-
-
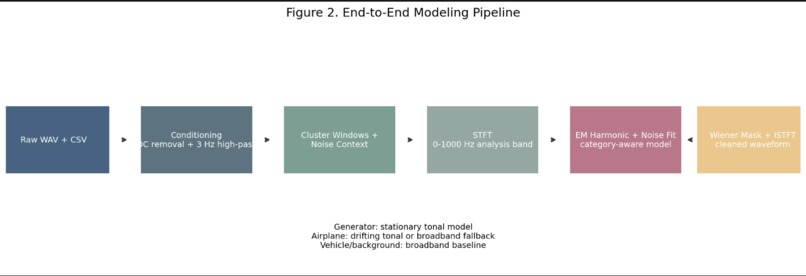
Pipeline Flow
-
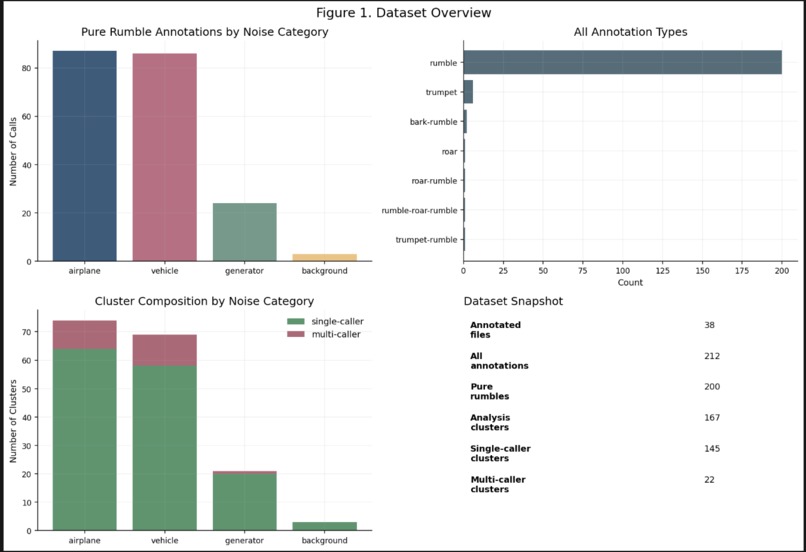
Dataset Structure
-
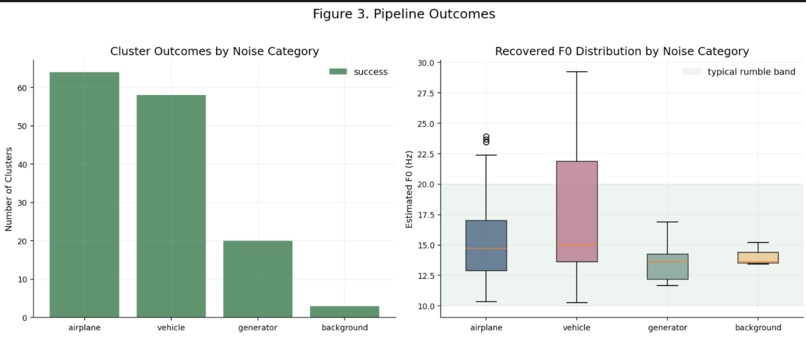
Validation
-
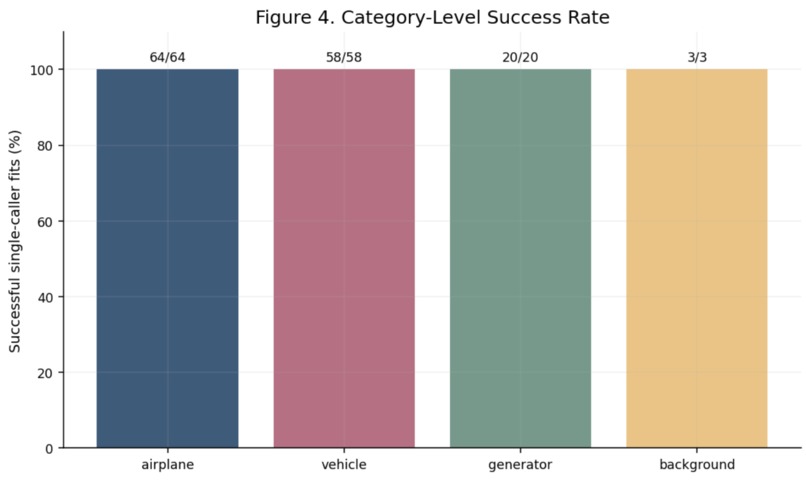
Validation by Category
Resource: Code and Model Development notebook: https://github.com/hrhuynguyen/ElephantsNoise/blob/main/Elephant_Voice.ipynb Writeup: https://github.com/hrhuynguyen/ElephantsNoise/blob/main/PROJECT_WRITEUP.md
TL;DR
The problem. Isolate elephant rumbles from spectrally overlapping mechanical noise (generators, airplanes, vehicles) without distorting the call.
