-
-
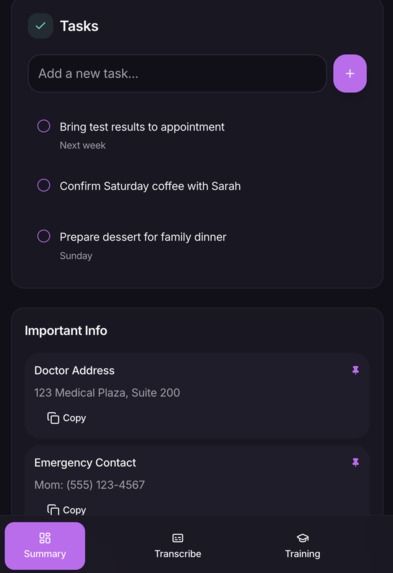
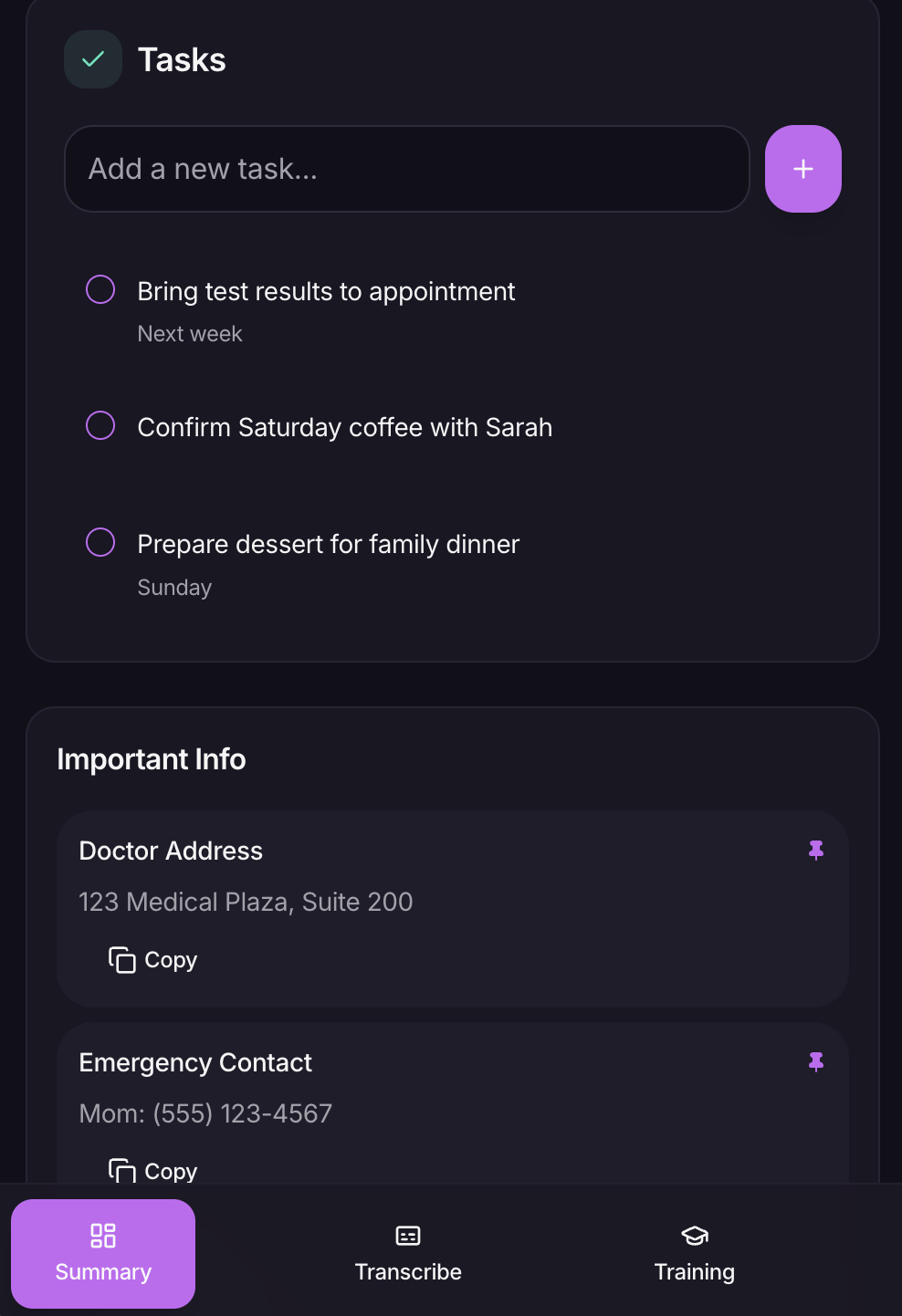
Summary Page 2
-
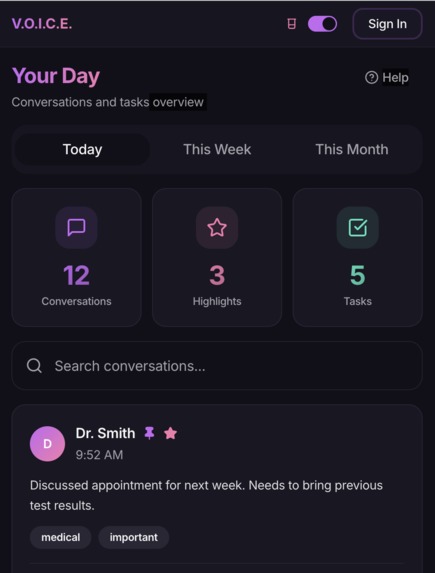
Summary Page 1
-
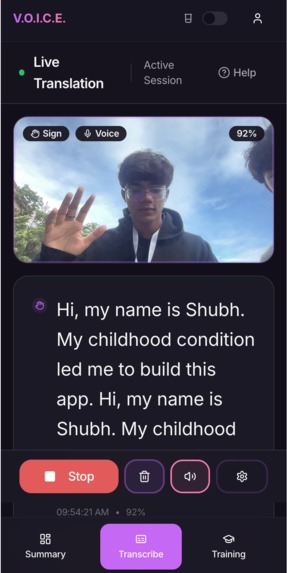
Inspiration
Shubh was diagnosed with chronic laryngitis from birth. It’s not exactly the same as being deaf, but arguably worse. The larynx (voice box) is consistently inflamed, leading to an inability to speak that left Shubh mute for the first 12 years of his life. This is when he learned ASL. In a world where people communicate mainly through sound, Shubh and others of the deaf and mute community were confined not by their inability to communicate, but by others’ ability to understand them.
What it does
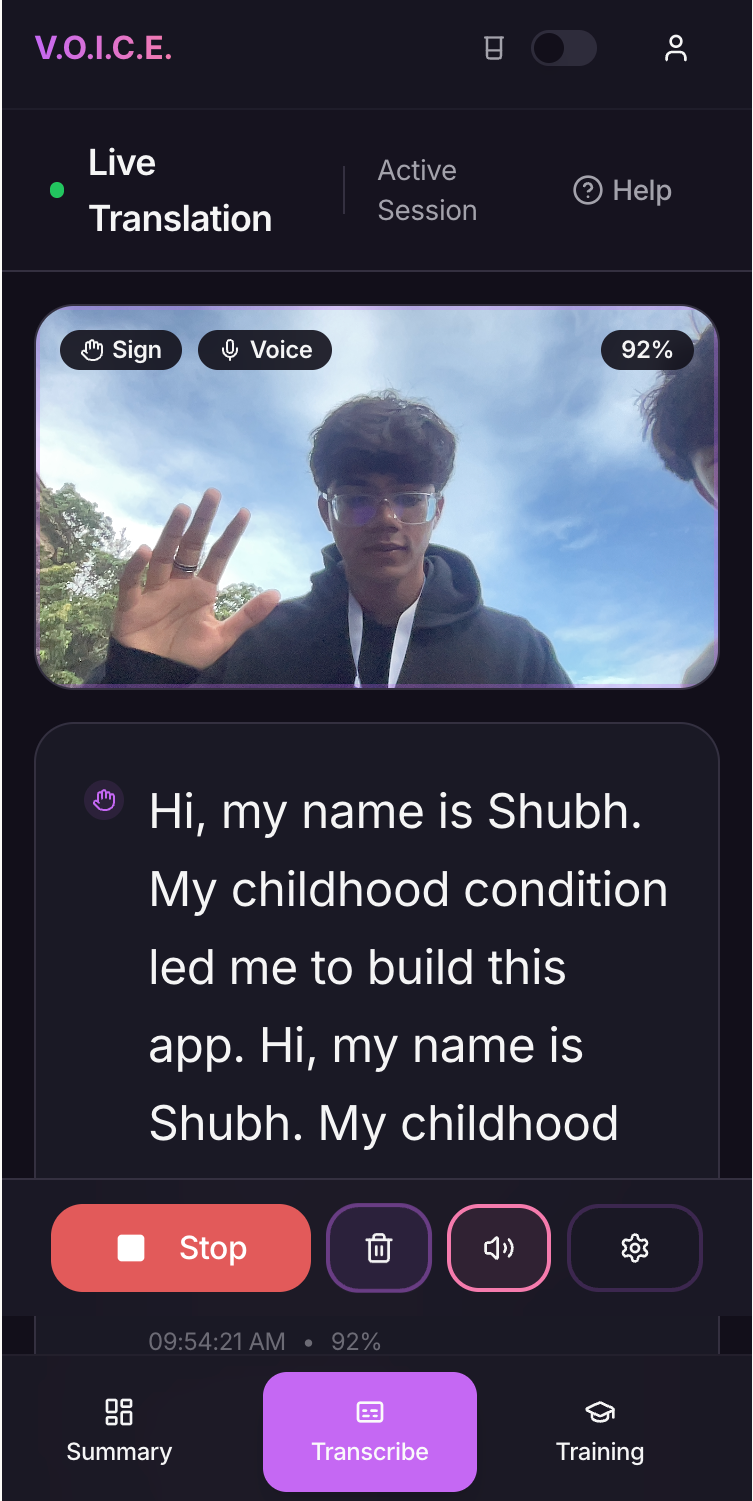
VoiceAI’s flagship feature is real time sign language translation, transcription, and synthesis, making conversations between the hearing and the deaf and mute seamless. The app works by placing your phone in a clear lanyard that hangs around your neck. While the user is speaking, the phone screen will be facing the other person. The user’s hand movements will be captured by the front camera, transcribed onto the screen, and synthesized into audio. To obtain that audio, users are prompted to train their very own voice model. They simply have to repeat several words that consist of low frequency consonant sounds, the easiest syllables to pronounce for the deaf. The model then creates a persona for the user, essentially, giving them the voice they never had. When the other person is speaking, the user can simply turn the phone around towards them to read the live audio transcription. We also include daily, weekly, and monthly summaries of conversations and their highlights, attacking the mental and psychological stress of being deaf in a hearing world that often results in decayed memories. This feature also proves useful for the hearing community’s everyday lives as well.
