-
-
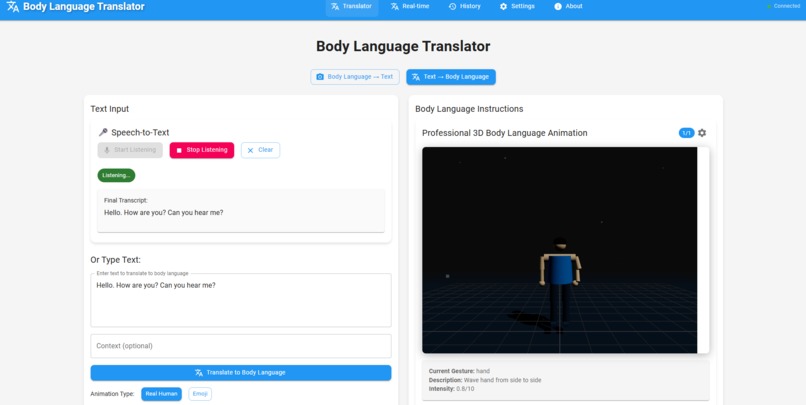
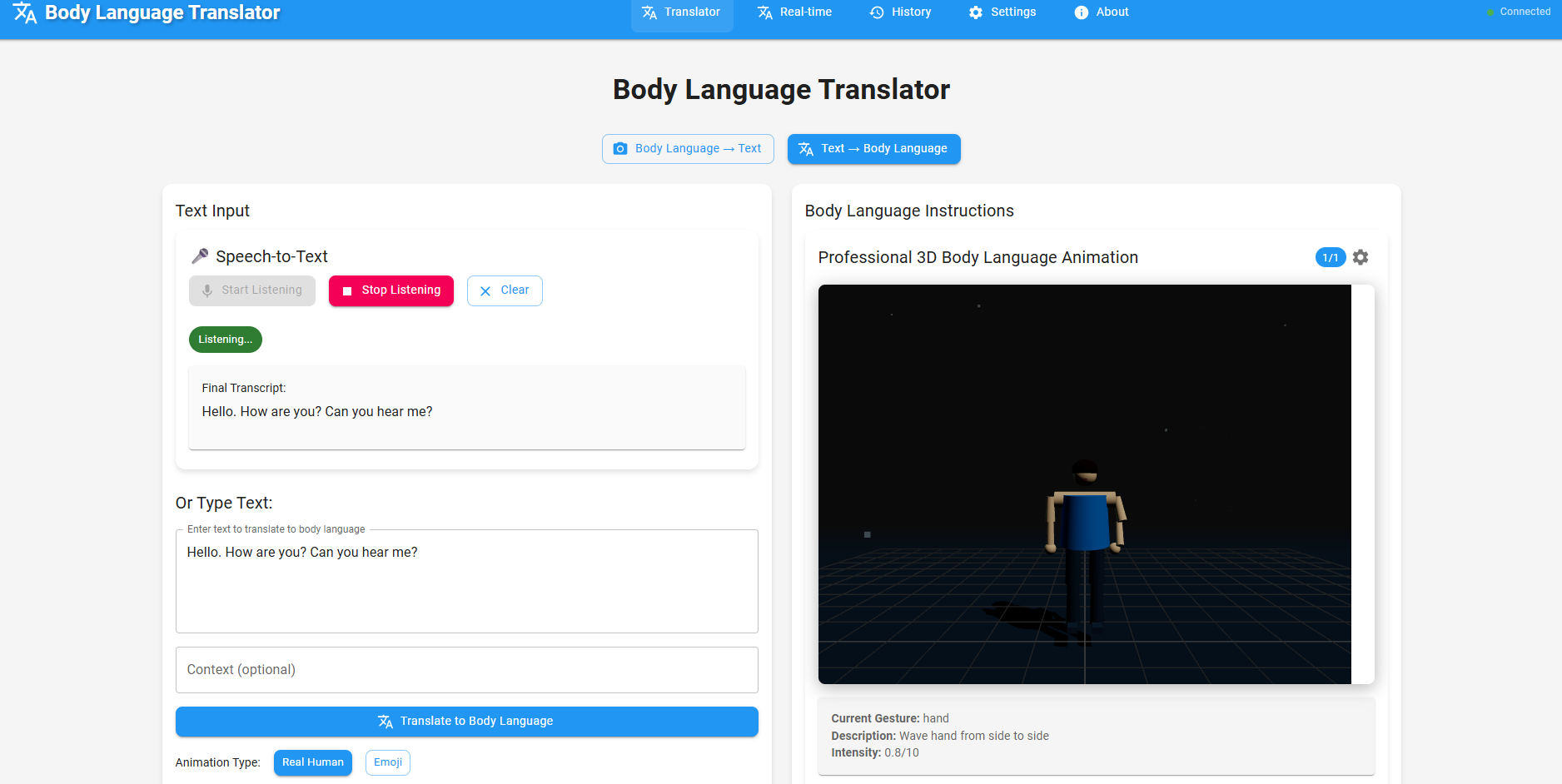
Translator panel- Text to body language
-
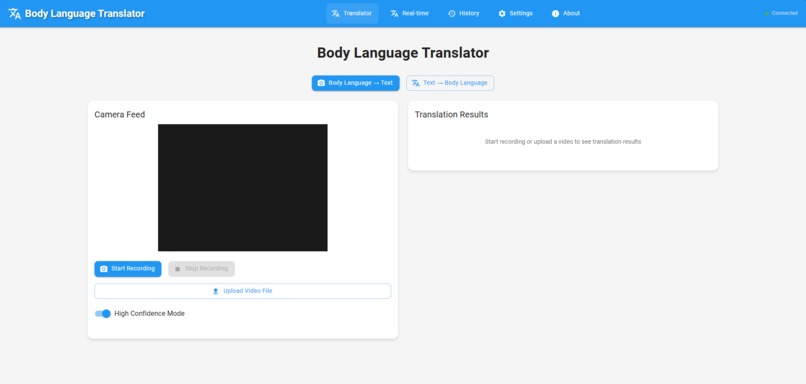
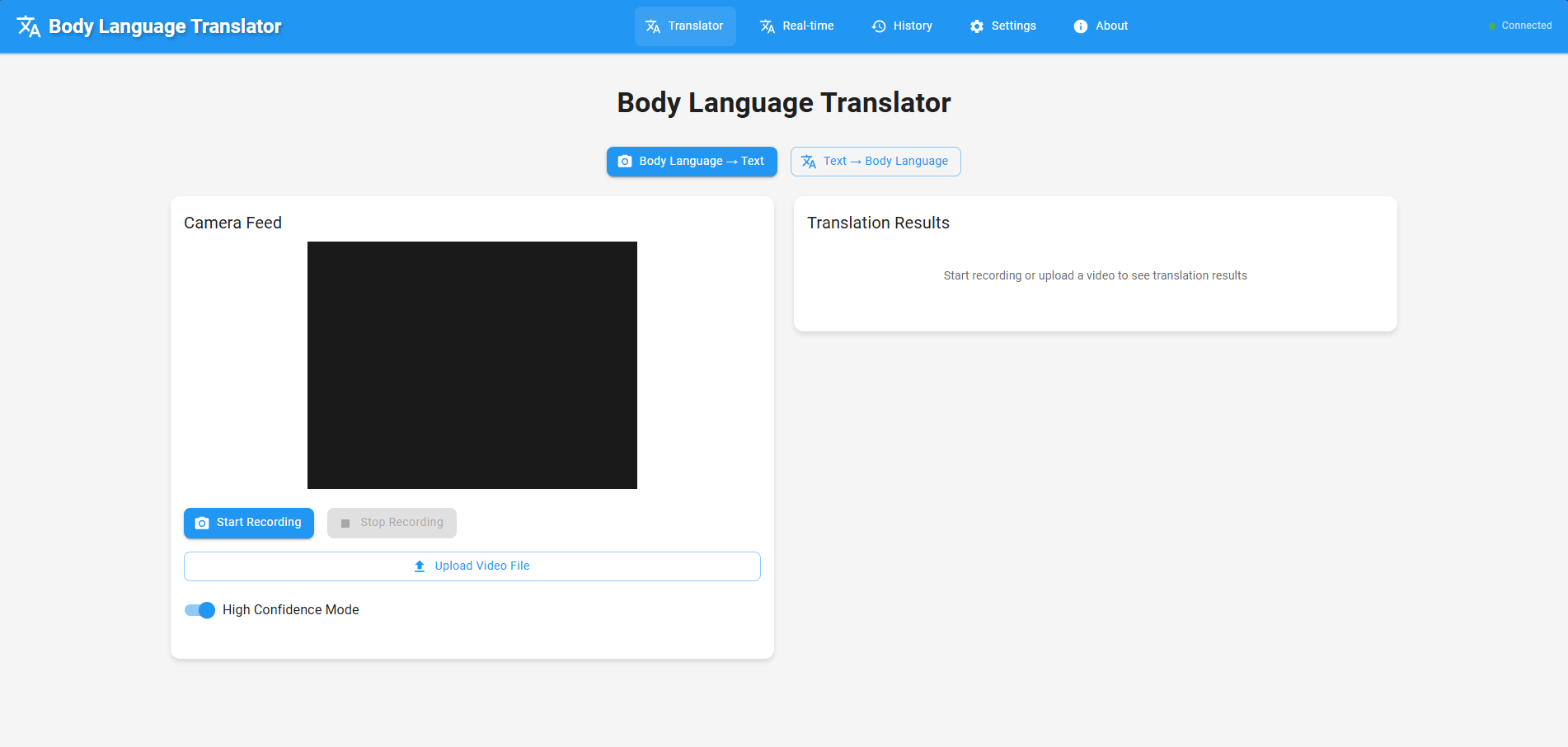
Translator panel- Body language to text
-
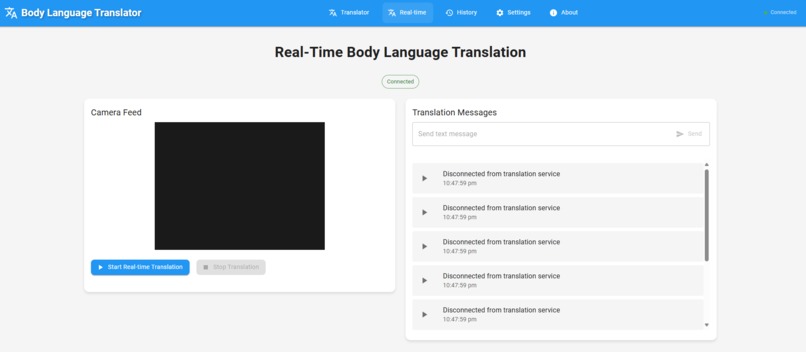
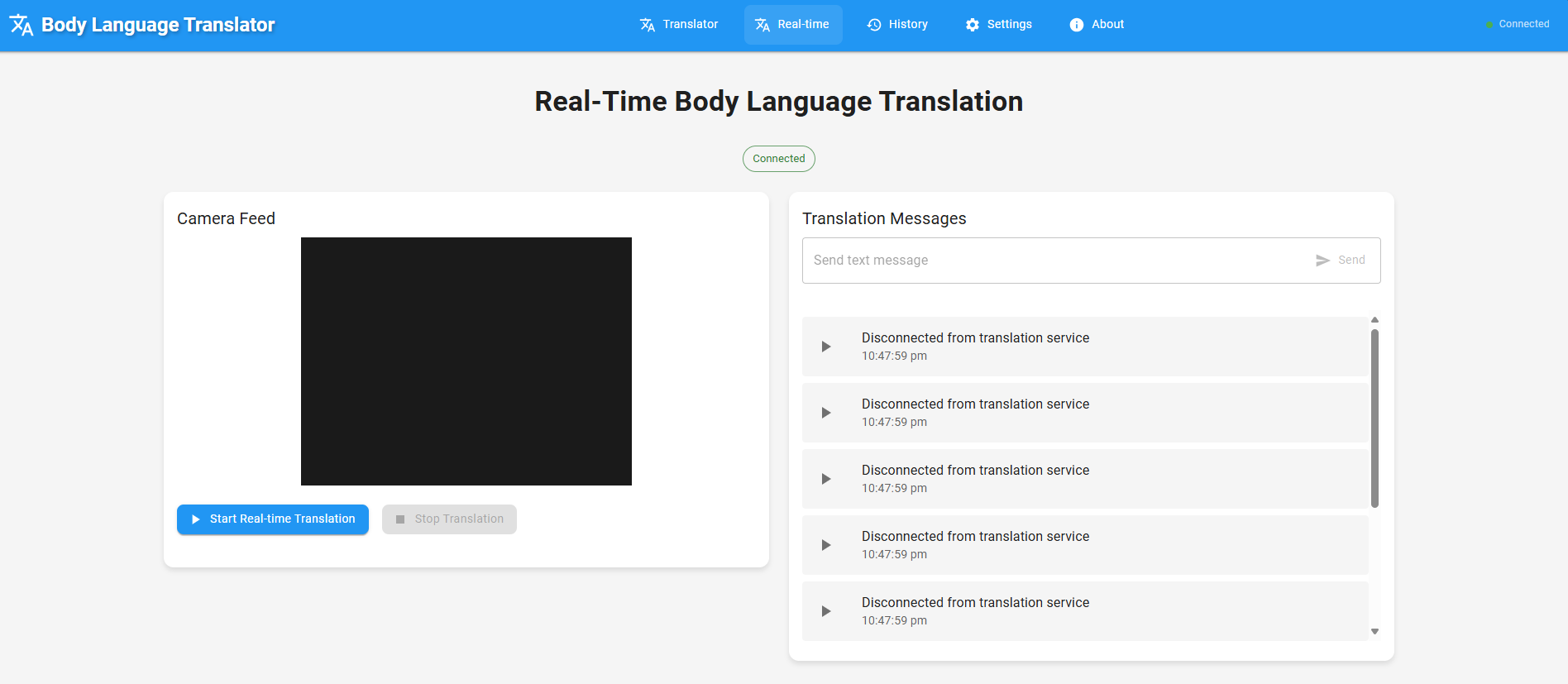
Real-time translation panel
-
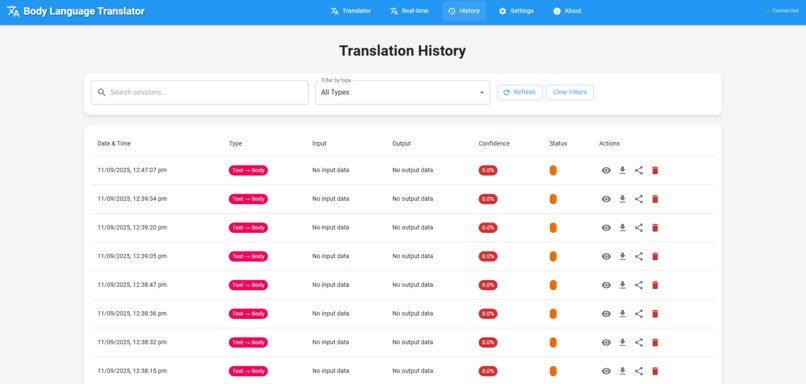
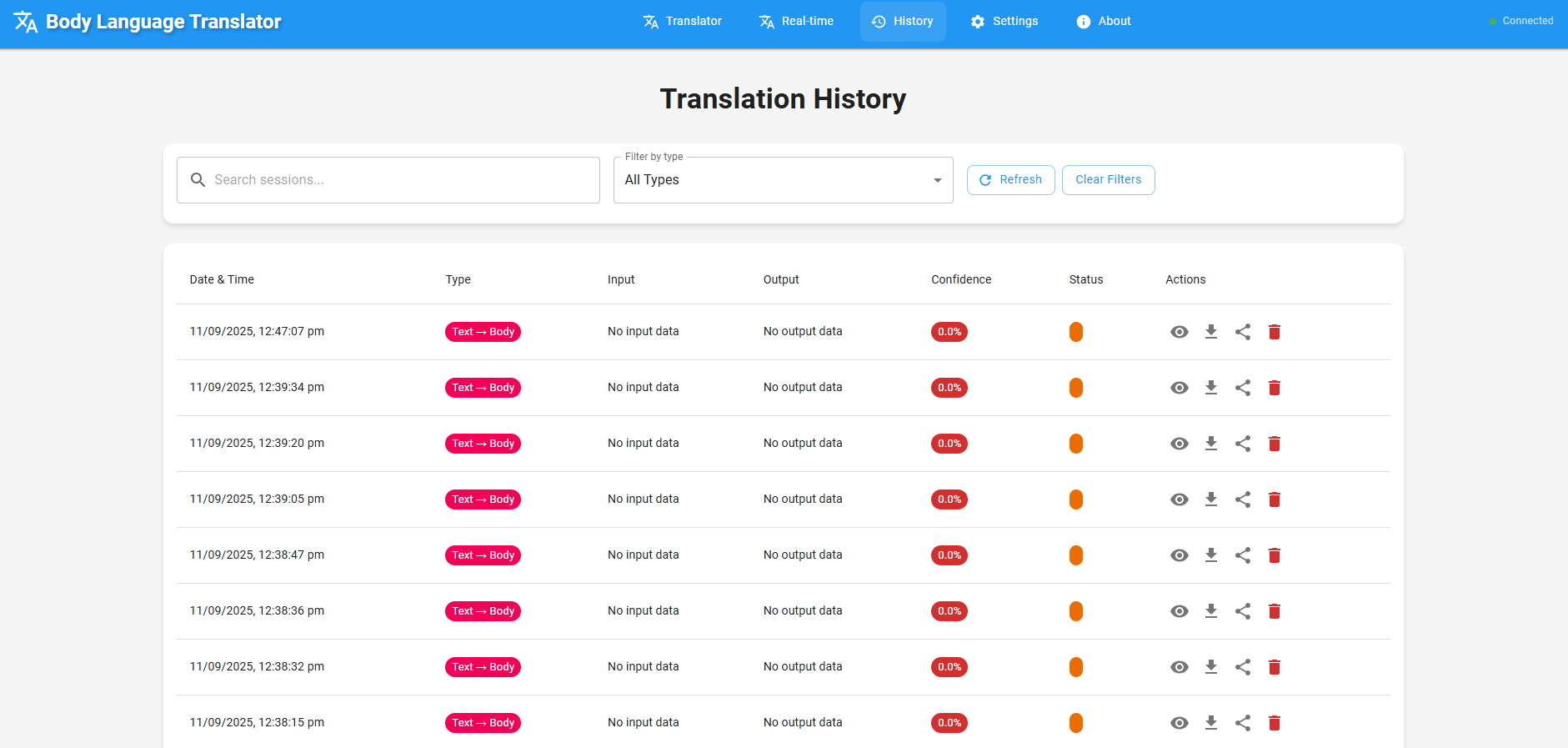
History panel
-
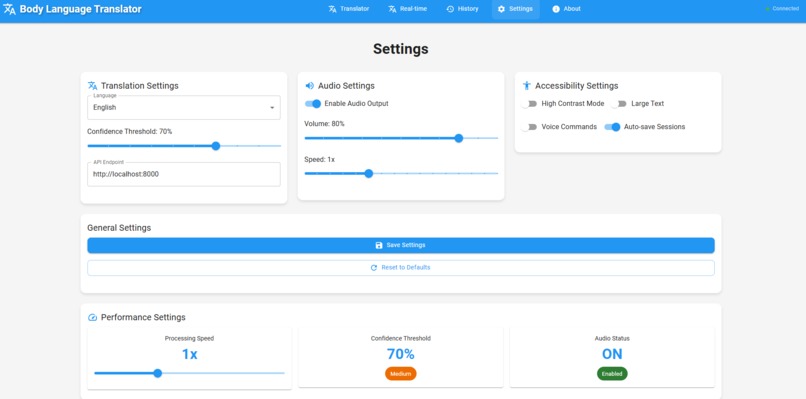
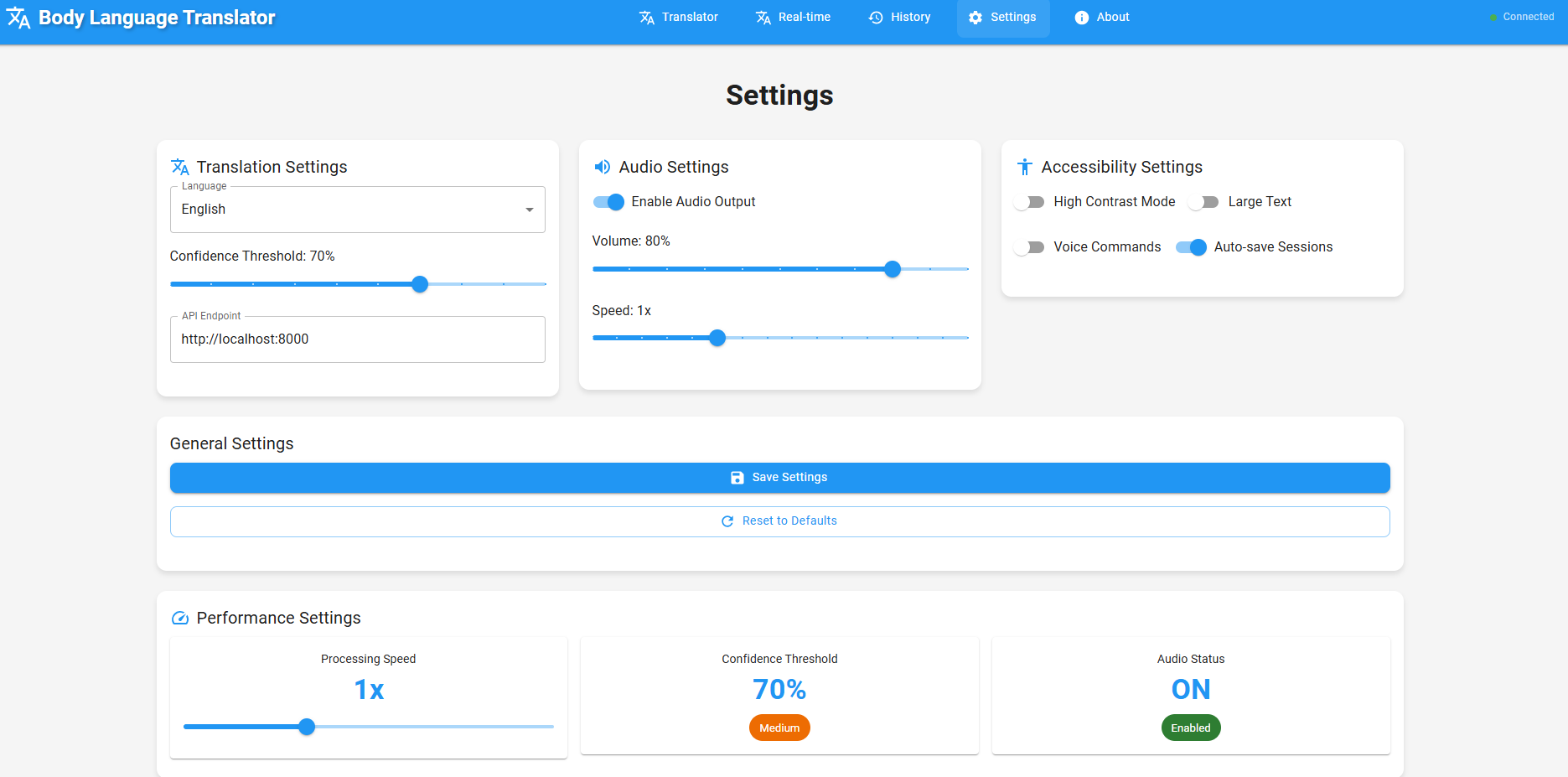
Settings panel
-
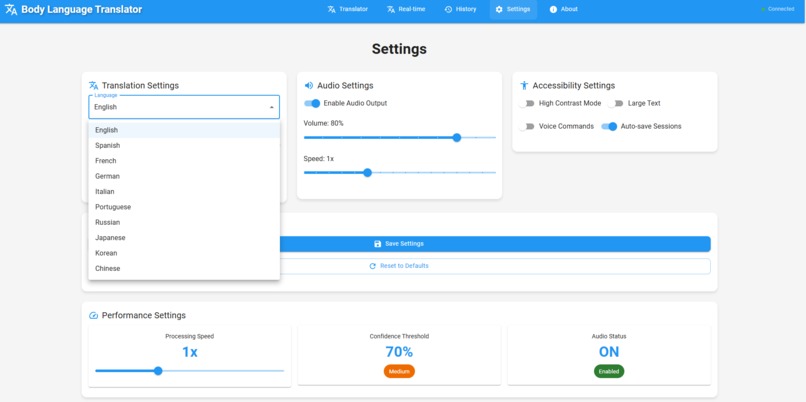
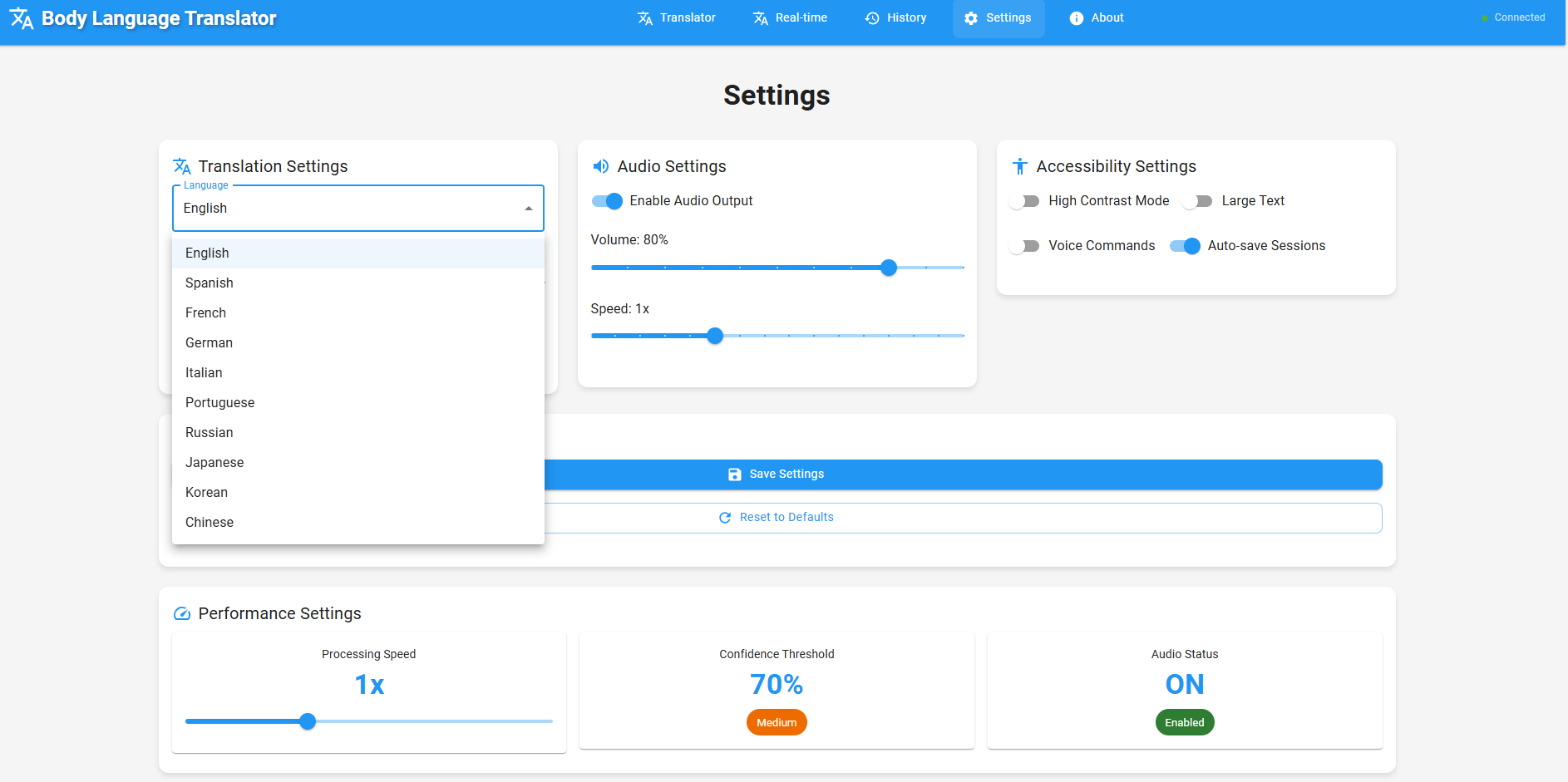
Settings panel representing supported languages
-
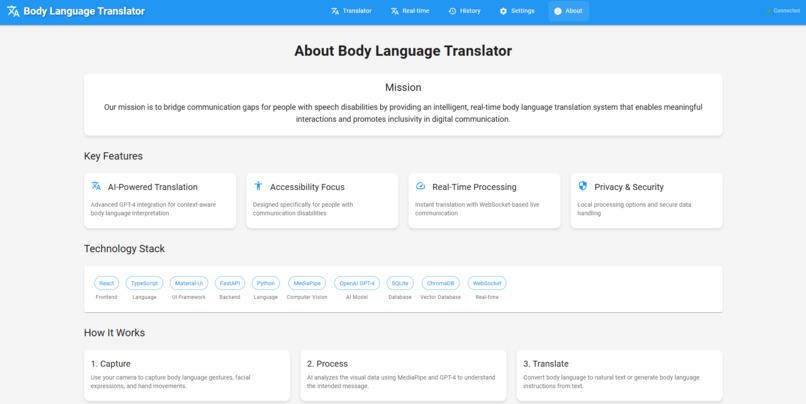
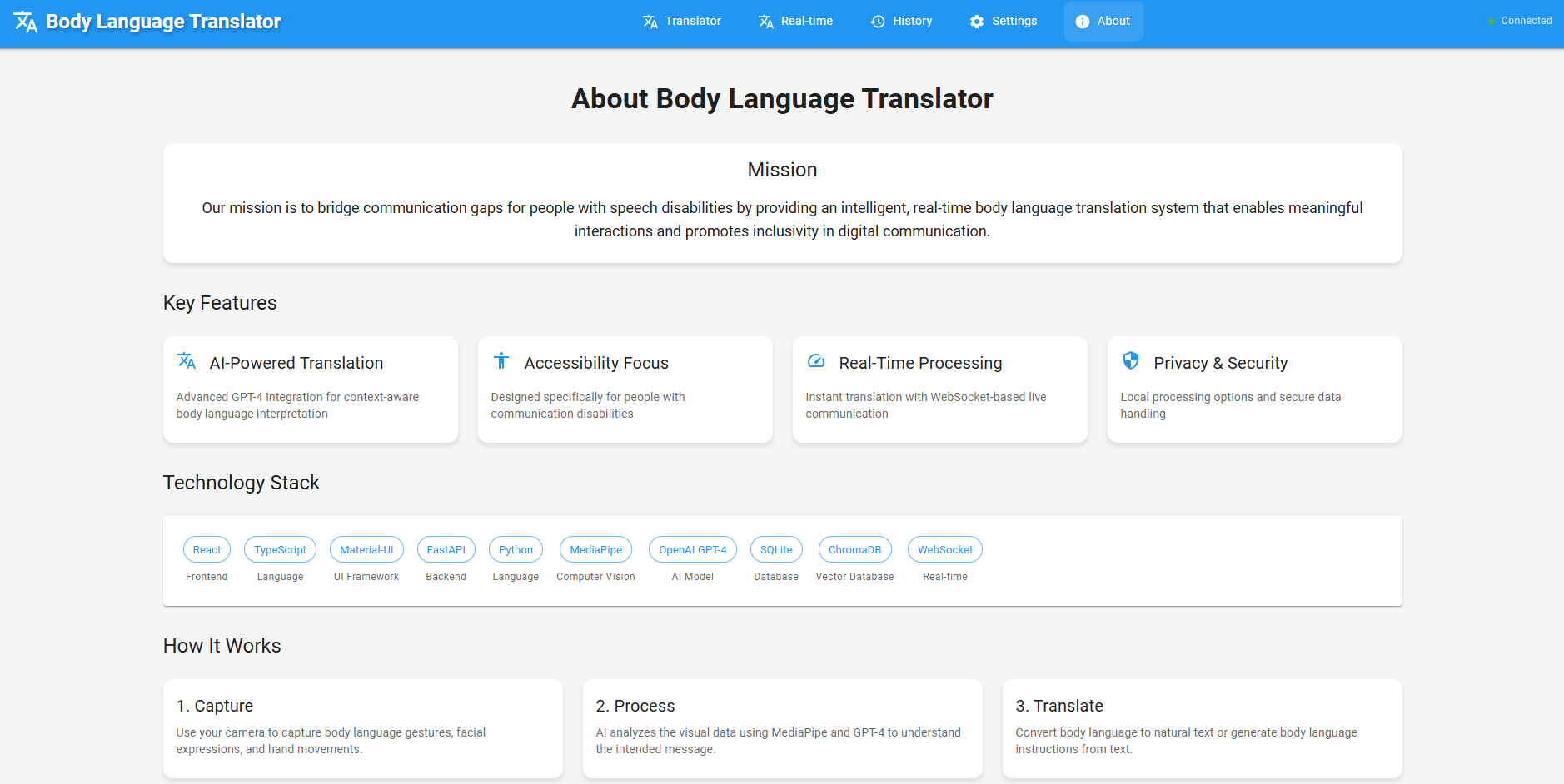
