-
-
Users can view their upload history
-
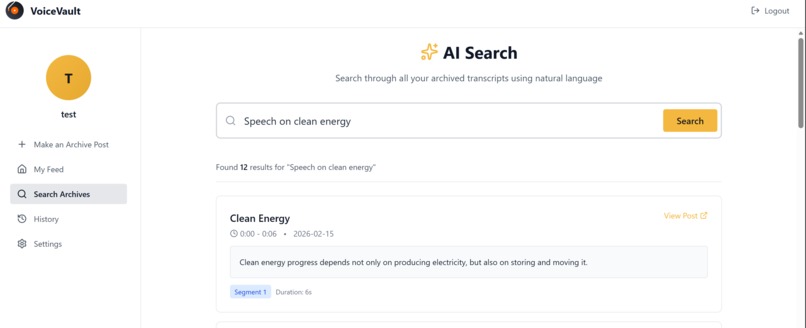
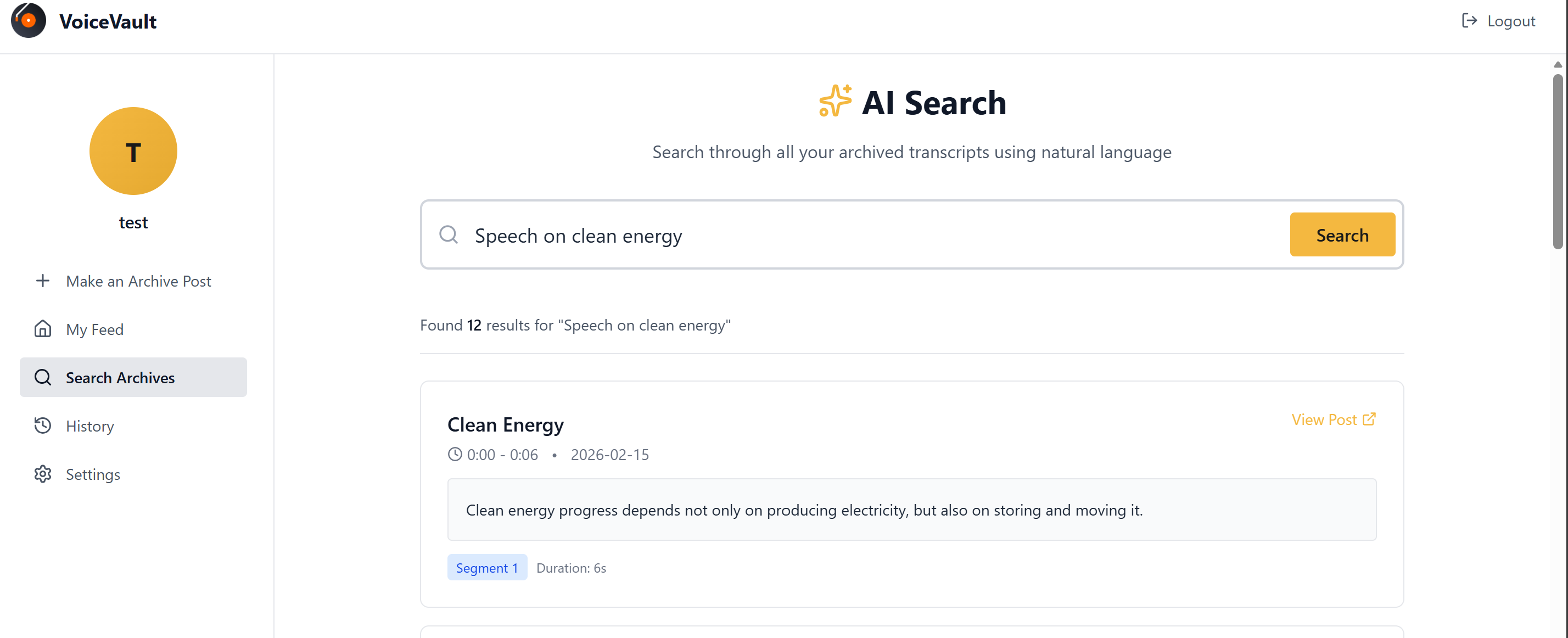
users can search for various audios through their search prompts
-
login/register page
-
user profile settings
-
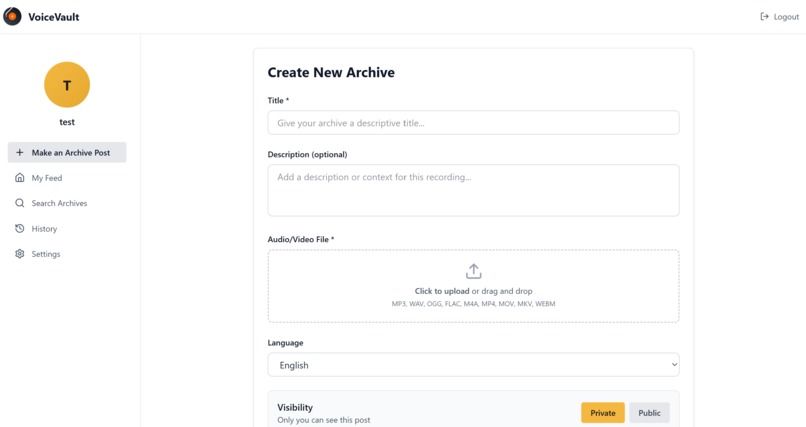
users can upload their audio files here
-
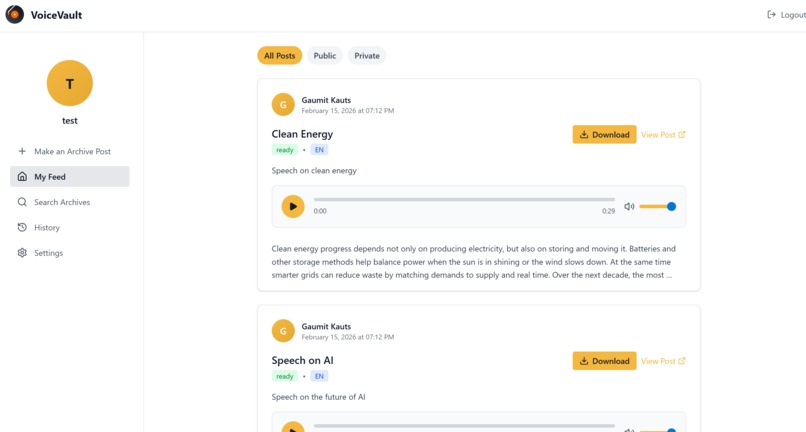
user feed for checking and accessing public audios posted by various users
Inspiration
Every family has a voice they wish they could hear again.
A grandparent's migration story, a parent's advice, a friend's laughter after midnight, a survivor's testimony, a local elder describing a neighborhood that no longer exists.
These stories are spoken, not typed. And because voice is messy, unstructured, and hard to search, it gets lost in phone galleries, cloud folders, and forgotten drives.
VoiceVault was born from one belief:
If we can preserve voice like we preserve photographs, we can preserve identity, memory, and history itself.
What it does
VoiceVault is a story-preservation platform that turns raw recordings into structured, reusable archives.
- Upload audio/video (private or public)
- Transcribe speech into readable text
- Convert transcripts into RAG-ready chunks for semantic retrieval
- Keep the original recording playable anytime
- Organize user history with edit/delete controls
- Export a complete Archive Bundle ZIP (audio + transcript + metadata + timestamps)
Preserving data
- For us preserving data does not mean to store it in a database, it means letting the user access through an archive bundle where the user can get the original audio along with its information.
- This feature promotes preservation and accessibility of past audio data for the upcoming generation.
- It does not just store files. It preserves context.
Audio as a platform
- This is not just an audio storing platform but a platform where users can interact with each other's data, access it and share it with others.
- Data is the component which increases if its shared amongst others, so our application supports this principle.
How we built it
We designed VoiceVault as a full archival pipeline:
- Frontend: React interface for login, upload, history, playback, and search
- Backend: Flask API orchestrating upload, transcription, metadata, and retrieval
- Storage + DB: Supabase for persistent storage and relational data
- Transcription: Whisper-based speech-to-text
- RAG layer: Transcript chunking and indexing for retrieval workflows
Built With
- flask
- javascript
- openai
- openai-api
- python
- rag
- react
- rest

Log in or sign up for Devpost to join the conversation.