-
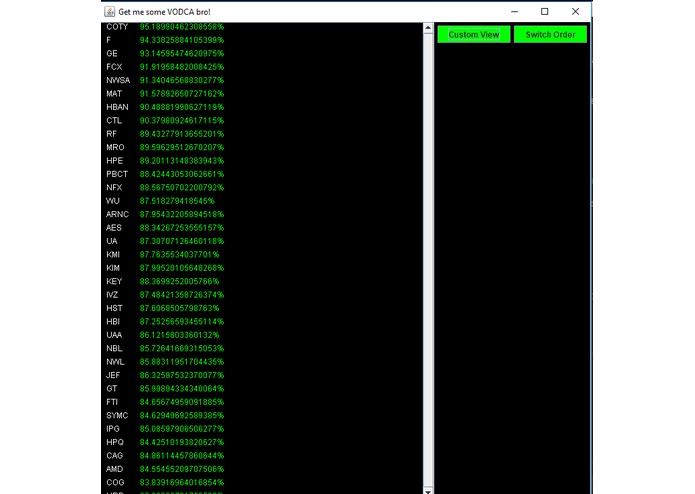
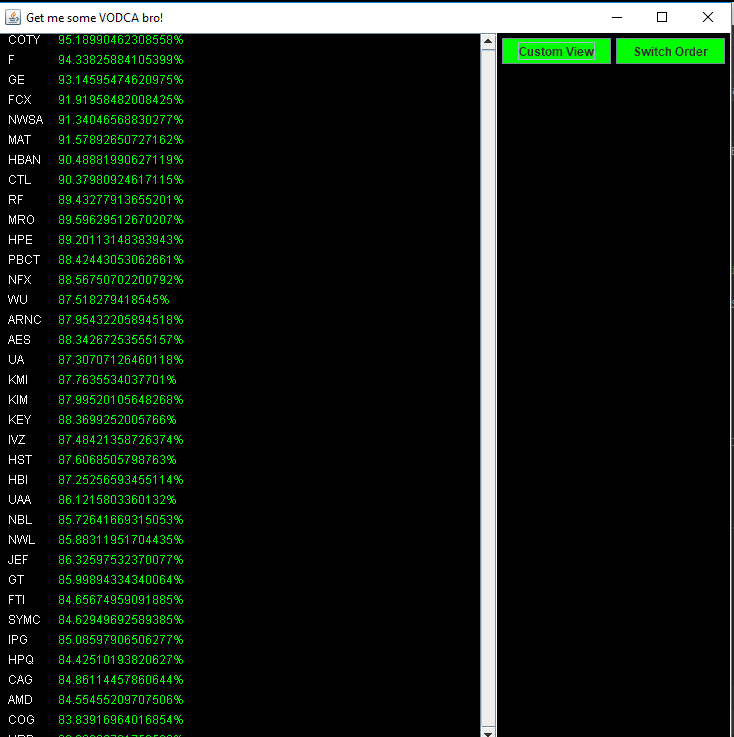
The main view of the best rated stocks
-
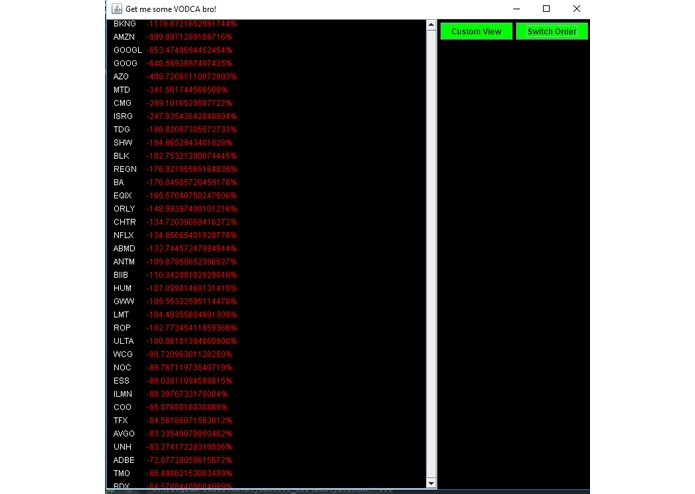
The main view of the worst rated stocks
-
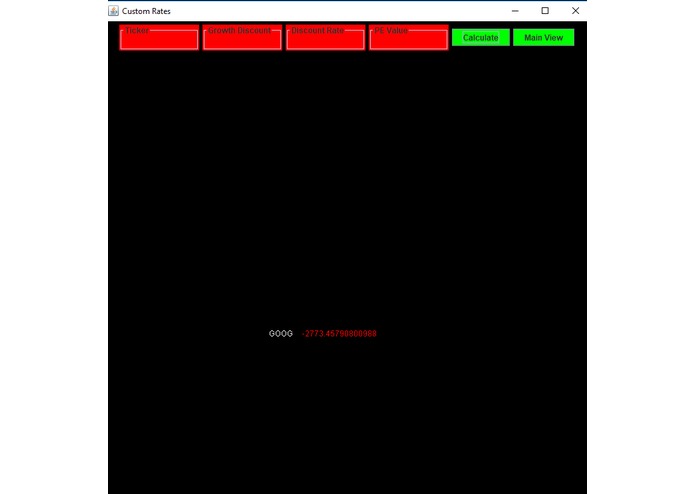
The custom view, where the user can enter their own rates for a stock. Here we just ran it on Google

Inspiration
We realized that there was massive potential in making a program like this, as we could not find a single one on the internet for public use. We have always been interested in investing and computer science, so we felt like this project would be a perfect fit for our abilities, time, and passion.
What it does
Scrapes the data from each web page for all 500 companies on the S&P 500, and determines how much the stock is over or undervalued from the data it collects.
How we built it
Used a python scraper to form all of the needed data into a JSON file, which then had a Model-View-Controller Java project parse through the JSON to formalize the data into something we could analyze. Then, we used Swing to make a comprehensive UI for the program as a whole.
Challenges we ran into
It took a long time to get the scraper up and running, and putting the JSONs all into one file. This was especially hard because none of us were too proficient in Python, so we had to learn as we went.
Accomplishments that we're proud of
The conversion from a massive amount of data on a website, to a easily parse-able file, to a easy to understand UI. We never really have done a project on this scope before outside of school, so it was amazing to see all of our hard work and quick learning really pay off.
What we learned
We learned more about the Swing library, and how to better work with it. We learned the basics of Python scripting, and we learned how to scrape the internet for data with Python.
What's next for VODCA
We need to do some more bug testing, since we were on a time constraint. Additionally, we hope to add more features to our program to get it more exact - there is more than one way to find what we were looking for, so it would be useful to implement that and take the averages of the different methods. Finally, we hope to actually use our program to help people invest in worthwhile companies.

Log in or sign up for Devpost to join the conversation.