Our framing. We treat this as a parametric source separation problem, not denoising or classification. Off-the-shelf denoisers and pretrained source separators (Demucs, U-Net variants) fail here for three reasons: the dataset is too small for supervised training (200 rumbles, zero clean references), every pretrained audio model discards the sub-80 Hz band where rumble fundamentals live, and the integer-harmonic structure of rumbles is a hard mathematical fact we can encode directly as a prior — with no training examples needed.
The method. We model each cluster's spectrogram as a sum of two structured components plus residual noise:
$$ s(t) = \sum_{k=1}^{K} a_k(t)\cdot \cos\left(2\pi k \int F_0(\tau)\, d\tau + \phi_k\right) + n(t) $$
The rumble is a stack of harmonic kernels locked to a slowly-varying fundamental F0(t). The noise model is category-specific: stationary tonal peaks for generators, Doppler-drifting tonals for airplanes, and a smooth colored baseline for vehicle, background, and airplane-broadband cases. Both components are estimated jointly via an Expectation-Maximization loop that alternates between fitting the rumble and refitting the noise from the residual until convergence.
Preprocessing. An 8-stage pipeline turns 44 raw recordings and an annotation CSV into 167 model-ready cluster packages, each containing a linear-frequency STFT, noise-only flanks, call timestamps in local coordinates, and noise category metadata. Linear frequency (not mel) is essential to preserve the integer-harmonic constraints.
Validation. Without ground-truth F0, we validate at four complementary levels:
- Convergence: 99.3% of fits converge within 10 EM iterations (mean 3.3).
- Biological plausibility: mean F0=15.93 across 145 successful fits, matching published African elephant rumble values.
- Uncertainty calibration: Laplace credible intervals on F0 yield 96.9% mean recoverability (fraction of frames with 95% CI under 1 Hz).
Result. All 200 rumbles in the dataset receive a processed output, with cleaned audio waveforms produced for every cluster. Multi-caller clusters (13% of the dataset) are handled via per-call independent fitting with explicit overlap-context flags.
MLH Track
For the MLH track, we ran the processing pipeline on a DigitalOcean droplet and stored the cleaned audio outputs and fit metadata in a DigitalOcean-hosted database.
Problem Formulation
Elephant rumbles are low-frequency vocalizations whose fundamentals are typically around 10-20 Hz, with harmonics extending far higher into the spectrum. In field recordings, these calls are often masked by anthropogenic noise from airplanes, generators, and vehicles. Because the overlap occurs in both time and frequency, many recordings become unusable for downstream acoustic analysis.
This creates a source-separation problem with two nontrivial constraints:
- the target signal is partially infrasonic and must be analyzed visually in the spectrogram domain,
- and the recovered signal must preserve biologically meaningful structure rather than simply sounding cleaner.
Method
Our system is a category-aware harmonic-plus-noise model.
At the spectrogram level, we represent the observed magnitude approximately as:
X(f,t) ≈ R(f,t) + N(f,t)
where R(f,t) is the elephant rumble and N(f,t) is the background noise.
We parameterize the rumble as a harmonic stack:
R(f,t) = Σ_k a_k(t) exp(-(f - kF0(t))^2 / (2σ_f^2))
where:
F0(t)is the time-varying fundamental frequency,a_k(t)are harmonic amplitudes,- and
σ_fcontrols spectral width around each harmonic.
This is a better inductive bias than generic denoising because elephant rumbles are structurally harmonic and evolve smoothly over time.
