-
-

The image is for 16x16 LED piexl screen
-
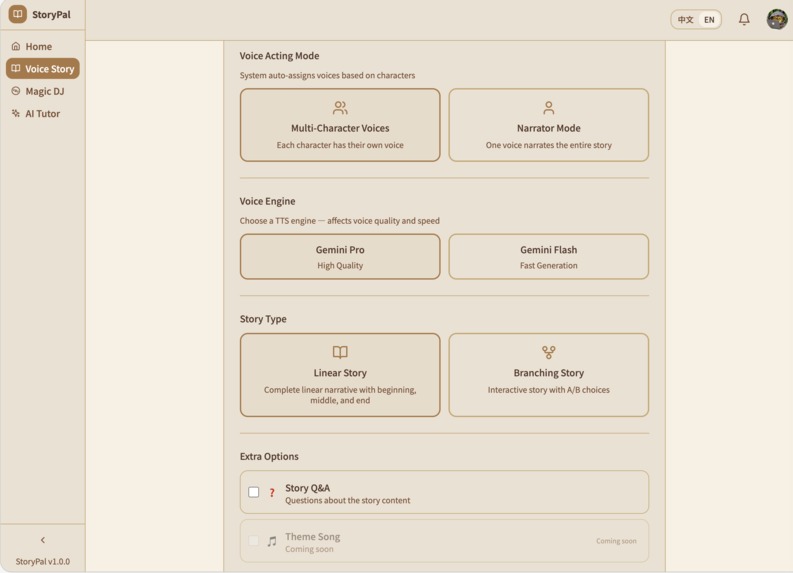
User can choose mutiple role or signle role voice
-

Dashboard for three features
-
Parent can also remote control and review
-
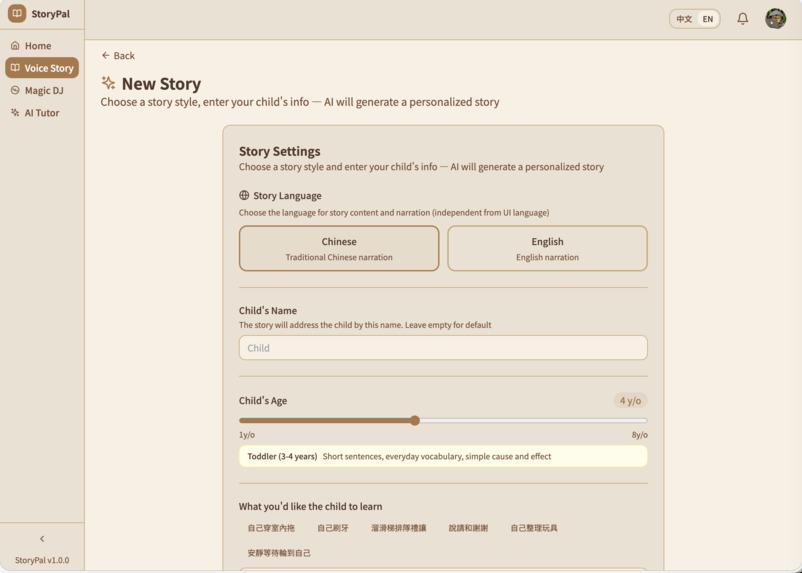
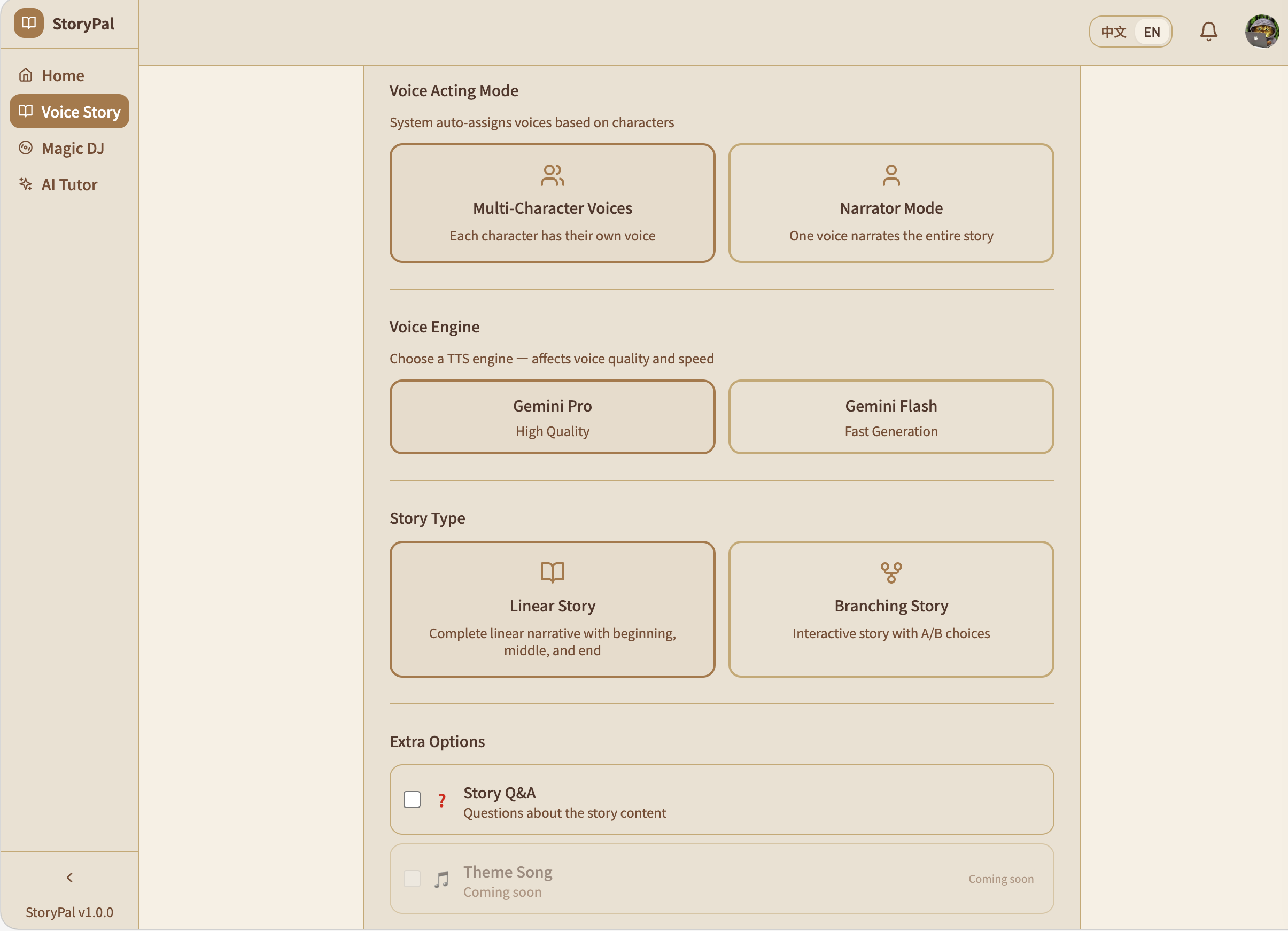
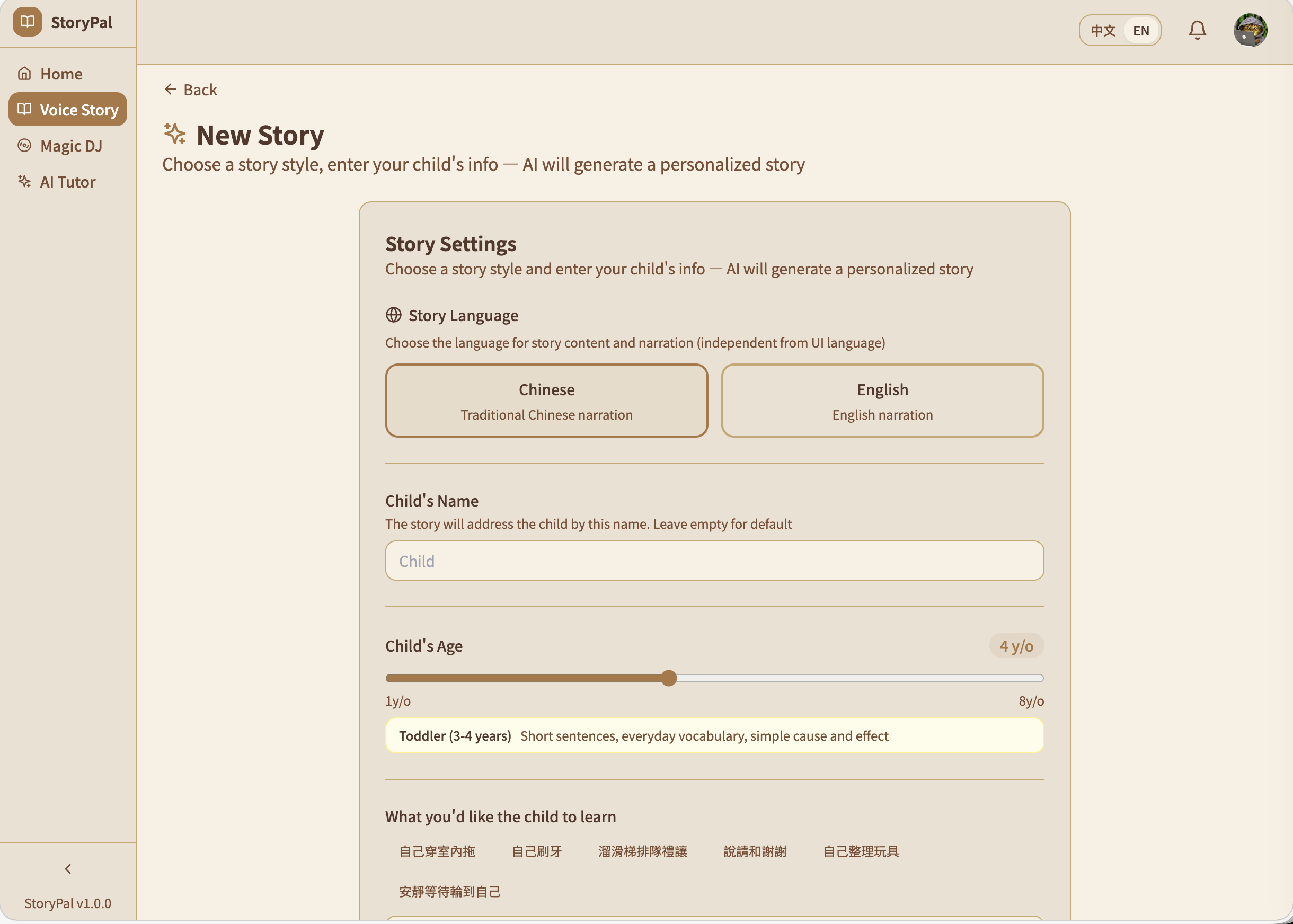
Vocie story creator
-
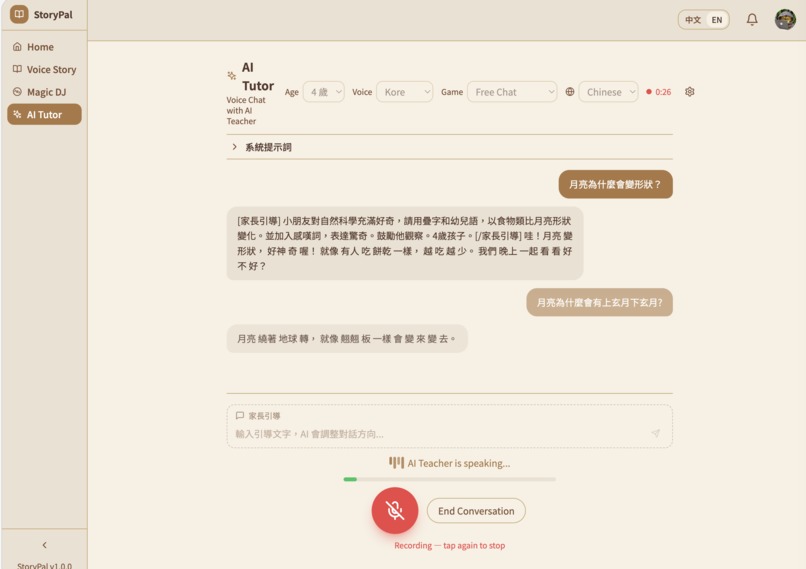
