-
-

Website Landing Page
-
Website Page 2
-
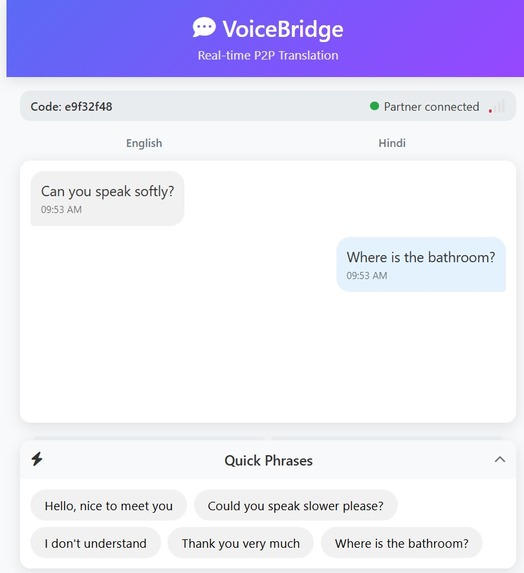
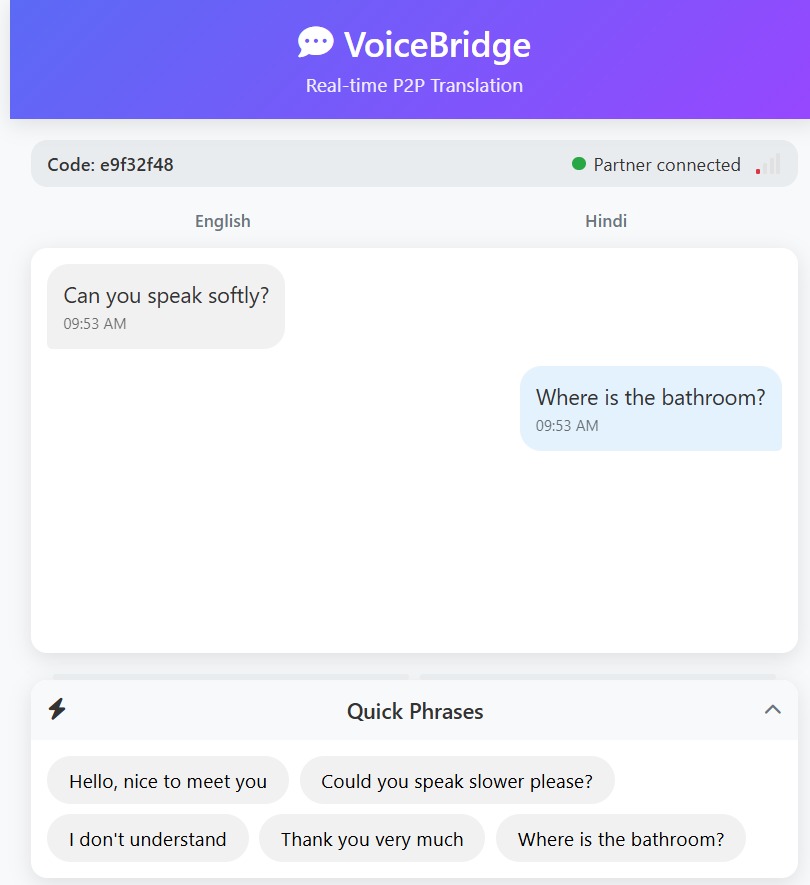
Application(Common Room) Interface
-
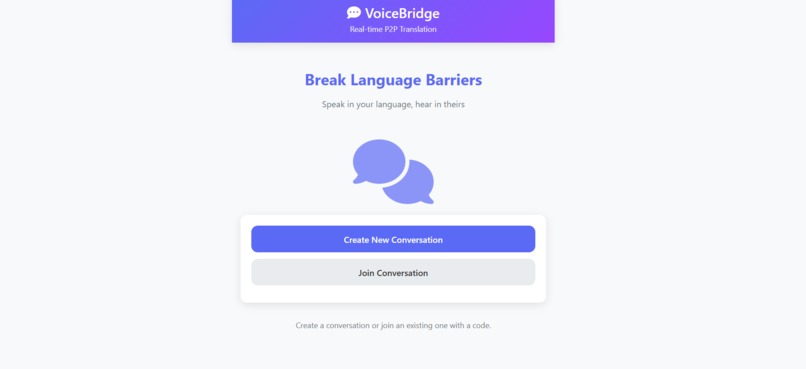
Application Landing Page

