-
-

Cover Page
-
The Problem
-

The Idea
-
How It Works
-

Document Types & Voice Adaptation
-

Expressive vs Standard Mode
-
Observability (Datadog Differentiator)
-
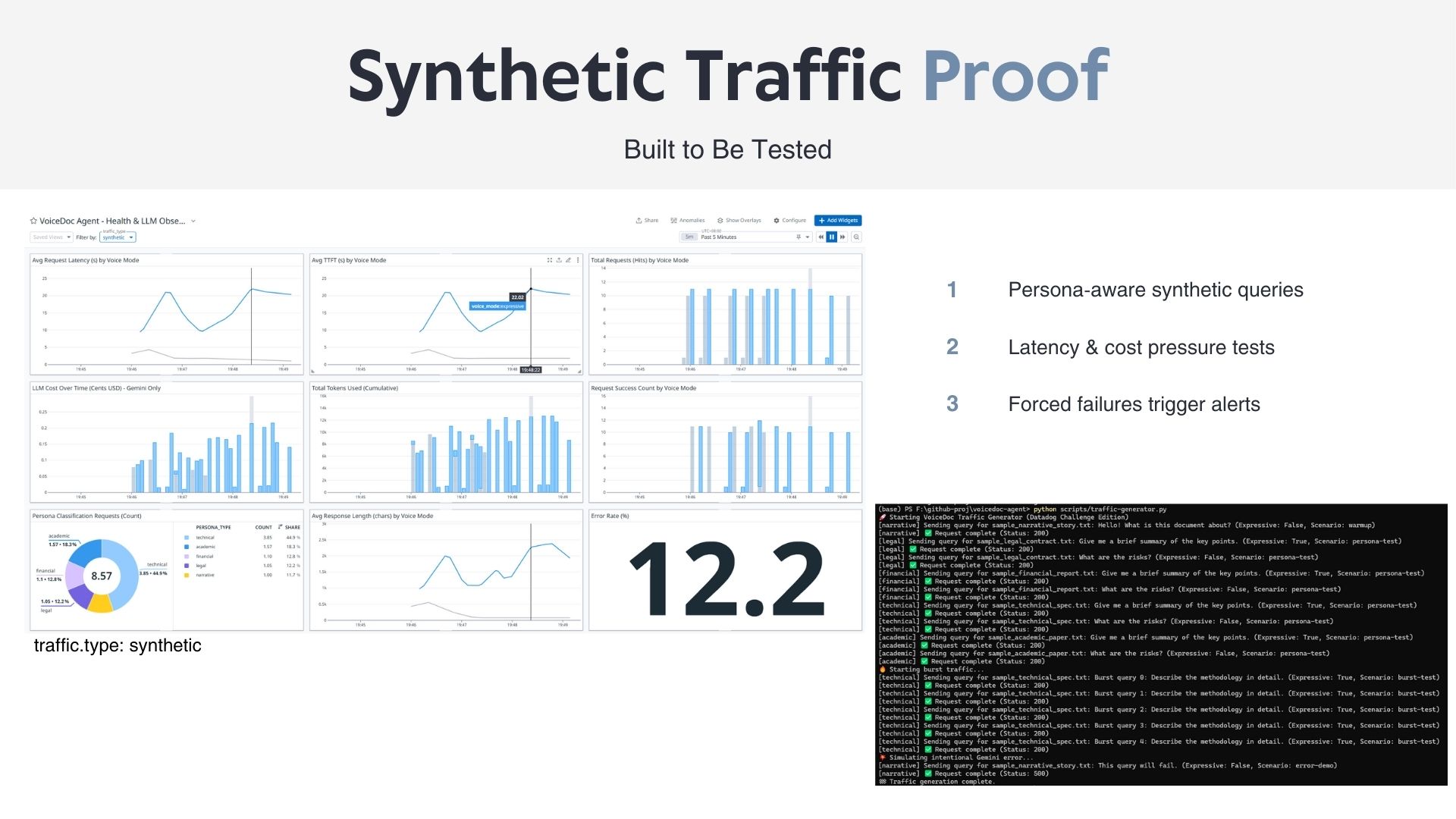
Synthetic Traffic Proof
-
Why It Matters (Hackathon Tie-In)
-