About panel-1
-
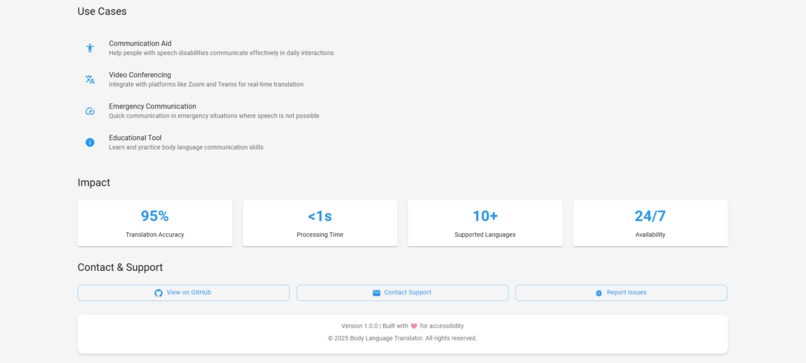
About panel-2
-
Inspiration
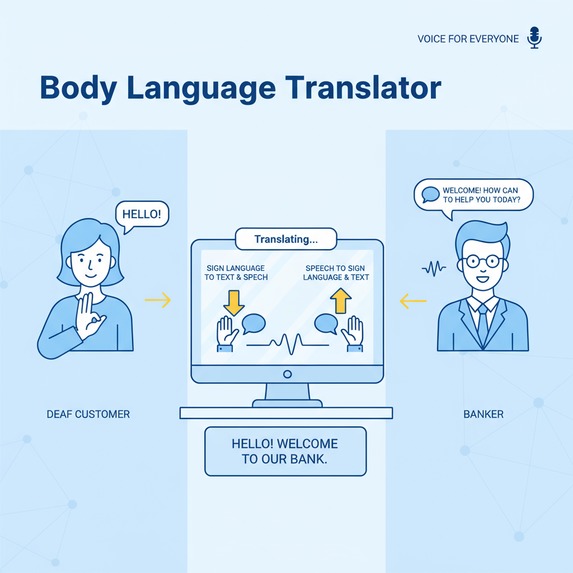
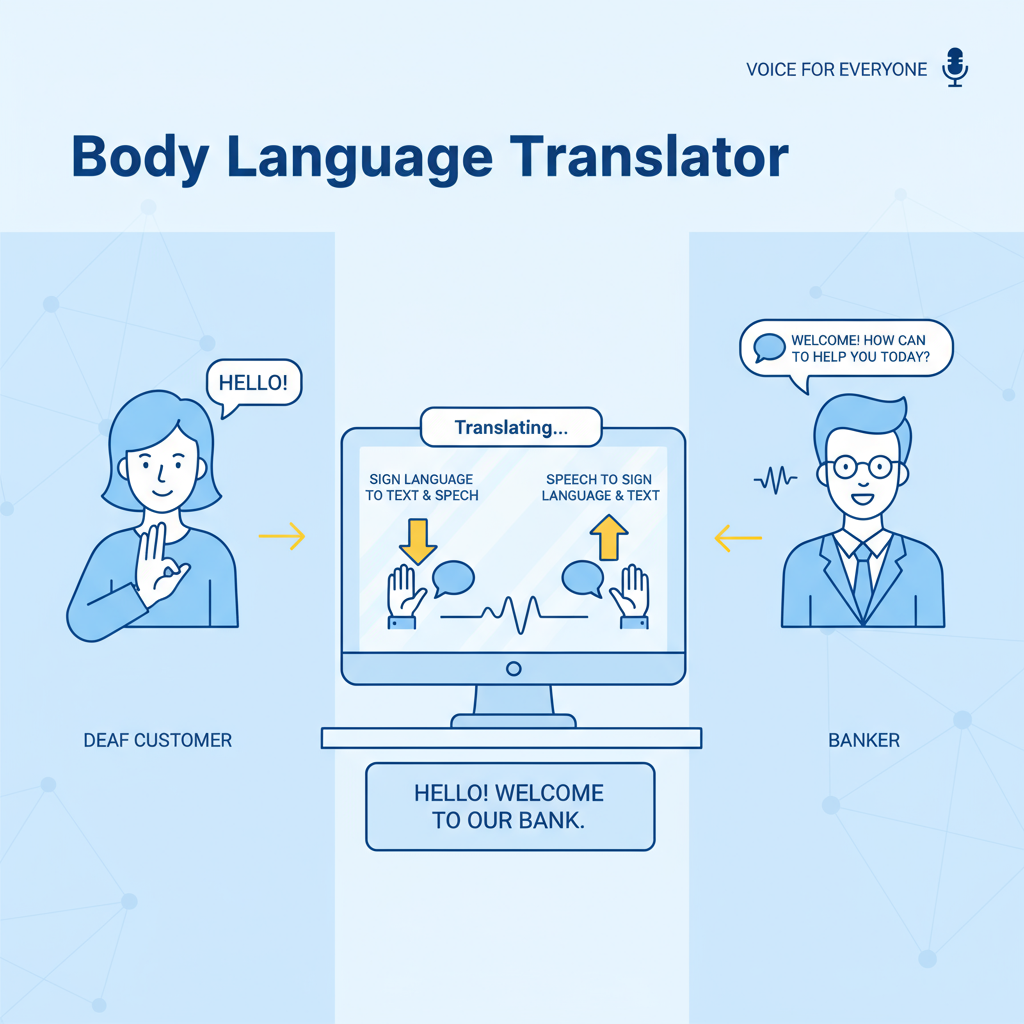
The inspiration came from imagining a world where people who are deaf or non-verbal could communicate naturally with others, not just through interpreters, but directly in real time. I wanted to create an app that translates body language ↔ natural human language, both in daily interactions and video calls (e.g., Zoom, MS Teams, WhatsApp). Everyone deserves to be involved in the society and communicate without any barriers.
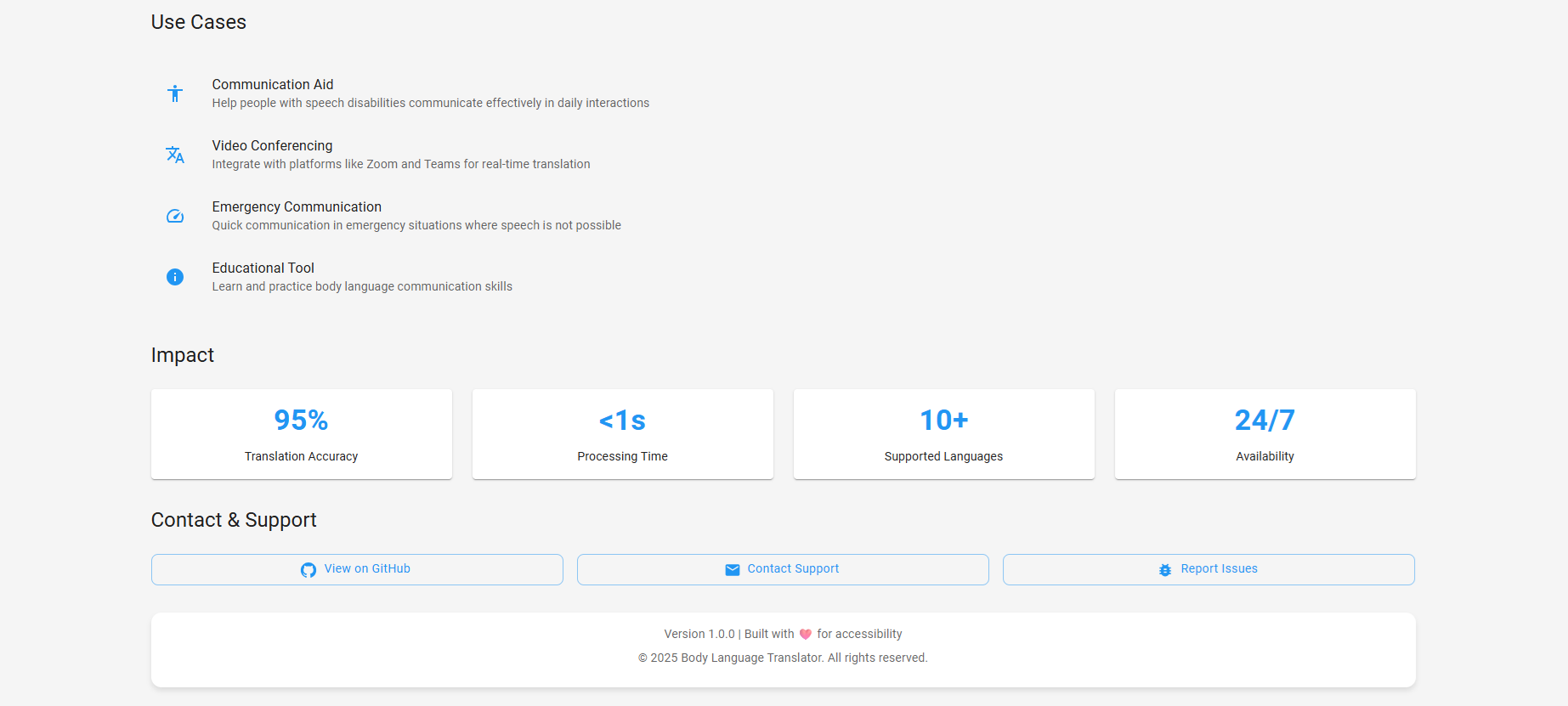
What it does
VoiceForEveryone enables real-time, two-way translation between body language and natural human language. Users can type or