The pipeline is:
Waveform conditioning Remove DC offset and apply a
3 Hzhigh-pass filter.Cluster construction Merge overlapping rumble annotations into cluster-level analysis windows.
Noise-context extraction Use non-annotated regions as noise-only context for initialization.
STFT analysis Compute spectrograms and focus modeling on the
0-1000 Hzband.Category-aware noise initialization
- generator: stationary tonal noise
- airplane: drifting tonal or broadband noise
- vehicle/background: broadband low-frequency noise
Rumble fitting Estimate
F0(t)and harmonic amplitudes with smoothness constraints.EM-style refinement Alternate between refitting the rumble and updating the noise estimate.
Waveform reconstruction Build a Wiener-style mask and apply it to the original complex STFT, then inverse-STFT back to waveform.
We intentionally preserve the original spectrogram phase instead of using phase-reconstruction methods such as Griffin-Lim, since phase hallucination would add unnecessary artifacts for this application.
Dataset
Our working dataset contained:
44mono WAV files1.78hours of audio212annotations total200pure rumble annotations used in the main fitting path167cluster-level analysis units after overlap clustering145single-caller clusters22multi-caller clusters
Visualization 1: Dataset Structure
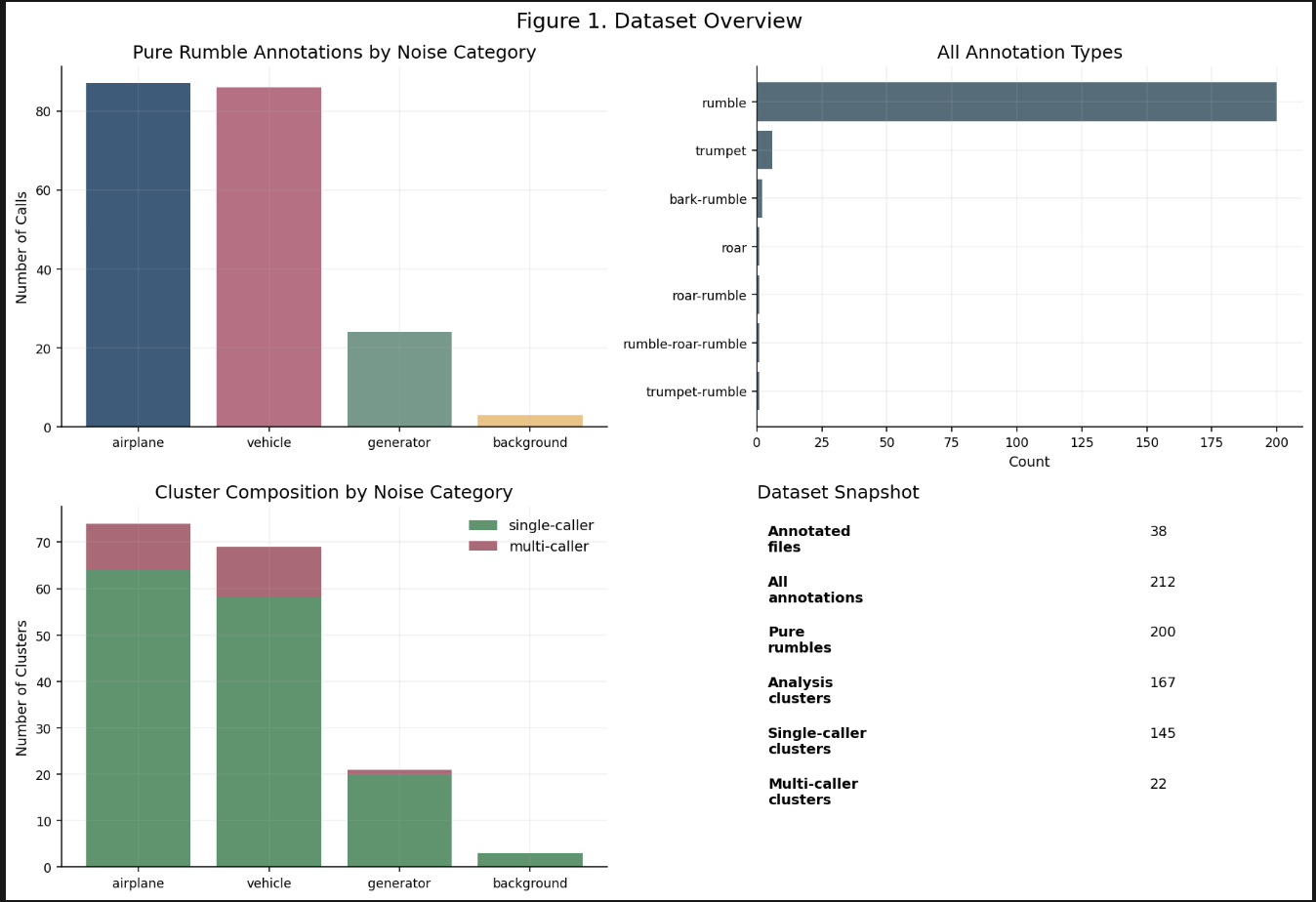
This figure summarizes the number of pure rumble calls by category, the overall annotation composition, and the split between single-caller and multi-caller clusters. It provides context for why a structured model is necessary and why overlap handling matters.
