-
-
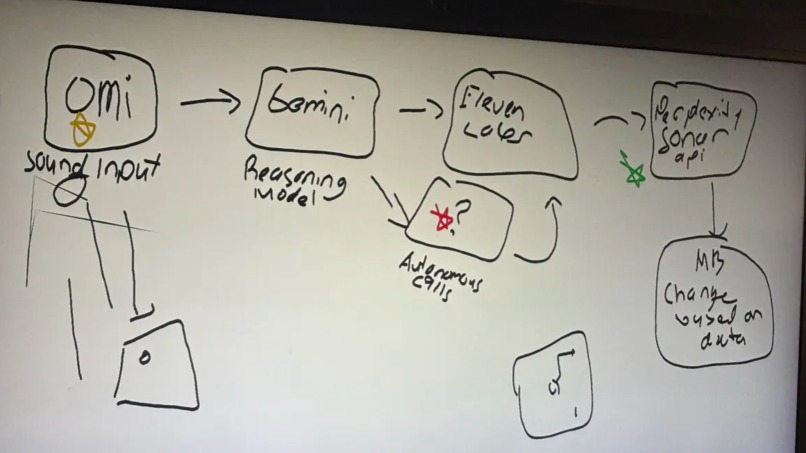
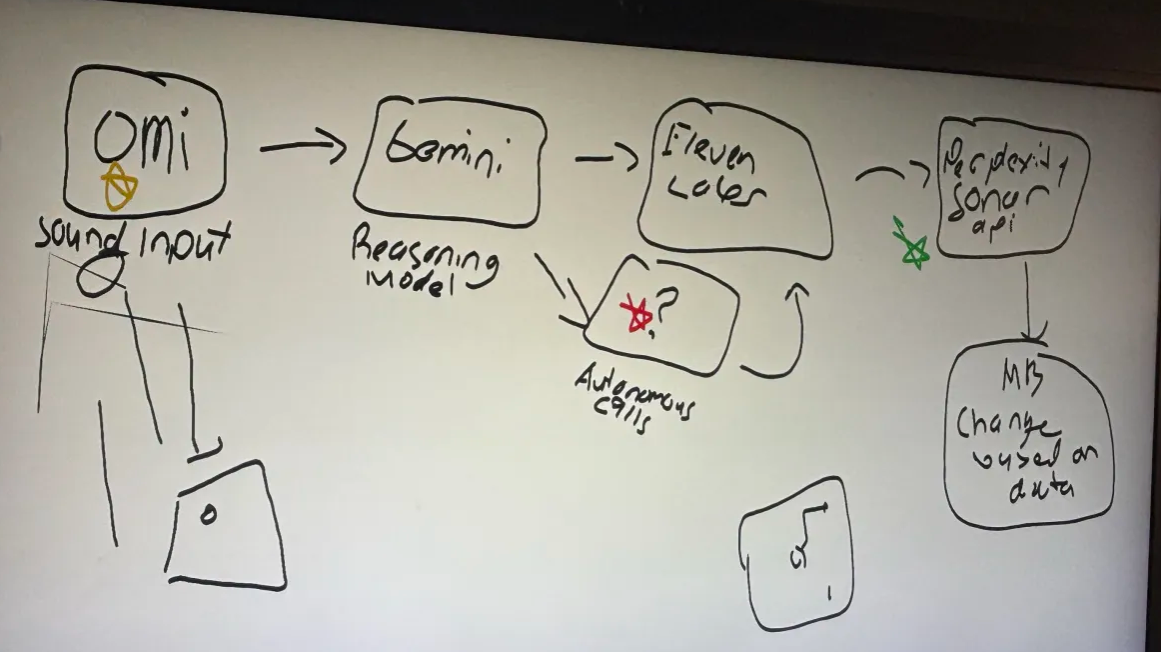
Draft of Initial System Architecture
-
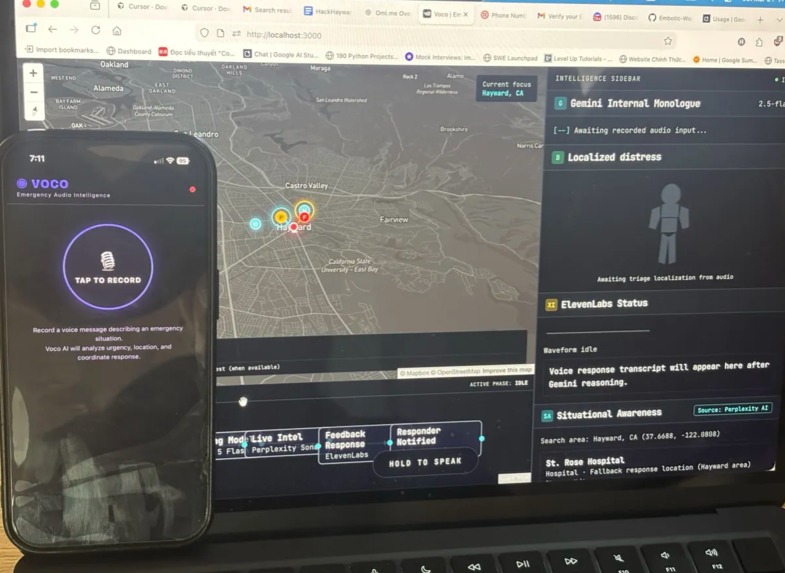
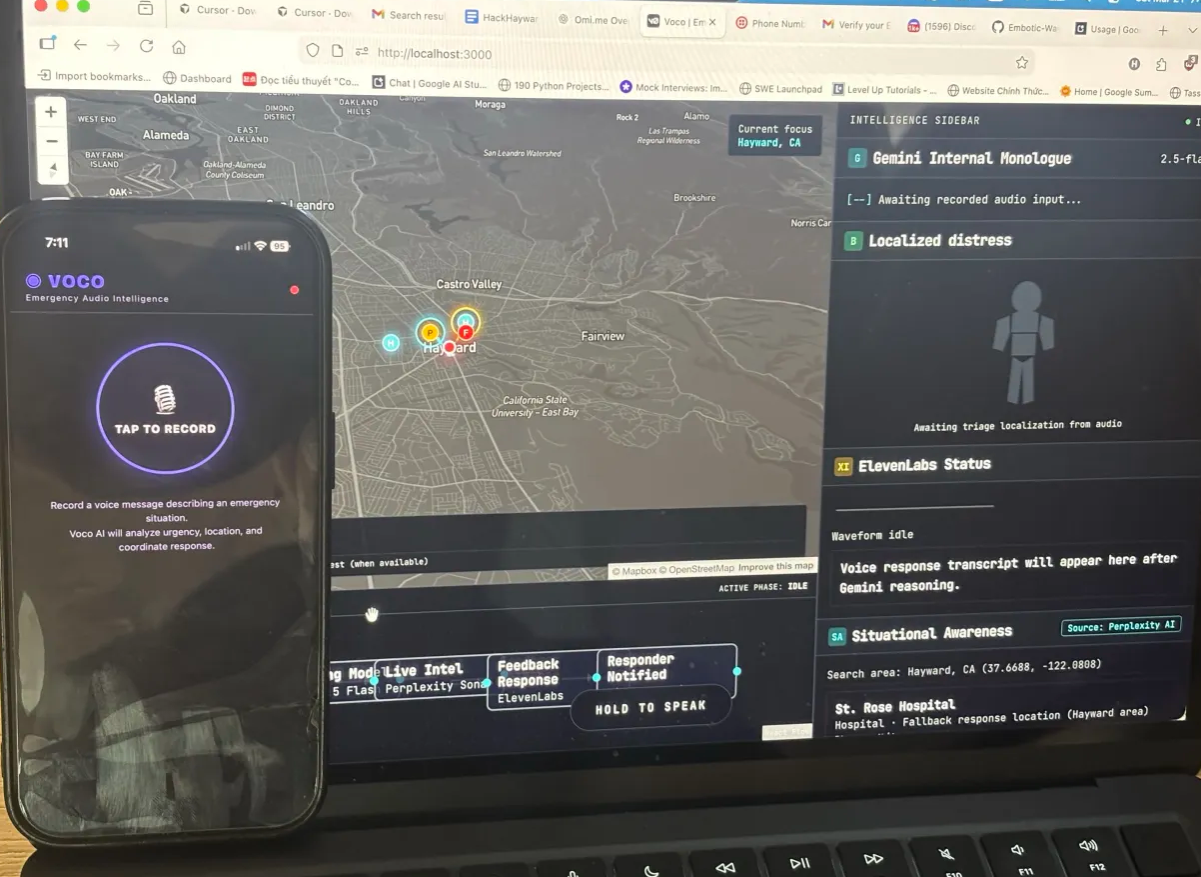
Voco Development Process
Inspiration 🚀
Emergency calls are high-stakes—dispatchers need fast situational clarity: what the caller said, where they are, who’s nearby, and what to say back—without drowning in tools.