speak, and the app converts their input into gestures or ASL animations. Likewise, gestures performed by a user are translated into text and audio for others. It makes them to be involved more in the society; for example, imagine a person visiting a bank and communicating directly with frontline staff through the app or an integrated device. Future plans include video call integration, with live translations displayed in a small, unobtrusive window at the bottom-right corner.
How we built it
- Body Language Detection: Extracts 3D keypoints of hands, face, and body using MediaPipe.
- ASL Processor: Converts gestures into ASL gloss sequences.
- Motion Dictionaries: How2Sign and WLASL provide professional motion capture and fallback vocabulary.
- GPT-OSS-120B: Handles context-aware human language understanding, converting text ↔ gesture instructions naturally.
- 3D Avatar Rendering: Renders gestures in real time with Three.js.
- Integration Layer: Combines all modules for real-time translation and display.
Role of GPT-OSS-120B
GPT-OSS-120B is the core text-based reasoning engine of the app. Its responsibilities focus on understanding and generating human language, not images or gestures. Specifically:
- Converts typed or spoken text into structured, detailed instructions for gestures or ASL glosses.
- Adds context, emotional tone, and intent to make translations natural.
- Interprets recognised gestures or ASL gloss sequences.
- Generates natural language text output with contextual understanding.
- Tracks conversation history to improve translation accuracy.
- Disambiguates gestures and ensures culturally sensitive interpretations.
Without it, the system could only do predefined gesture-to-text mapping, lacking context, intent, and nuance. It ensures fluid, human-like communication, making the app genuinely usable for individuals who are non-verbal or deaf.
Challenges we ran into
- Motion datasets don’t understand natural language.
- Maintaining real-time performance while rendering 3D avatars.
- Preserving context, intent, and emotional nuance in translations.
- Designing a system that can scale to video call integrations.
Accomplishments that we're proud of
- Having an idea that indeed makes the world a better place to live in.
- Developed a real-time, bidirectional translation system as a proof of Concept (PoC).