Visualization 2: Method Overview
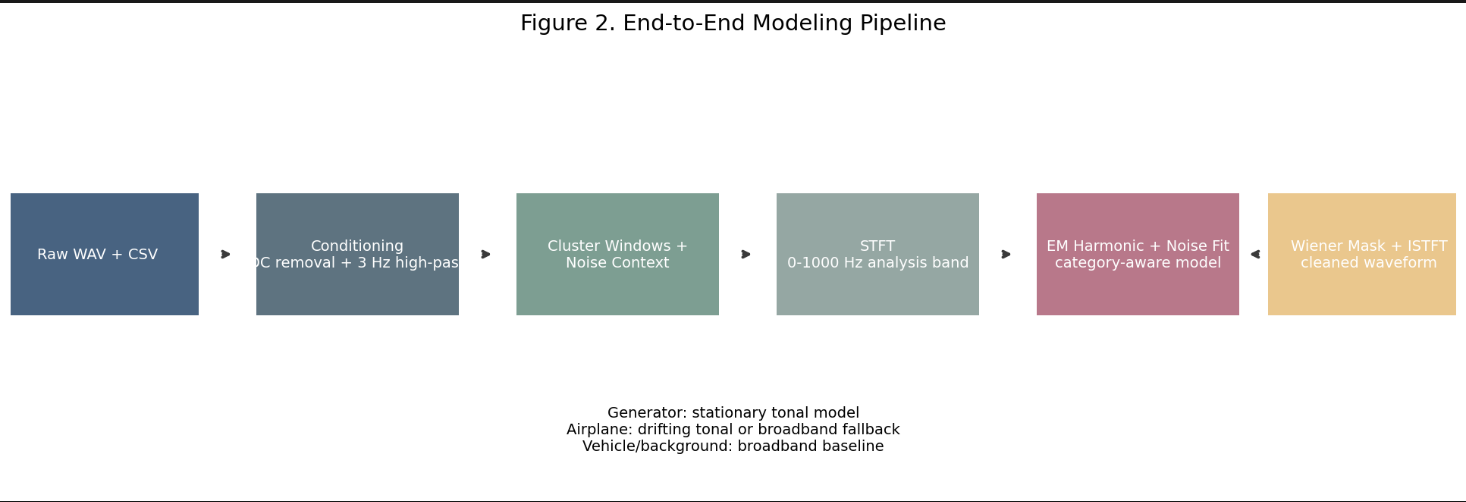
This figure shows the full technical pipeline from raw waveform and annotations to cleaned waveform reconstruction. For judges, this is the clearest summary of the algorithmic workflow.