We were inspired by mission-style ops dashboards (clear phases, live map, synthesized voice) and the idea that voice should drive the workflow, not forms. Voco is our take on an AI-assisted emergency brain that listens, reasons, and surfaces actionable context in one place.
What it does 🛠️
Voco is a voice-first emergency triage dashboard. A user holds to speak; the app sends audio to the backend, which:
Uses Gemini to analyze distress audio, infer location, produce an internal monologue (tactical reasoning), and generate a calming voice script. Pulls live facility context (hospitals, police, fire) via Perplexity around the inferred area. Runs multi-agent-style evaluations (impact, severity, dispatcher/first-responder guidance). Infers localized distress (body-region triage) for visualization. Speaks the response with ElevenLabs TTS and can broadcast a shareable emergency audio URL for synced playback across devices. Displays everything on a Mapbox map with a pipeline graph (intake → reasoning → TTS → notified).
How we built it ⚙️
Frontend: Next.js (App Router), React, Tailwind, Framer Motion, Mapbox (react-map-gl), React Flow for pipeline visualization.
Backend: API routes (/api/process, /api/tts), Perplexity integration, OMI routes, emergency audio token serving.
AI: Gemini (multimodal + structured outputs), Perplexity (facility search), ElevenLabs (TTS).
Realtime: Socket.io on a custom Node server so HTTP + WebSockets run together; in-memory store for short-lived audio URLs.
Tooling: Env-based configs, optional ngrok for testing on phones, remote-only audio playback support.
Challenges we ran into 😤
Getting reliable structured JSON output from Gemini (handling markdown wrapping and schema drift). Mobile browser autoplay restrictions requiring user interaction before audio playback. Syncing audio across devices with real URLs and handling CORS/origin issues. Running Socket.io with Next.js required a custom server setup. Networking issues with ngrok, firewalls, and matching app URLs. Integrating both mic input and OMI/webhook streams into one consistent UI flow.
Accomplishments that we're proud of 🎉
Built a cohesive command center: voice → reasoning → map → response. Unified dual inputs (microphone + OMI/webhook streams) into one system. Enabled multi-device workflows (phone for audio, laptop for control). Integrated real-time responder data tied to inferred location. Solved deployment challenges while keeping the project demo-ready.
What we learned 🧠
Multimodal AI needs strict output handling (JSON mode, parsing, retries). UX decisions (like where audio plays) are constrained by browser behavior. A monolithic dev server simplifies development but complicates production scaling. Normalizing multiple data streams into one state model keeps the system maintainable.
What's next for Voco 🚀
Production-ready realtime with managed WebSockets, auth, and multi-tenant support. PSAP integrations to export summaries and location data to dispatch systems. Stronger safety features: confidence scores, human verification, audit logs. Faster pipelines with streaming STT + LLM and multilingual support. Clear safety boundaries, disclaimers, and abuse monitoring for real-world use.
Built With
- elevenlabs
- gemini
- next.js
- perplexity
- typescript

Log in or sign up for Devpost to join the conversation.