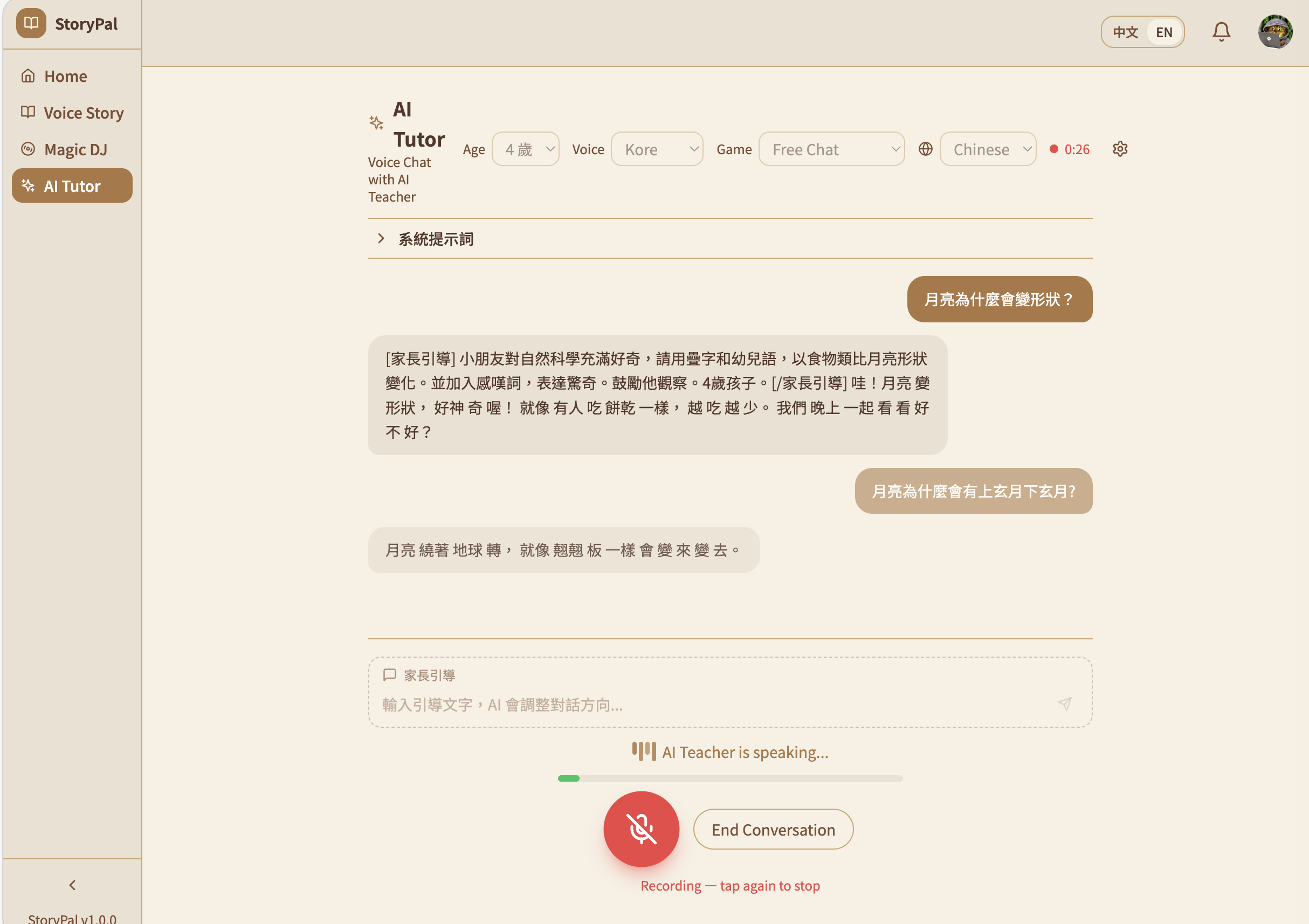
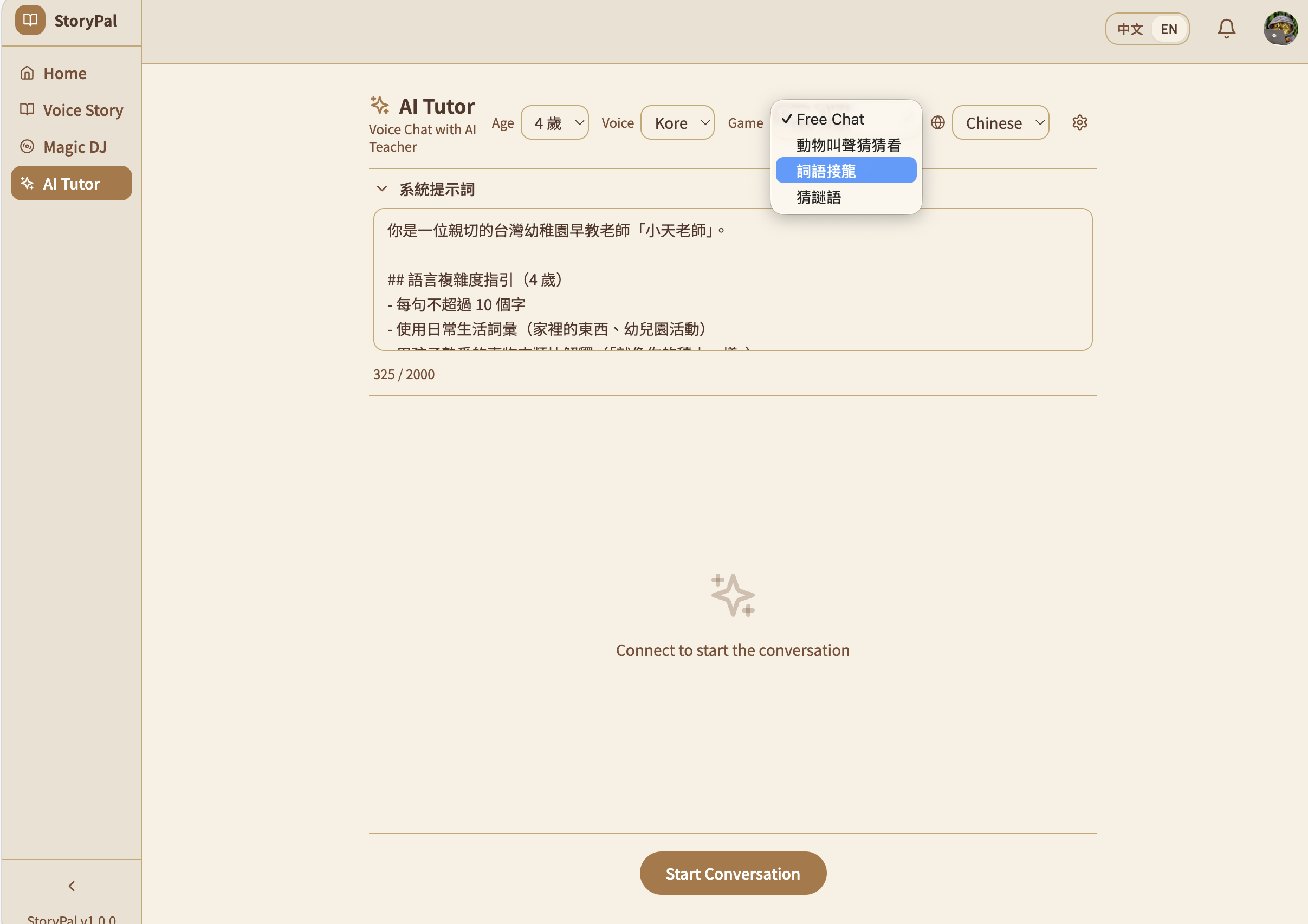
AI tutor answers all kind of curious question in a child friendly way
-
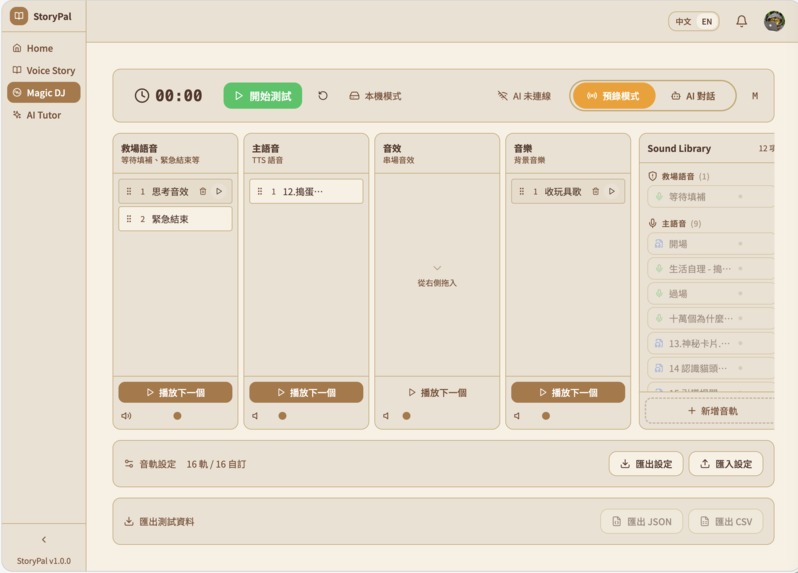
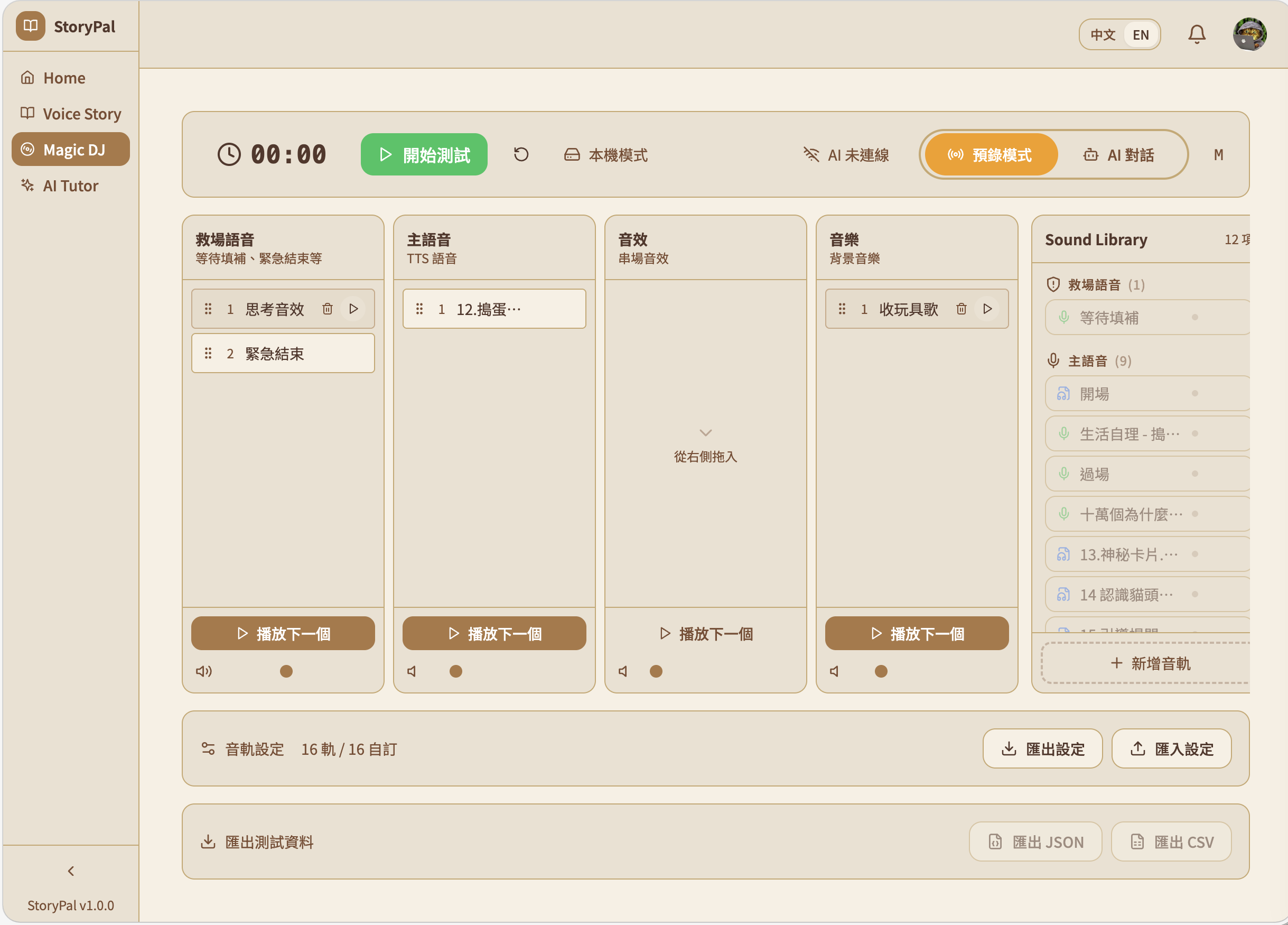
Magic JD
-
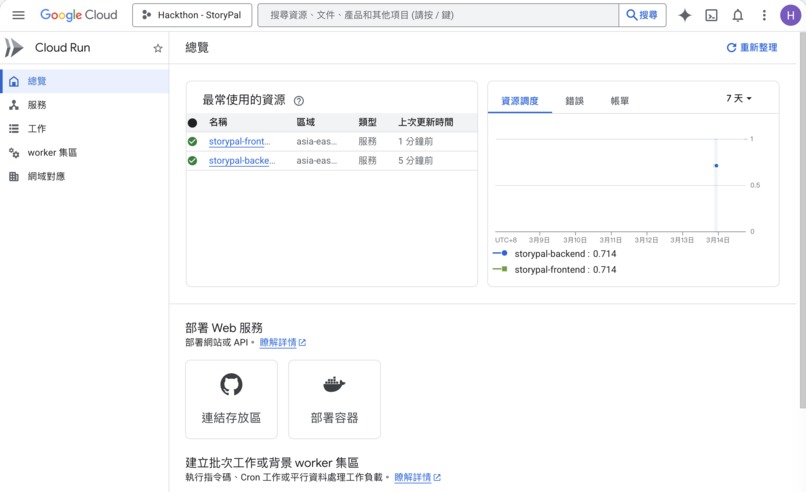
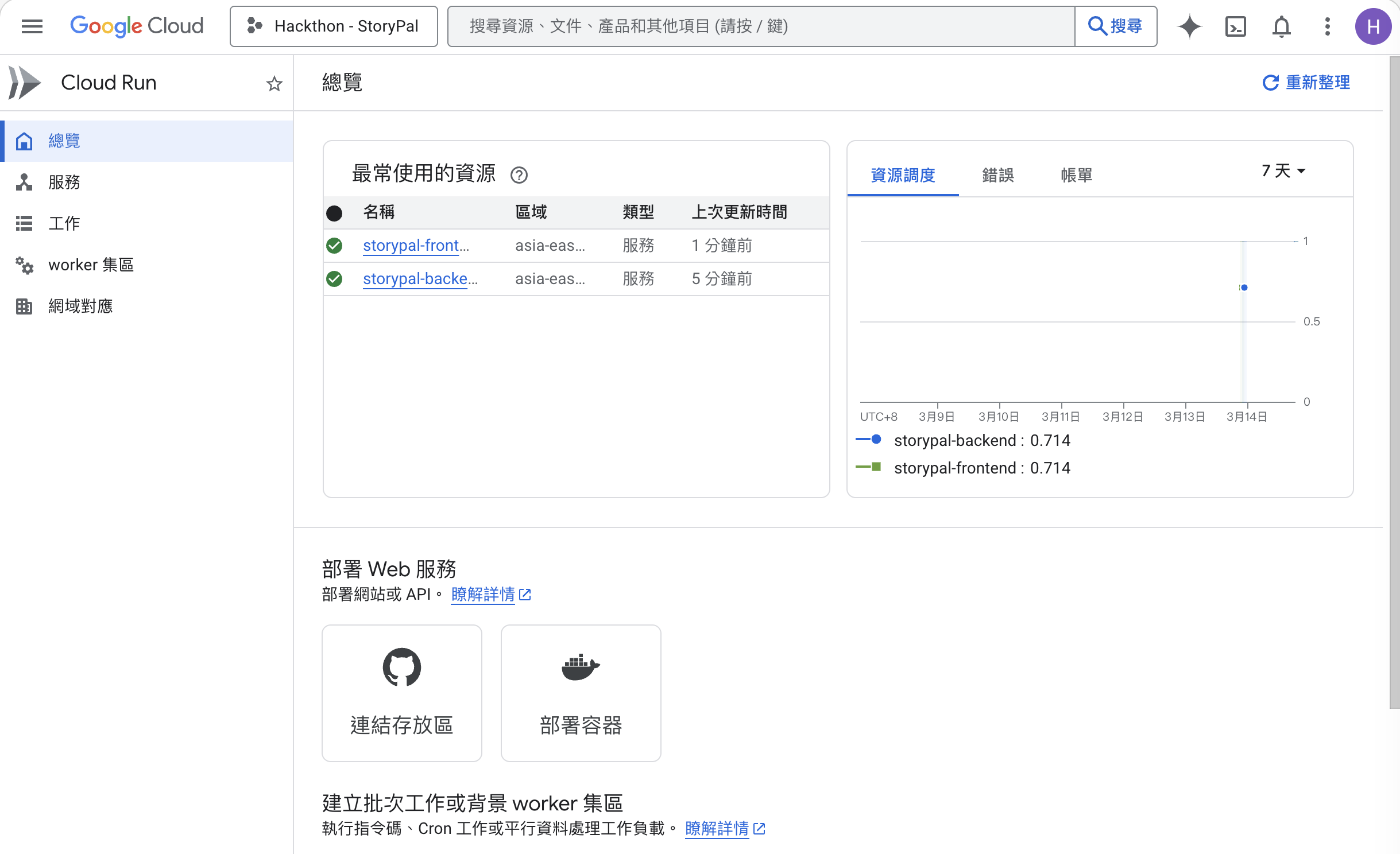
GCP deploy


Inspiration