Closing / CTA





Inspiration
Most “chat with your documents” tools treat voice as a thin layer on top of text. From prior experiments with voice interfaces, I noticed that how information is spoken — tone, pacing, and expressiveness — directly affects trust, clarity, and perceived intelligence.
This project was inspired by a simple question: what if voice were treated as a first-class AI signal, not just an output format?
The AI Partner Catalyst: Accelerate Innovation hackathon provided the perfect opportunity to explore this idea using the Google Cloud partner ecosystem.
What it does
VoiceDoc Agent transforms static text documents into spoken, conversational experiences. Users can upload a text-based document and explore it entirely through voice — asking questions, requesting summaries, or diving into specific sections without typing.
The system dynamically adapts:
- Reasoning style based on document type (technical, legal, narrative)
- Voice behavior based on interaction mode (fast vs expressive)
- Observability signals based on user experience impact
The result is a voice-first document intelligence experience rather than a traditional text-based RAG app.
How we built it
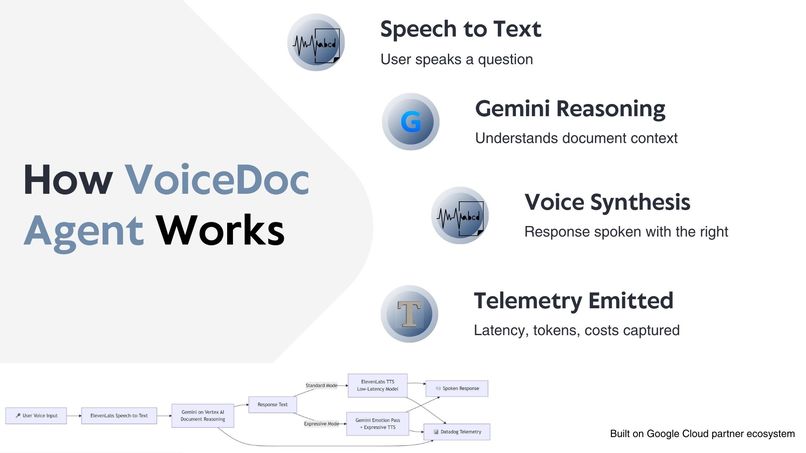
VoiceDoc Agent is built on the Google Cloud partner ecosystem:
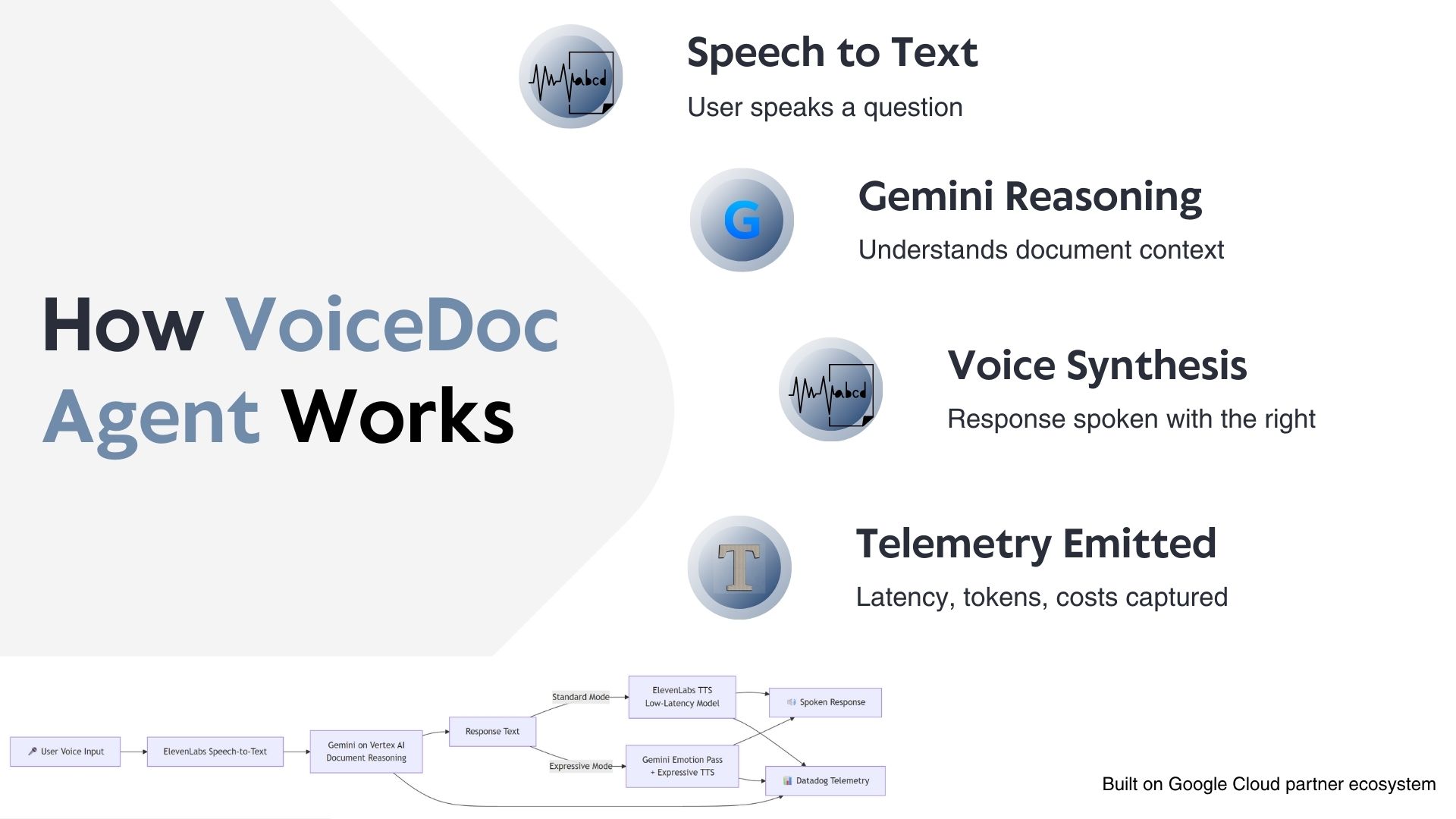
- Gemini on Vertex AI handles document classification, retrieval-augmented reasoning, and conversational responses.