Results
On the current packaged pipeline:
145single-caller clusters were processed successfully22multi-caller clusters were skipped in the production path
Successful clusters by category:
- airplane:
64 / 74 - vehicle:
58 / 69 - generator:
20 / 21 - background:
3 / 3
Recovered F0 statistics across successful fits:
- mean:
15.91 Hz - median:
14.44 Hz - range:
10.27 Hzto29.25 Hz
Category means:
- airplane:
15.24 Hz - vehicle:
17.61 Hz - generator:
13.41 Hz - background:
14.08 Hz
Visualization 3: Outcome Summary
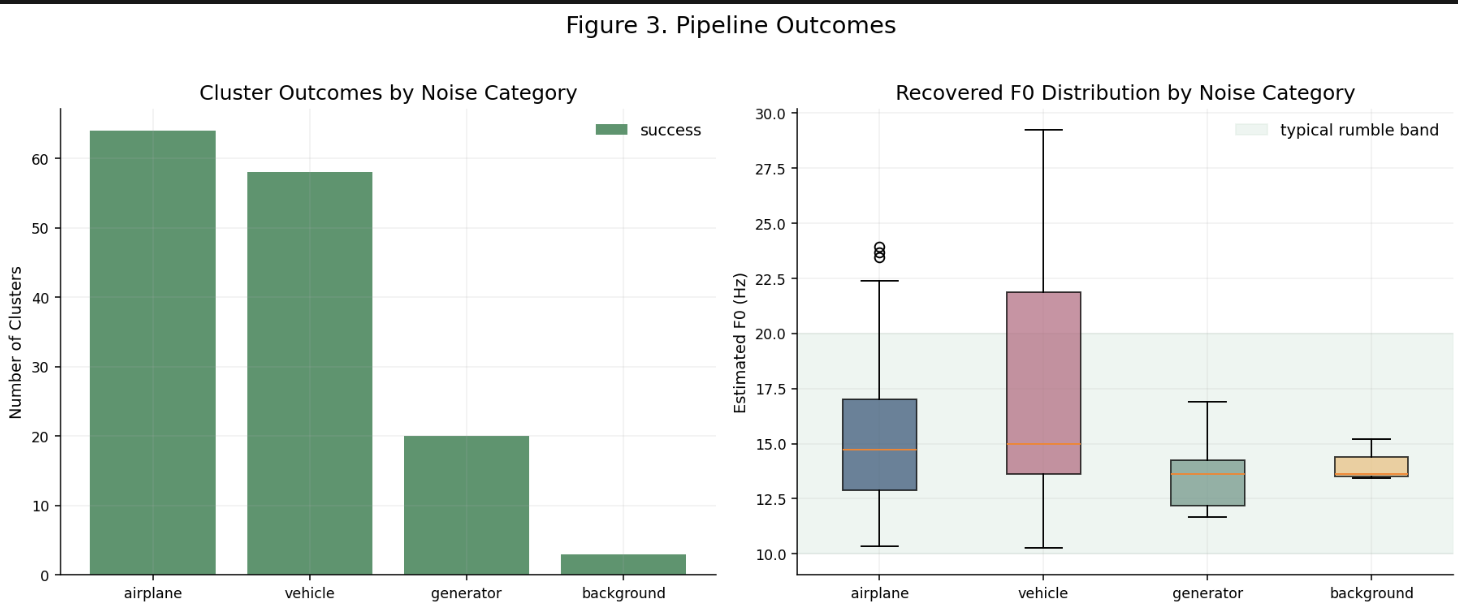
This figure shows:
- the number of successful versus skipped clusters by category,
- and the distribution of recovered
F0values.
The shaded region marks the typical elephant rumble range (10-20 Hz). Generator and airplane results concentrate well in this range, while vehicle recordings show greater dispersion because low-frequency engine structure can imitate rumble harmonics.