How we built it
The frontend is built with React and Typescript. We used Radix UI and Shadcn/UI, as well as Tailwind CSS for a modern look (we emphasized visual appeal a lot since deaf people will be more sensitive to visual cues). For the backend and database, we used Supabase and PostgreSQL to store accounts, conversations, highlights, and to-dos.
Our key features include the MediaPipe Hands API in order to detect hand movements and gestures. This is the core functionality of VoiceAI. It allows us to go from using a multi-modal model like Gemini or Llama (essentially making us a GPT wrapper that is slow, inefficient, and clumsy) to training our own lightweight model that makes sign language transcription and synthesis real time and seamless. We trained the model on data collected at CalHacks with by other hackers (yes, we spent hours approaching strangers to record them doing ASL). The data was also cleaned and labeled manually by us. We used a Random Forest classification architecture due to time constraints.
We use WebRTC to access the system’s camera and microphone. Finally, we use Fish Audio to train and clone voices. Their training requires minimal data, so we were able to pick and choose what words we wanted users to say to make it as easy as possible.
Challenges we ran into
Multi-modal applications had way too high latency and made real-time conversations impossible. We started off using Gemini 2.5 flash pro, which was working well but slowly. What made us switch off of it was we (embarrassingly) ran out of credits. So we investigated using Groq and Llama 4 Scout, only to realize multi modal models in general were simply unfeasible. So we opted to train our own model. The challenges that come with our own model is collecting the data. Currently, our methods of collecting data consist of walking around the Palace of Fine Arts asking random people who don’t look they’re busy and having them do sign language for us. We are on the lookout for a clean and usable dataset to train a new model on. Voice synthesis. We originally tried to use VAPI API for voice synthesis then realized they were completely not what we needed. We needed to create voice clones with limited amount of data. After searching through the CalHacks sponsors, we found Fish Audio, which was exactly what we needed.
Accomplishments that we're proud of
Our greatest crowning achievement throughout this entire process was each picking up a bit of sign language. We all have someone in our lives that is deeply affected by hearing loss, and even being able to introduce ourselves in sign language has been so much fun to learn. We’re proud of our ability to iterate and pivot so quickly in such a short amount of time. We went through so many ideas, from robot fighting simulations to a full-on physical CRM, we were super ambitious going into the hackathon. However, we were able to try so many different things and eventually lock in on one particular idea.
What we learned
The biggest thing we learned was that 36 hours is not as much time as you think. We came into the hackathon with grandiose visions. We would sit and think, “we have 10+ hours, we have plenty of time.” Turns out it’s extremely difficult to stay focused for more than 3 hours straight, and we found ourselves having to narrow down our ideas more and more. I think we were able to adapt quickly though, and we were able to execute on our final design.
What's next for VoiceAI
Because the deaf and mute community is so prevalent in each of our lives, we want to bring it back to our communities, receive feedback, and continue iterating on it. We’ve seen firsthand the immense demand and potential to succeed this product has, and we’re going to ensure it reaches as many people as possible. I’m a firm believer in the Invisible Hand of capitalism. The most successful businesses are the ones that benefit the most people, that do the most good for the world. The deaf and mute community is one of the most underserved disabled groups in the world, and we’re finally leveling the playing field for them.
Built With
- fish-audio-api
- mediapipe-hands-api
- postgresql
- react
- supabase
- supabase-+-postgresql
- typescript
- webrtc



Log in or sign up for Devpost to join the conversation.