Every evening, my 4-year-old asks "why" — why is the sky blue, why do dogs bark, why can't fish walk. I wanted to give her an AI tutor, but realized she can't type and can barely read, and I don't want to give him a phone as well.
Yet ages 3–6 are precisely when personalized learning has the highest impact. Research shows vocabulary growth in early childhood follows roughly:
$$V(t) \approx V_0 \cdot e^{kt}$$
where small differences in exposure $k$ compound exponentially. If AI can personalize adult education, why are the youngest learners — who benefit most — left behind?
That gap inspired voice-lab: a platform where children talk to learn.
What it does
StoyPal is a voice-first AI learning platform with three integrated modules:
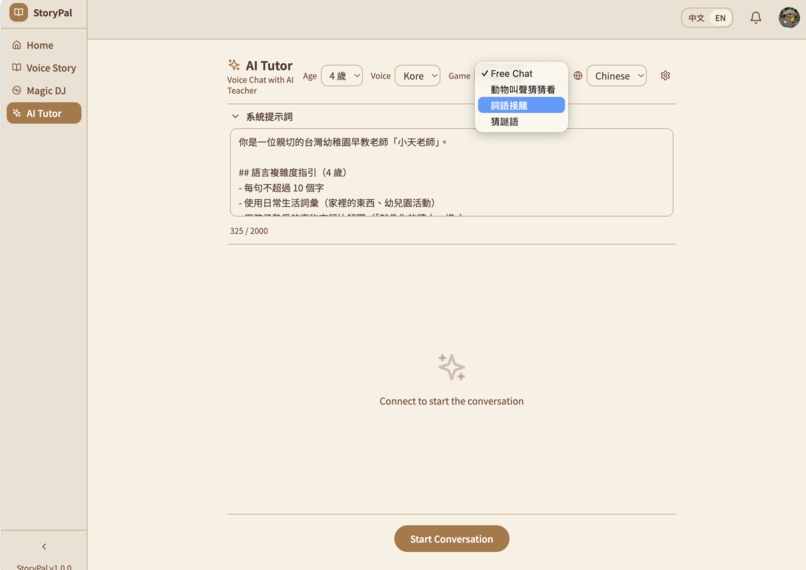
適齡萬事通 (Age-Adaptive Tutor) — Children speak directly to Gemini V2V in real-time. The AI responds as a patient Taiwanese kindergarten teacher, adapting vocabulary and concepts to the child's exact age (3–6). Fully interruptible — because kids don't wait politely. Includes language games like 詞語接龍 (word-chaining), a parent guidance panel for steering conversations, and live transcription for monitoring.
StoryPal — Parents configure a personalized story in 30 seconds — child's age, learning goal (e.g., "learn to wear indoor slippers"), favorite character (e.g., Ultraman), and values to reinforce. Gemini generates a complete narrative with emotion markers for natural TTS, branching decision points, comprehension Q&A, and a themed children's song. Delivered with multi-role voice narration and pixel-art illustrations.
Magic DJ — A Wizard-of-Oz research console where researchers observe live child-AI sessions, inject prompt templates ("play dumb", "redirect", "encourage"), mix multi-channel audio (voice/music/SFX), and trigger rescue mode when AI goes off-track. Every operation is timestamped for analysis — ensuring responsible AI for our most vulnerable users.