- Firestore stores document chunks, embeddings, and session metadata.
- ElevenLabs Text-to-Speech converts AI responses into natural speech using different voice models optimized for either low latency or expressive delivery.
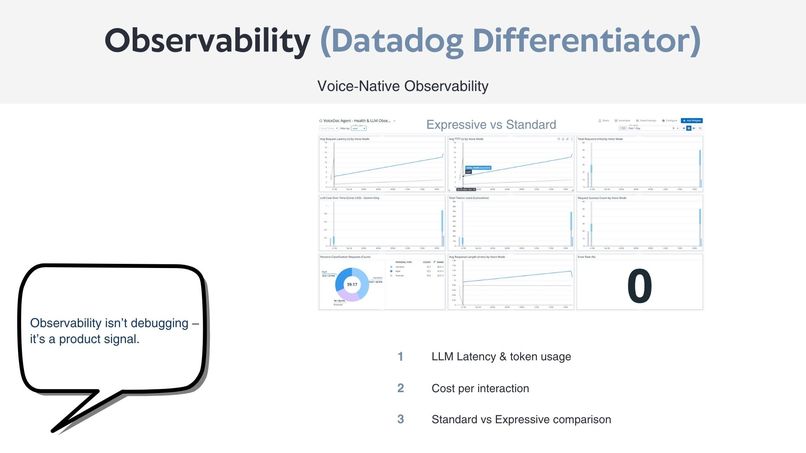
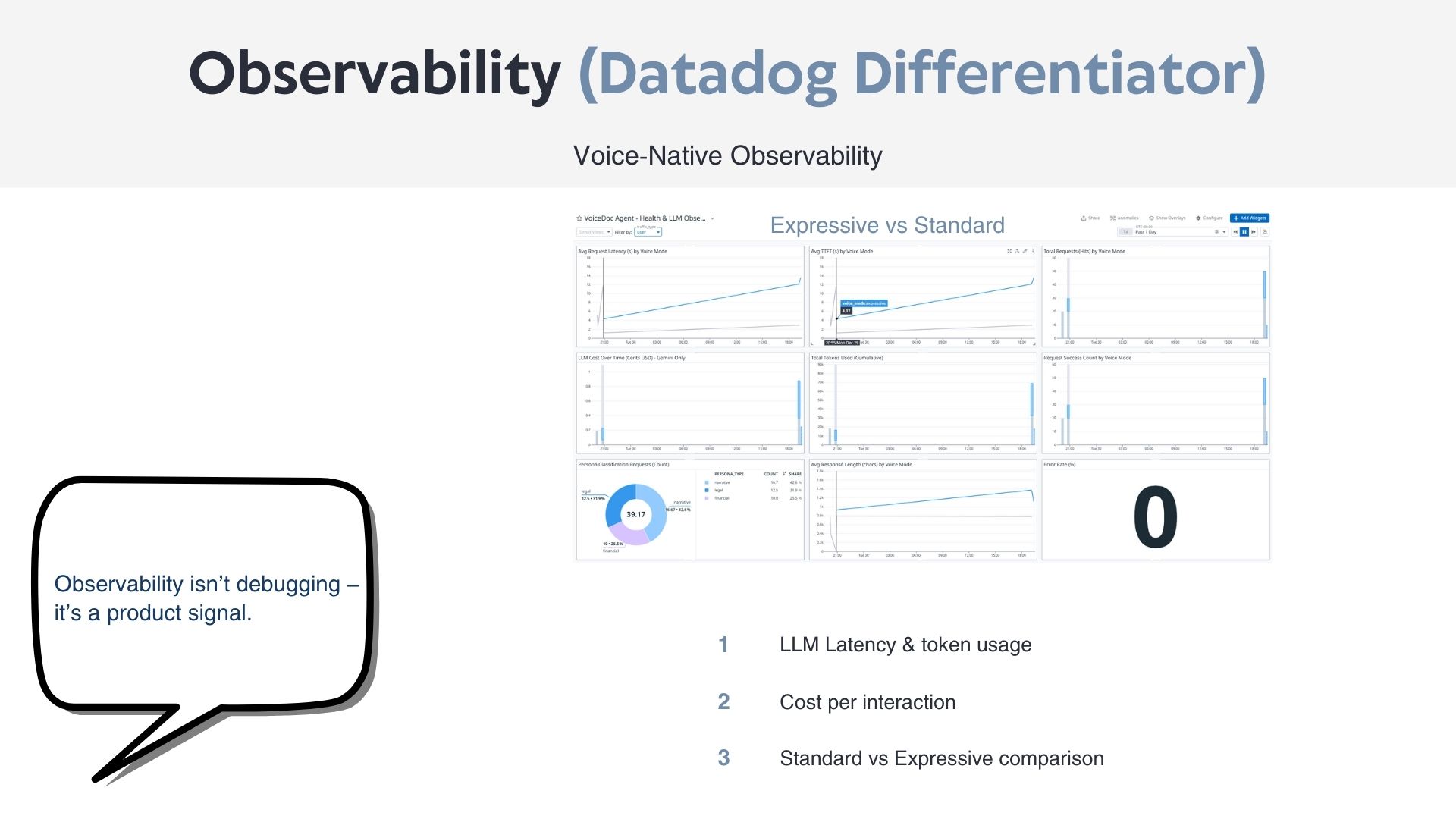
- Datadog provides end-to-end LLM observability, tracking latency, token usage, estimated cost, and error rates.
The system supports two voice modes:
- Standard Mode for fast, low-latency responses.
- Expressive Mode using a two-pass pipeline where Gemini first reasons, then injects emotion tags before speech synthesis.
All AI interactions emit structured telemetry, allowing direct correlation between voice behavior, infrastructure performance, and user experience.
Challenges we ran into
- Balancing expressiveness and latency: expressive speech improves user experience but introduces measurable latency and cost tradeoffs.
- Voice-first UX design: designing interactions where speech feels natural and intentional, not a novelty layered onto text.
- LLM observability modeling: deciding which metrics truly reflect user experience rather than just raw model performance.
- Accurate partner usage: ensuring the project clearly reflects actual integrations (ElevenLabs TTS models, not agent frameworks) while still demonstrating advanced voice behavior.
Accomplishments that we're proud of
