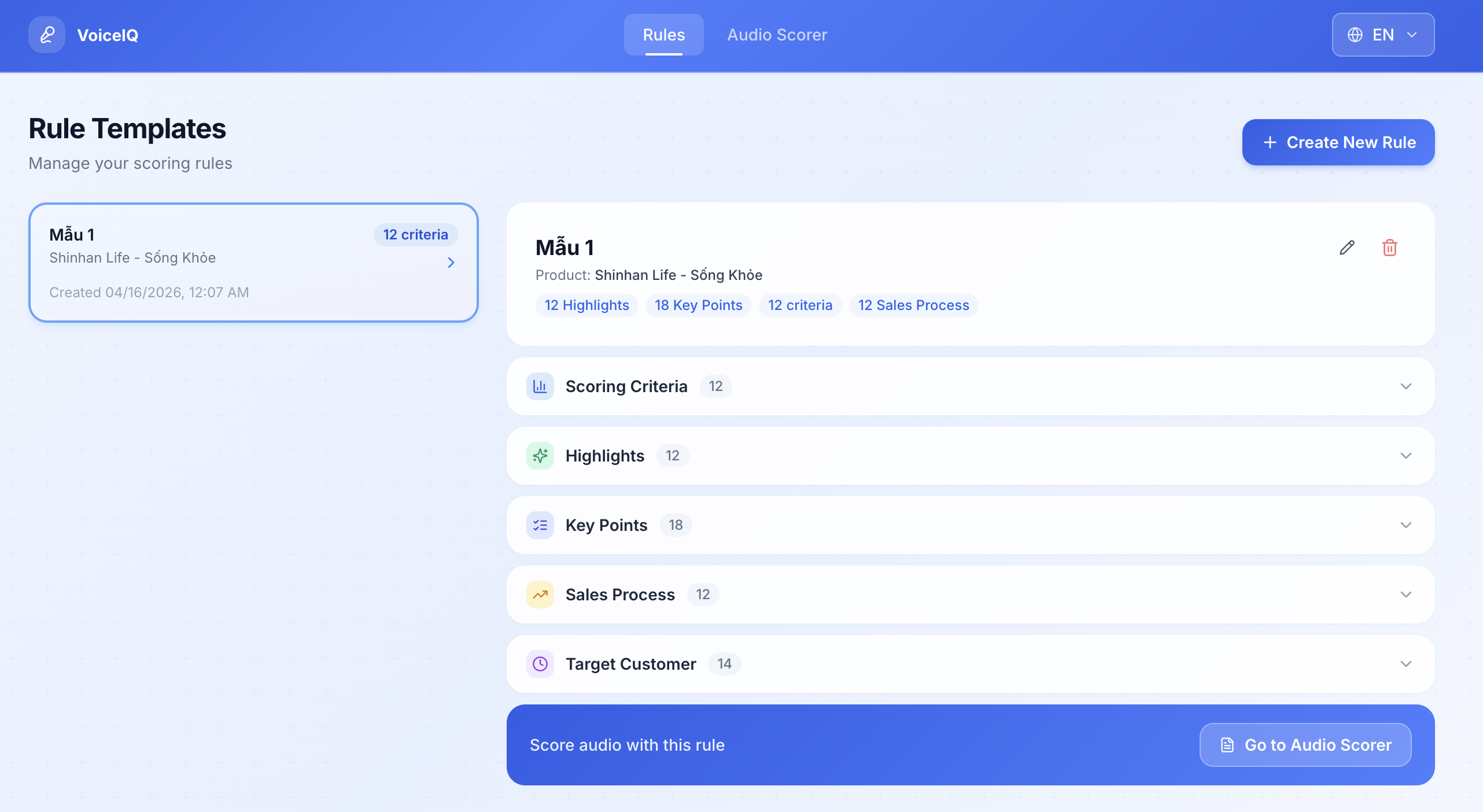
Turn documents into a scoring rulebook. Upload any insurance product documentation and Qwen extracts the key facts, synthesizes a structured Sales Rule — product highlights, target customer profile, consultation steps, and measurable pass/fail criteria — ready for the team to review and save.