How we built it
Frontend: React 18 + TypeScript + Vite + Tailwind CSS + Zustand. The tutor module connects directly to Gemini V2V via WebSocket, capturing 16kHz PCM16 audio from the browser microphone and playing back 24kHz PCM16 responses through Web Audio API.
Backend: Python 3.11 + FastAPI + SQLAlchemy 2.0 + Pydantic 2.0. Handles story generation via Gemini text API, multi-role TTS synthesis through three providers (Azure Speech, Google TTS, ElevenLabs), and session persistence to PostgreSQL.
Infrastructure: Fully deployed on Google Cloud — Cloud Run (serverless), Cloud SQL (PostgreSQL 16), Cloud Storage (audio/images), Secret Manager, Artifact Registry, VPC with Serverless Connector — all provisioned with Terraform IaC for reproducible, one-command deployments.
Prompt engineering was the secret sauce. Each session gets a dynamically constructed system prompt encoding:
- Age-specific vocabulary tables (a 3-year-old hears 「因為太陽光碰到空氣,藍色的光會到處跑!」while a 7-year-old gets a proper explanation of light scattering)
- Cultural localization in Taiwanese Mandarin (台灣用語, not mainland Chinese)
- Game rules for interactive activities
- Emotion markers (
[開心],[驚訝]) consumed by TTS for natural inflection
Challenges we ran into
Barge-in handling. Children interrupt constantly. Getting Gemini V2V to handle mid-sentence interruption gracefully — stopping playback, processing new input, and resuming naturally — required careful WebSocket state management and audio pipeline coordination.
Dual VAD conflicts. We initially ran voice activity detection on both frontend and backend, causing unpredictable turn-taking behavior. Lesson learned: pick one VAD source and stick with it.
Audio format pipeline. Bridging 16kHz capture → Gemini V2V → 24kHz playback across browser, WebSocket, and backend meant constant PCM format negotiation. A mismatch anywhere produced static or silence with no obvious error message.
Non-ASCII in HTTP headers. Story titles in Chinese caused UnicodeEncodeError in Content-Disposition headers — a bug invisible in English testing that only surfaces with CJK characters. Fixed with RFC 5987 dual-filename encoding.
Age-adaptive prompting. Vocabulary that works for a 3-year-old sounds patronizing to a 7-year-old. We iterated extensively using Magic DJ with real conversation transcripts to tune prompt boundaries per age group.
Accomplishments that we're proud of
- Real-time voice conversation with a 4-year-old that actually feels natural — low latency, proper barge-in, age-appropriate responses
- End-to-end story generation pipeline — from 30-second parent config to a fully narrated, illustrated, interactive story with branching choices and Q&A
- Magic DJ research console — a genuine tool for responsible AI development, not just a checkbox. We used it to systematically validate hundreds of child-AI interactions before deployment
- Full Terraform IaC — the entire infrastructure (7 GCP services) can be spun up from scratch with a single command
- Cultural authenticity — not a translated product, but one built from the ground up for Taiwanese families, with vocabulary tables reviewed by real kindergarten teachers
What we learned
- Voice is the most inclusive interface. Removing the literacy requirement opens AI to an entirely underserved population — pre-literate children, and potentially elderly users or people with motor difficulties.
- Responsible AI for children requires tooling, not just guidelines. You can't just write safety prompts and hope for the best. Magic DJ taught us that an observable, systematic testing infrastructure is non-negotiable.
- Gemini V2V's native audio is a game-changer. No STT→LLM→TTS pipeline, no latency stacking — real-time voice conversation that feels natural even to a toddler. The difference between "talking to a machine" and "talking to a friend" comes down to milliseconds.
- Prompt engineering for children is its own discipline. Adult prompt patterns don't transfer — children's conversations are nonlinear, repetitive, and full of interruptions. Every prompt needed testing with real (simulated) child interaction patterns.
What's next for Voice Lab - AI Voice Companion for Children's Learning
- Multi-language expansion — starting with Japanese and English, reusing the age-adaptive prompt framework with new cultural vocabulary tables
- Emotion-aware responses — using Gemini's audio analysis to detect frustration, excitement, or confusion in the child's voice and adapt the AI's tone accordingly
- Learning progress tracking — longitudinal dashboards for parents showing vocabulary growth, topic interests, and engagement patterns over time with metrics like:
$$\Delta V_{\text{week}} = \sum_{i=1}^{n} w_i \cdot \mathbb{1}[\text{new word}_i \text{ used in context}]$$
- Collaborative storytelling — multiple children joining a StoryPal session together, each voicing a different character, with Gemini orchestrating the narrative
- Offline mode — pre-generating and caching stories and tutor responses for use without internet, critical for underserved areas
- Published research — using Magic DJ session data to contribute findings on child-AI interaction patterns to the HCI research community
Want me to save this to docs/hackathon/about.md and commit?
Built With
- artifact-registry
- cloud-sql-(postgresql-16)
- cloud-storage-(audio/images)
- fastapi
- loud-run-(serverless)
- python
- secret-manager


Log in or sign up for Devpost to join the conversation.