- Treating voice as a measurable system component, not just an interface.
- Designing dual-mode voice pipelines with observable performance tradeoffs.
- Building a production-style observability setup with dashboards, monitors, and runbooks.
- Demonstrating how multiple Google Cloud partners can be composed into a cohesive, voice-first AI system.
What we learned
- Voice directly impacts infrastructure behavior — latency, token usage, and cost all change based on how something is spoken.
- Observability is a product feature, not just a debugging tool.
- Partner ecosystems accelerate innovation by enabling rapid composition of specialized capabilities.
- Designing for voice-first systems requires different assumptions than designing for chat-based interfaces.
What's next for VoiceDoc Agent – Voice-Native Document Intelligence
- Add robust PDF ingestion and richer document preprocessing.
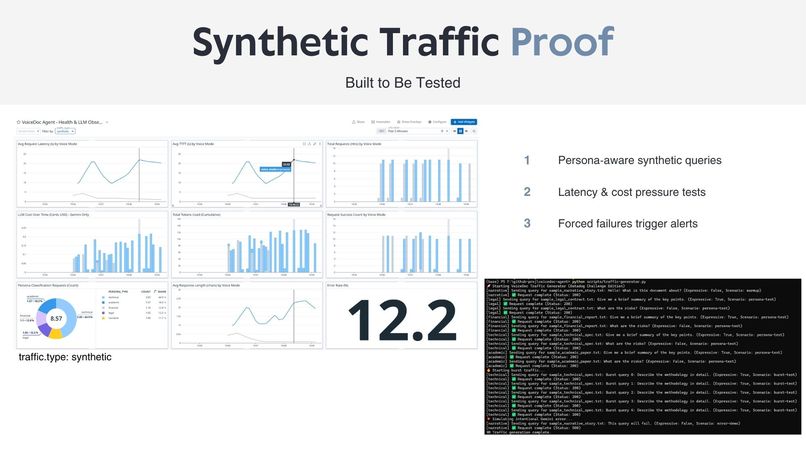
- Expand persona-aware voice behavior for different professional domains.
- Introduce multi-document comparison and spoken summaries.
- Use observability signals to dynamically adapt voice behavior based on real-time performance and user context.
Built With
- cloudrun
- datadog
- docker
- dockerhub
- elevenlabs
- firestore
- gemini
- github
- javascript
- next.js
- node.js
- python
- rag
- rum
- typescript
- vertexai

Log in or sign up for Devpost to join the conversation.