Inspiration
While building various AI tools, we noticed that producing high-quality voice content is still slow, expensive, and inaccessible for many. Whether you're a YouTuber, educator, or product creator, you shouldn't need a studio setup to sound professional. We envisioned a tool like “Canva for voice” — upload a short sample, get your AI voice, and generate audio instantly. That’s how Voice Clone was born.
What it does
- One-click voice cloning: Upload or record ~30 seconds of audio to generate a personalized AI voice model.
- Text-to-speech synthesis: Input any text and hear it spoken in your cloned voice, with controllable emotional tone.
- Voice library management: Create and manage multiple voice models across projects from a unified dashboard.
- Cloud-based audio sharing: Download generated audio or share via link—ideal for teams, clients, or collaborators.
How I built it
- Tech stack: Built with Next.js + Tailwind + shadcn/ui on the frontend; Supabase handles auth and storage; deployed via Vercel.
- Voice engine: Integrated a high-quality voice synthesis API to power real-time cloning and speech generation.
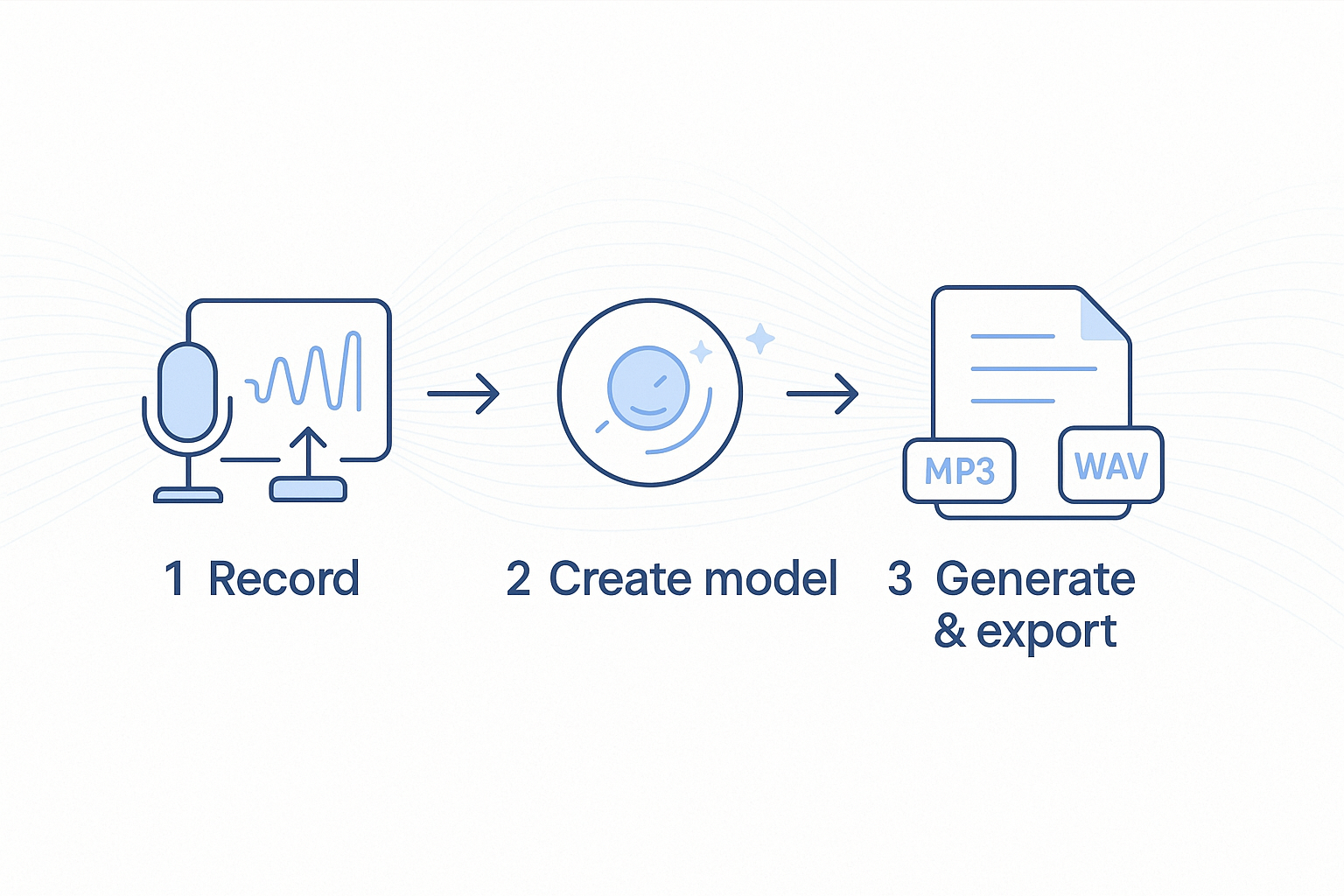
- Frontend flow: A simple three-step UX—record → verify → clone—lowers the entry barrier for non-technical users.
- Compliance layer: Each upload requires user consent; we block public figure voices and sensitive content by default.
Challenges I ran into
- Audio quality variability: Mobile recordings often introduced noise, which hurt cloning accuracy. We implemented auto-denoising and normalization to clean user input.
- Ethical concerns: Voice cloning poses clear risks for misuse. We built safeguards like ID verification, watermarking, and rate-limiting to reduce abuse.
Accomplishments that I'm proud of
- Launched a full-featured MVP in just six weeks with minimal infrastructure cost.
- Achieved competitive voice quality (MOS scores) comparable to major providers through blind listening tests.
What I learned
- Speed > Perfection: Users overwhelmingly prefer a “good-enough” voice clone in 5 minutes over a perfect one in 60.
- API abstraction is critical: Decoupling our frontend from the voice engine made backend iteration faster and safer.
- Compliance is not optional: Responsible voice AI must include consent workflows and identity safeguards from day one.
What's next for voice-clone
- Zero-shot cloning: Integrate cutting-edge open-source models for instant voice mimicry without training samples.
- Offline deployment: Use WebGPU + WASM to enable fully local voice cloning in-browser, preserving privacy.
- Voice model marketplace: Allow creators to license and monetize their voices—turning voice into a digital asset.


Log in or sign up for Devpost to join the conversation.