-
-
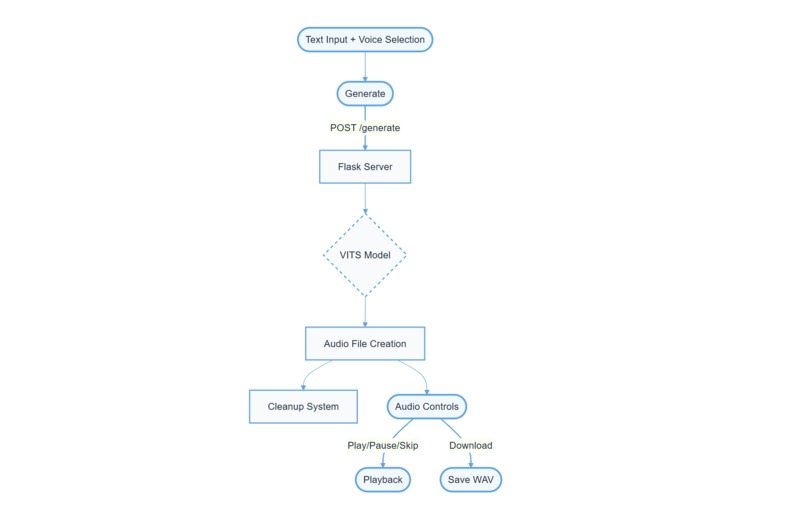
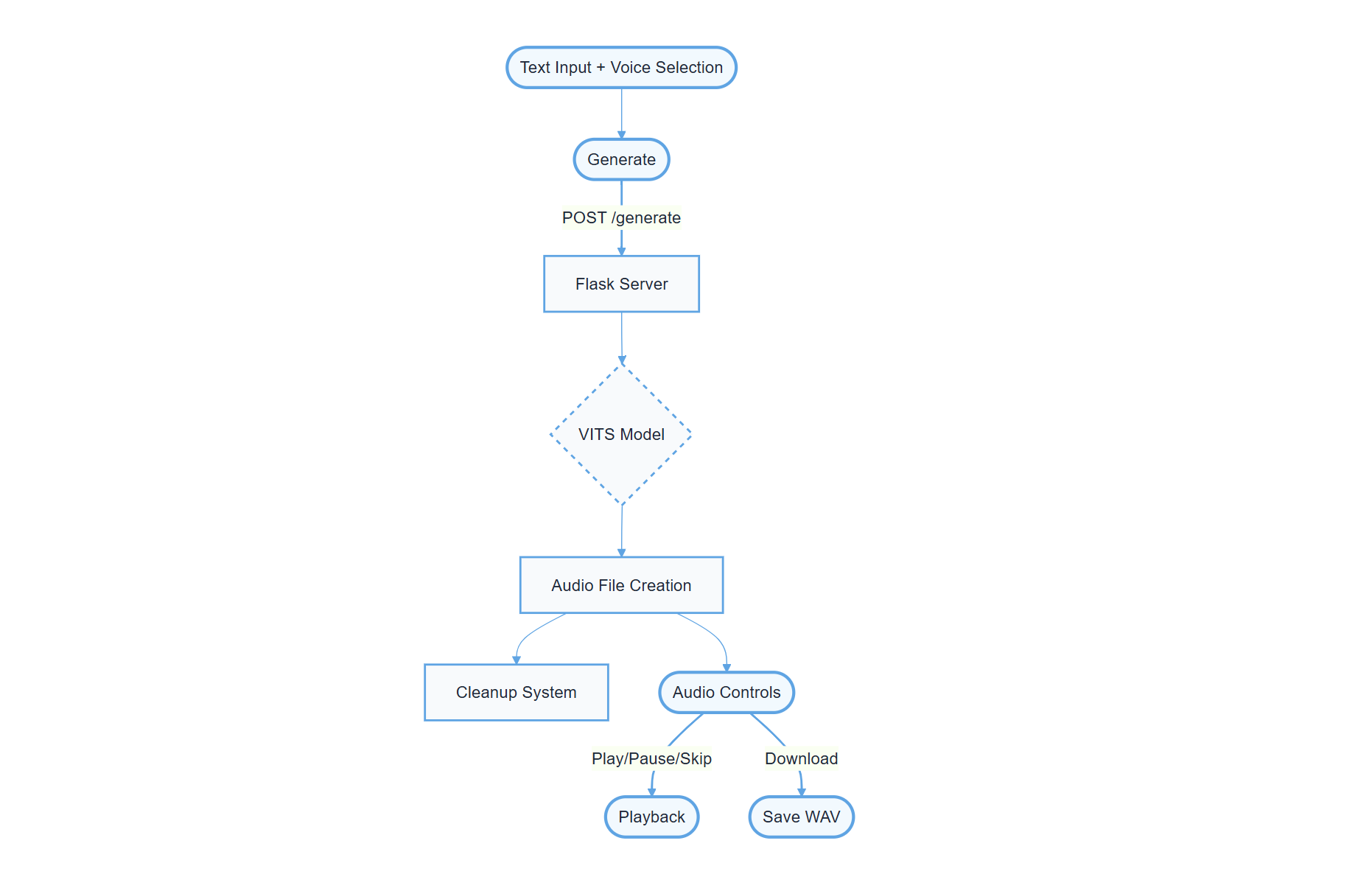
Technical Architecture
Inspiration: Text-to-speech technology often faces challenges with complexity and accessibility. After seeing how voice synthesis could help content creators and people with speech impairments, we were inspired to create a simpler, more intuitive solution that anyone could use.
What it does: Voice Studio is an AI voice synthesis system that converts text to speech with three distinct voice profiles: Young Male, Young Woman, and Senior Male. It features a clean, single-view interface with intuitive controls for audio playback and a straightforward text input system.
How we built it: We developed Voice Studio using:
Flask backend for RESTful API and file management VITS model for high-quality voice synthesis UUID-based file tracking system Automated resource cleanup Comprehensive error handling Memory-optimized audio processing
Challenges we ran into:
Implementing stable voice transformations for different personalities Optimizing memory usage for audio processing Managing audio file cleanup efficiently Balancing quality with processing speed Ensuring consistent audio delivery
Accomplishments that we're proud of:
Created three distinct, natural-sounding voices Built a clean, intuitive user interface Implemented efficient audio file management Developed robust error handling Achieved smooth audio playback
What we learned:
Neural voice synthesis complexities Audio signal processing techniques Resource management for audio files REST API design for audio applications Importance of user-centered design
What's next for Voice Studio:
Emotion integration in voice synthesis Multi-language support Enhanced voice customization options Better pitch and pace controls Accessibility features for healthcare applications

Log in or sign up for Devpost to join the conversation.