- Successfully combined AI reasoning (GPT-OSS-120B) with professional motion capture datasets.
- Built a modular, production-ready architecture ready for standalone or video call applications.
What we learned
- The power of GPT-OSS-120B
- How to merge human language understanding with technical motion data.
- The importance of context-aware AI in accessibility applications.
- Challenges and strategies for real-time inclusive communication tools.
What's next for Voice for Everyone
- Multi-language support beyond ASL.
- Advanced emotion and facial expression detection. Potential to use available sources of body language translations to make emotions more real.
- Customizable avatars and personalization.
- Full video call integration with live text, audio, and avatar translation.
- Optimisation for edge devices and GPU acceleration.
- Test the App with human users.
Built With
- accelerate
- aiofiles
- aiofiles-security-&-auth:-passlib
- aria-compliance
- asl
- asl-dictionary-development-&-testing:-pytest
- azure
- bitsandbytes
- blender
- chromadb
- chromadb-(vector-embeddings)-real-time-communication:-websockets
- cors-middleware
- embeddings)
- emotion
- eslint
- face)
- fastapi
- framer-motion
- git
- git-performance-&-accessibility:-caching
- google-cloud
- gpt-oss-120b-(core-reasoning)
- hands
- heroku
- high-contrast-mode
- how2sign
- httpx
- hugging-face-transformers
- input
- input-validation-cloud-&-deployment:-aws-s3
- javascript
- javascript-backend:-fastapi
- jest
- keyboard-navigation
- lazy-loading
- livekit
- livekit-audio-processing:-whisper-node
- material-ui
- mediapipe-(pose
- movenet
- netlify
- node.js
- npm
- numpy
- opencv
- opencv-3d-graphics-&-animation:-three.js
- pandas
- passlib
- pillow
- prettier
- pydantic
- pytest
- python
- python-multipart-ai/ml:-gpt-oss-120b-(core-reasoning)
- pytorch
- react
- react-webcam
- scikit-learn
- scikit-learn-computer-vision-&-pose-detection:-mediapipe-(pose
- smpl-x
- sqlalchemy
- sqlite
- starlette
- three.js
- typescript
- unity
- unreal-engine
- unreal-engine-frontend:-react
- uvicorn
- validation
- vector
- vercel;-docker-&-kubernetes-planned-datasets:-how2sign
- webrtc
- webrtc-databases:-sqlite
- websockets
- whisper-node
- wlasl
Log in or sign up for Devpost to join the conversation.