Inspiration
As international students, we've experienced firsthand the frustration of language barriers on campus. Whether volunteering at the campus pantry unable to assist Spanish-speaking visitors, or struggling to communicate with maintenance workers in our apartments, these moments of disconnection are more than inconveniences—they're missed opportunities for meaningful human interaction. Conventional translation tools often fall short, providing inaccurate or contextually inappropriate translations that further complicate communication. VoiceBridge was born from these challenges, designed to provide international students and the broader university community with a real-time translation solution that fosters inclusivity and breaks down the walls that language differences can create.
What it does
Our solution enables real-time conversation between people speaking different languages by leveraging cutting-edge AI models for speech recognition, translation, and speech synthesis.
How we built it
We developed VoiceBridge using a modular architecture with three main AI components working in sequence. On the backend, we used Python with Flask and Socket.IO to create a real-time communication server that facilitates peer-to-peer connections. For speech recognition, we implemented OpenAI's Whisper model, while Meta's NLLB-200 handles the machine translation between languages. Speech synthesis is powered by Meta's MMS-TTS model to generate natural-sounding output.
The frontend was built with HTML, CSS, and JavaScript, featuring Socket.IO for WebSocket connections and a responsive design. We created both a diagnostic tool (using Gradio) for testing individual components and a user-friendly interface for the translation experience. The audio processing pipeline leverages the SoundDevice library for real-time audio capture and playback, with NumPy for signal processing. All components are carefully optimized to minimize latency while maintaining translation quality.
Challenges we ran into
1) We encountered significant challenges with the Text-to-Speech (TTS) component, as evidenced by the extensive diagnostic code and error handling in the TTS modules. The MMS-TTS model often produced silent or low-quality audio, requiring us to implement multiple fallback approaches and audio amplification techniques. Integrating the three AI models (Whisper, NLLB-200, and MMS-TTS) into a cohesive, low-latency pipeline proved technically demanding, especially when maintaining context between speech segments.
2) We also were limited in compute power, thus utilizing threading technique to handle the tasks better was also one of the challenges.
3) Building a user interface than can give a seamless user experience in less amount of time gave was also a challenging task.
Accomplishments that we're proud of
1) We successfully built a fully functioning end-to-end speech translation system that processes audio in real-time with minimal latency. Our implementation seamlessly integrates three state-of-the-art AI models (Whisper, NLLB-200, and MMS-TTS) into a coherent pipeline that maintains conversation context.
We're particularly proud of our streaming architecture that processes speech incrementally, allowing for natural conversation flow rather than requiring users to pause after each sentence.
2) Creating a seamless UI experience in less amount of time is also an achievement for our team.
What we learned
1) We gained deep expertise in speech processing pipelines and the complexities of integrating multiple AI models into a cohesive system. Working with cutting-edge models like Whisper, NLLB-200, and MMS-TTS gave us practical insight into the strengths and limitations of current language AI technologies. We learned the importance of robust error handling and fallback mechanisms when dealing with AI-based systems, especially for audio processing in real-world conditions
2) We developed skills in WebSocket programming for real-time communication and gained experience with language mapping between different standardization systems. Perhaps most importantly, we learned how to balance technical complexity with user experience design to create a tool that addresses a real human need for cross-language communication.
What's next for VoiceBridge
We plan to increase our project's capabilities by using top notch AI models with higher parameters along with more powerful compute hardware, resulting into a portable device that can be used anytime and anywhere to communicate across languages.
Built With
- aos:animation
- font-awesome
- gradio-ai-models:-whisper-(asr)
- html/css-frameworks:-flask
- javascript
- languages:-python
- mms-tts-(speech-synthesis)-audio-processing:-sounddevice
- nllb-200-(translation)
- numpy-additional-libraries:-transformers
- pytorch
- socket.io
- wave-frontend-technologies:-bootstrap


Log in or sign up for Devpost to join the conversation.