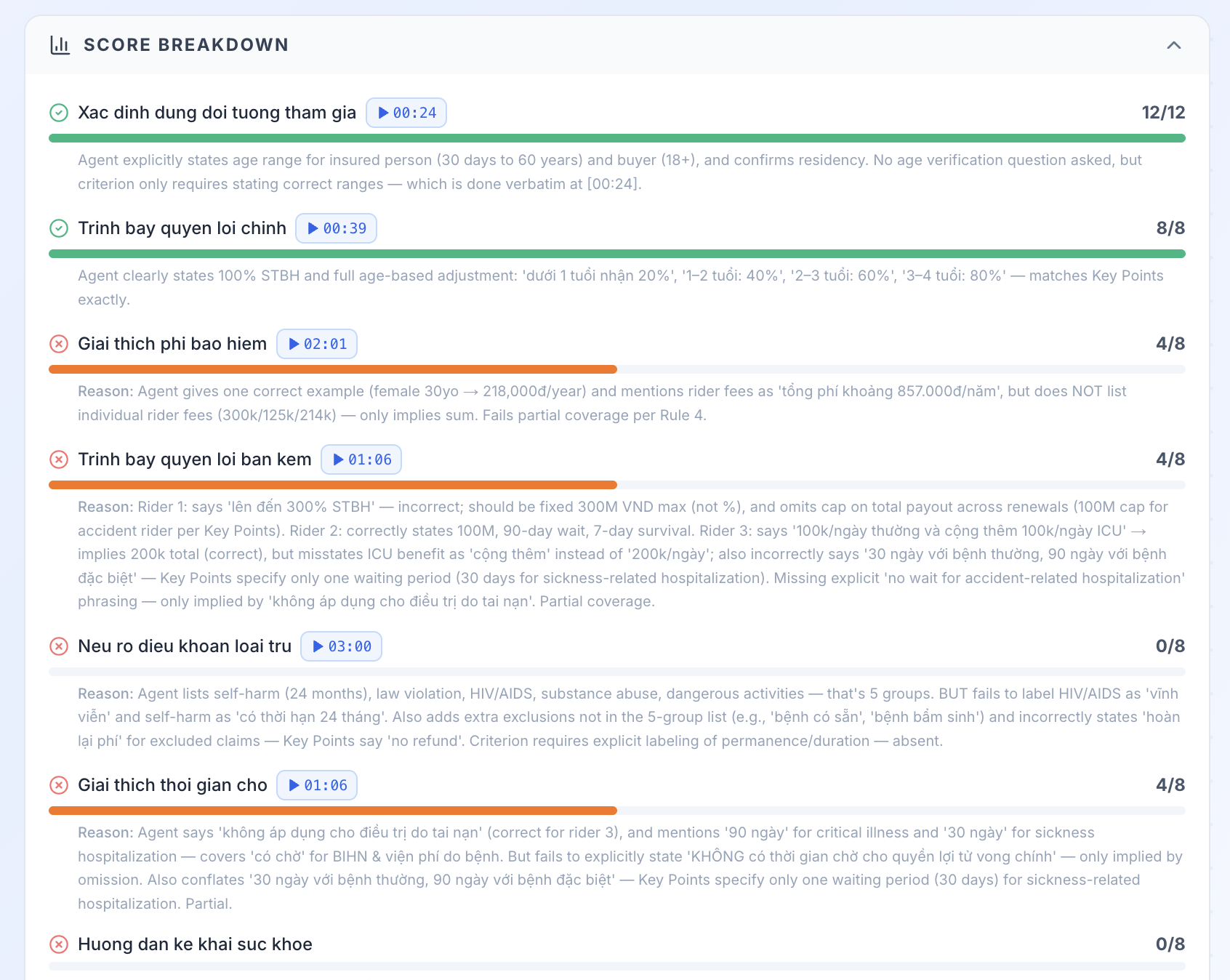
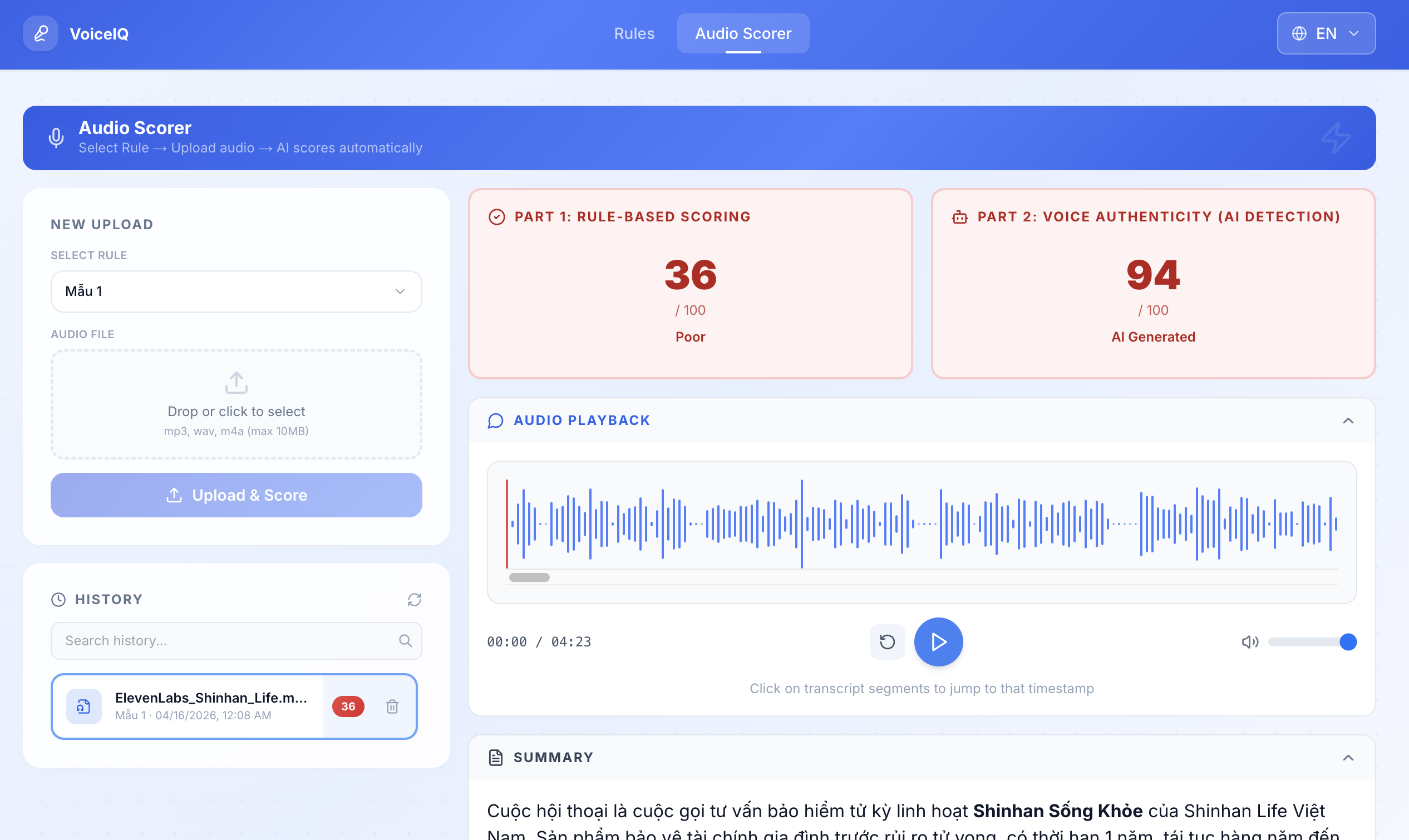
Score any recorded call against that rulebook. Upload audio, and VoiceIQ returns a full report: what the agent said, who said what, how well the consultation matched the rule, and whether the voice itself was real or AI-generated.
How we built it
Everything runs on Qwen models via DashScope. Different models handle different stages — document understanding, audio transcription, speaker role identification, content evaluation, and linguistic analysis — working together as a single pipeline.
For voice authenticity, we built a multi-signal detection engine that combines acoustic analysis with Qwen-powered linguistic fingerprinting, catching TTS-generated voices without any training data.
Challenges we ran into
- Making Qwen score strictly and consistently — not generously — required deep prompt design and server-side guardrails the model cannot override
- Separating who said what from a flat transcript, across any number of speakers in any order, using only language understanding
- Detecting AI voices with no labelled dataset — derived analytically from two independent signal types, fused together
Accomplishments that we're proud of
- A pipeline that goes from raw audio to a scored, explainable report with no human in the loop
- Scores that are mathematically tamper-proof regardless of what the model outputs
- An AI voice detector built with zero training data
- Qwen returns verdicts in both Vietnamese and English in a single response
What we learned
Qwen is genuinely strong at Vietnamese speech nuance and domain-specific insurance terminology. Getting it to be a strict grader rather than a generous one turned out to be the hardest prompt engineering challenge of the project.
What's next for VoiceIQ
Real-time scoring on live calls, a manager dashboard for team-wide trends, and auto-generated post-call coaching — so every agent improves before the next conversation.
Built With
- nestjs
- node.js
- python
- qwen
- typescript

Log in or sign up for Devpost to join the conversation.