Inspiration Most text-to-speech and speech-to-text tools today require cloud accounts, send your data to third-party servers, and lock you into subscription plans. I wanted to build something different: a tool that runs entirely on your own hardware, processes nothing in the cloud, and respects your privacy by design.
What it does VoiceForge is a full-stack web app with two core features:
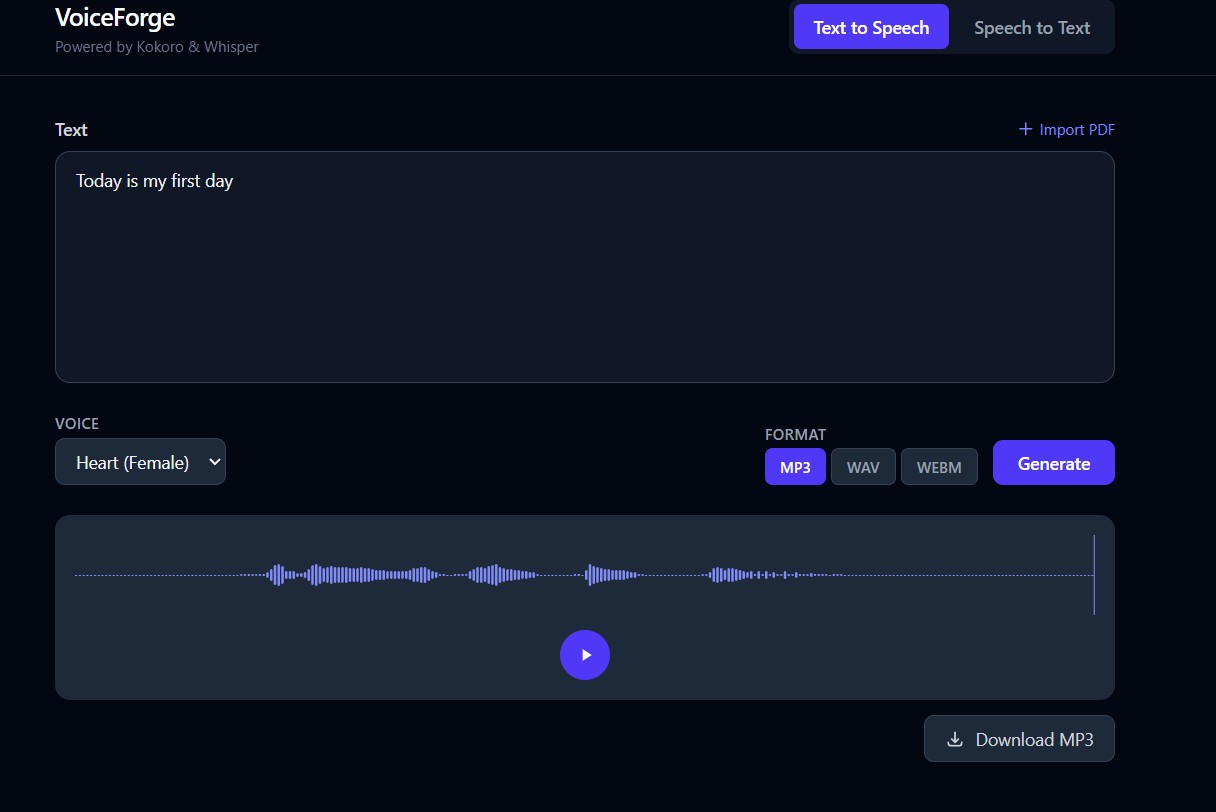
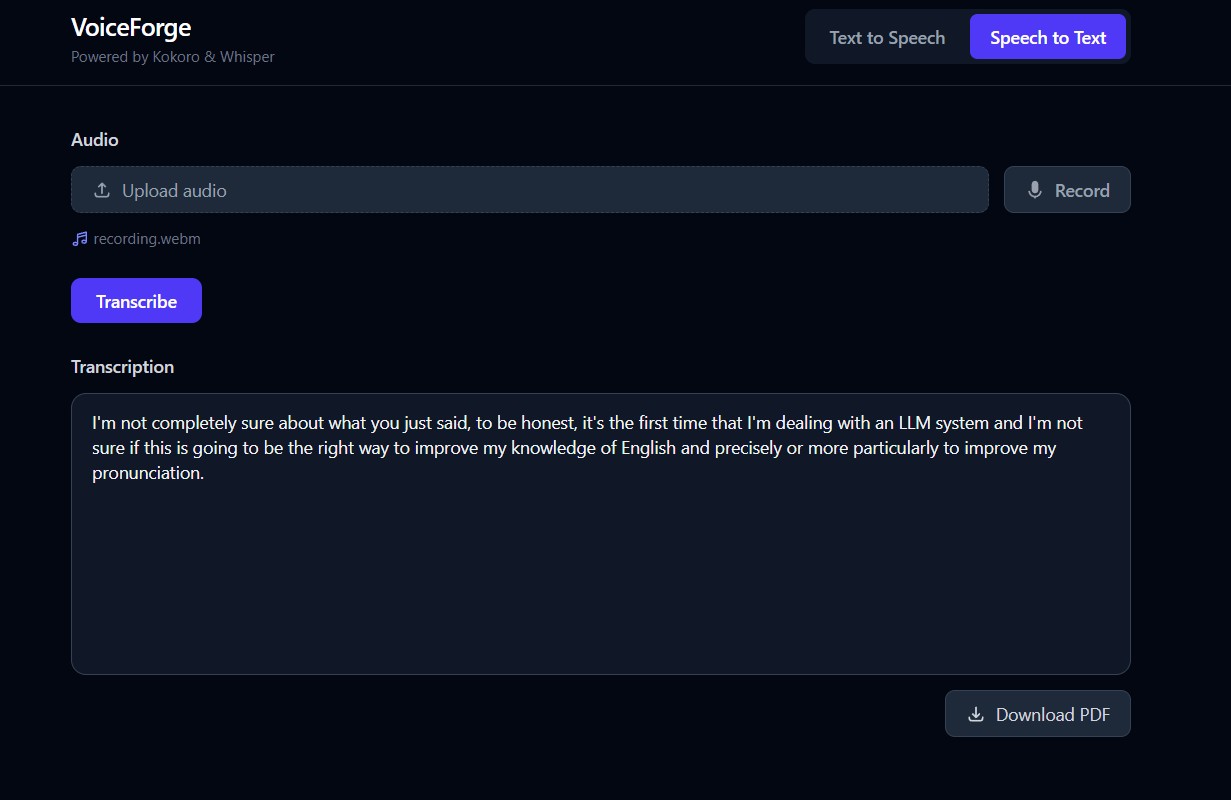
Text-to-Speech — Paste text or import a PDF, choose one of 4 voices and an output format (MP3, WAV, or WebM), and generate audio instantly. The result plays in an interactive waveform player and can be downloaded. Speech-to-Text — Upload an audio file or record directly from your microphone, and get a text transcription in seconds. The transcription can be exported as a formatted PDF. No login. No data stored. No external API calls. Everything runs locally.
How I built it Backend: FastAPI (Python) serving two endpoints — /api/tts and /api/stt — backed by Kokoro for TTS and faster-whisper for STT. Both models run as in-memory singletons loaded at startup. Frontend: Next.js 16 with React 19 and Tailwind CSS. WaveSurfer.js powers the waveform player, PDF.js handles client-side PDF extraction, and jsPDF generates downloadable transcription PDFs. Architecture: Fully spec-driven — I wrote a PRD, technical spec, and build checklist before writing a single line of code. Challenges SSR conflicts with browser APIs — PDF.js and WaveSurfer.js both rely on DOM APIs unavailable in Node.js. I solved this with dynamic imports and ssr: false to ensure they only run client-side. Model startup time — Kokoro and Whisper load sequentially at startup. FastAPI's lifespan context manager gates all endpoints until both models are ready, preventing partial-ready states. Audio format conversion — Kokoro outputs raw WAV; converting to MP3 and WebM required pydub + ffmpeg with libopus support, which needed careful verification per deployment environment. What I learned How to structure a spec-driven hackathon workflow from learner profile → scope → PRD → technical spec → checklist → build How to integrate open-source AI models (Kokoro, Whisper) into a production-ready FastAPI service The nuances of SSR in Next.js 16 when mixing server and browser-only dependencies What's next Deploy to Oracle Cloud for public access Add streaming TTS for faster time-to-first-audio Support additional languages via Whisper's multilingual mode

Log in or sign up for Devpost to join the conversation.