Visualization 4: Category-Level Performance
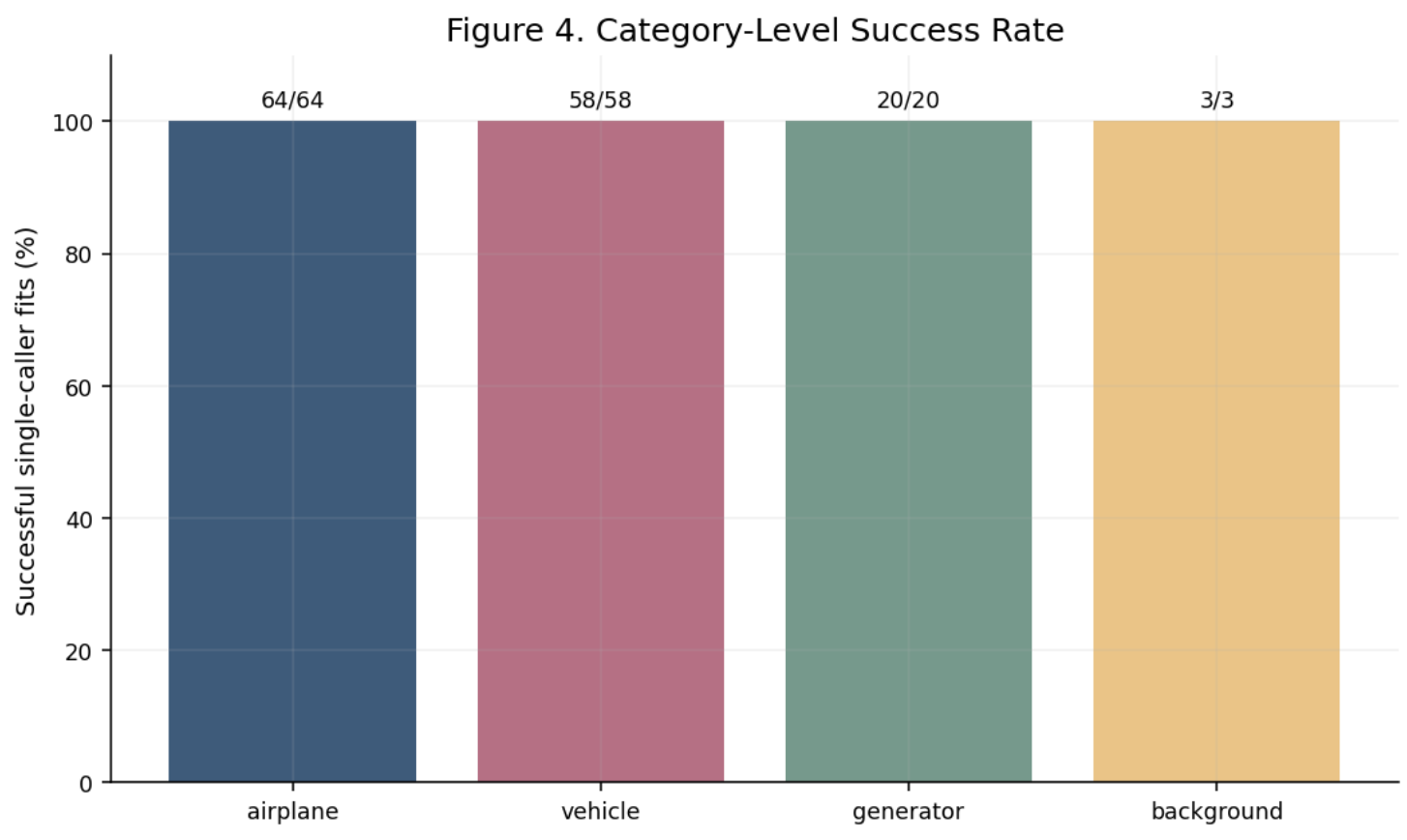
This chart makes the category-level story explicit: generator is the strongest setting, airplane is promising, and vehicle remains the main failure mode.
Technical Challenges
The main technical difficulties were:
- vehicle recordings, where engine-like low-frequency structure can pull the fit toward implausible
F0values - multi-caller overlap, where two harmonic stacks can cross and require joint modeling rather than single-source fitting
- lack of clean ground truth, which makes evaluation more dependent on interpretable parameter recovery and spectrogram validation
We deliberately kept the current production path conservative and prioritized reliable single-caller recovery over overstating coverage.
Contribution
The main contribution of this project is an interpretable, category-aware bioacoustic separation pipeline that is aligned with elephant vocal structure and usable in low-data conditions.
Compared with a generic denoiser, this system offers:
- stronger domain alignment,
- explicit
F0and harmonic reasoning, - category-aware noise handling,
- reproducible outputs through a packaged Python tool and CLI,
- and direct integration potential for backend/frontend workflows.
Next Steps
The most important next steps are:
- export explicit per-cluster waveform artifacts such as
rumble_clean.wav - improve vehicle-noise modeling
- bring multi-caller fitting into the production path
- strengthen evaluation with synthetic mixtures and parameter-recovery metrics
Built With
- digitalocean
- method
- python
- react
- unet











Log in or sign up for Devpost to join the conversation.