-
-
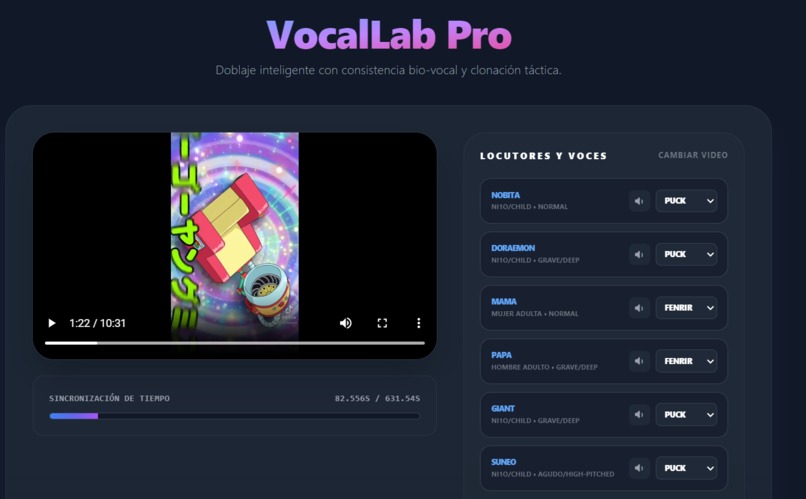
VocalLab Pro Interface
-
VocalLab Pro Interface
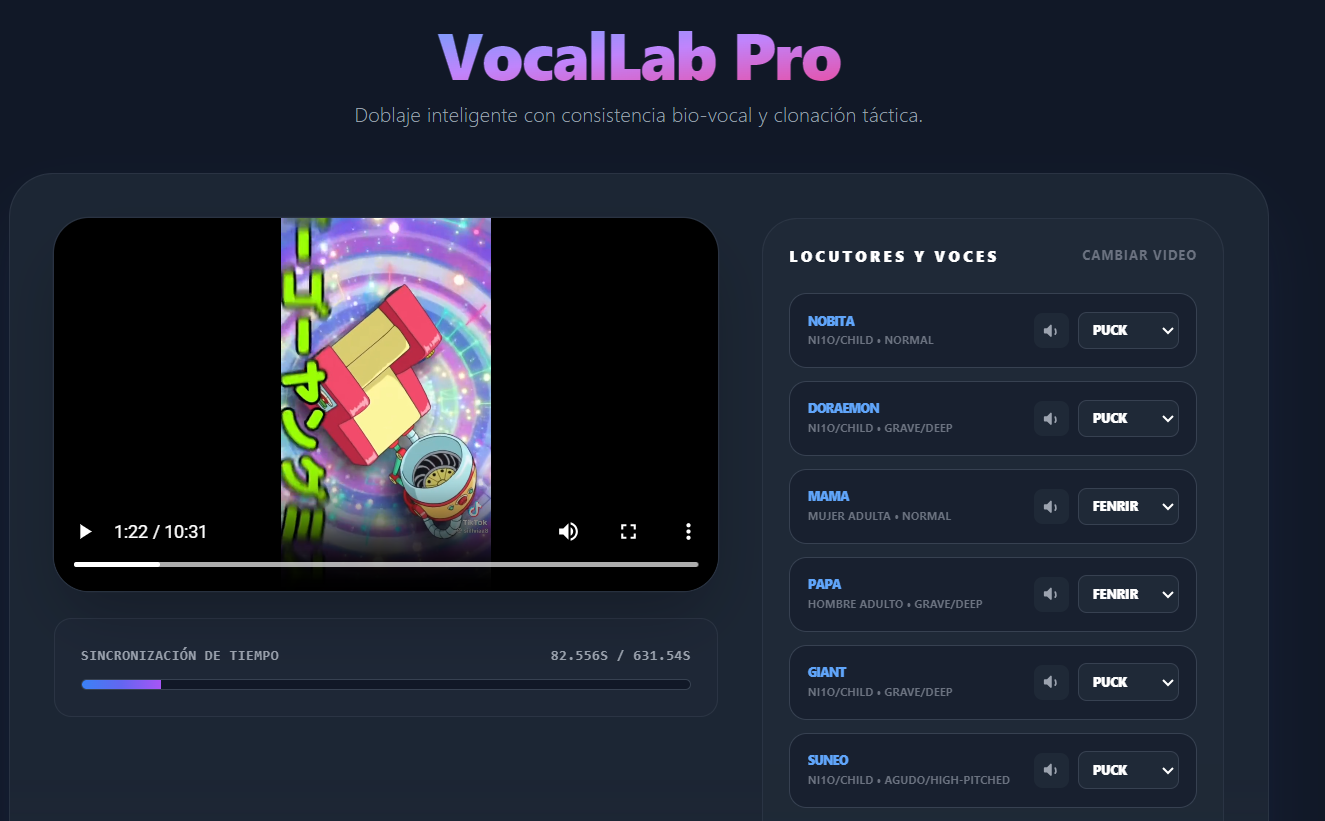
Inspiration
The spark for VocalLab Pro came from a very real problem. While developing the initial prototype, I received a message from a radio producer who was desperate. He needed to produce dramatic reenactments for a show but had zero budget for voice actors. He asked: "Do you know a tool that doesn't just read, but can ACT? That can reproduce human emotions like fear, anger, or sadness?"
That was the "Aha!" moment. Existing dubbing tools are robotic and flat. They translate words, but they kill the vibe. I realized that to break language barriers, we don't just need a translator; we need an AI Director.
What it does
VocalLab Pro is an automated video dubbing platform that prioritizes emotional context. Unlike standard dubbing tools that simply map text-to-speech, VocalLab Pro uses *Gemini * to "watch" the video and "listen" to the audio simultaneously.
It detects:
- Who is speaking (Speaker Diarization).
- The visual context (Is the character crying? Are they whispering?).
- The sentiment (The emotional intent behind the words).
It then generates a translated audio track that matches not just the meaning, but the feeling of the original performance.
How we built it
The core of the application is a Python-based pipeline orchestrated by the Gemini API.
- Ingestion & Diarization: We process the video to separate audio tracks and identify distinct speakers using standard diarization models.
- Multimodal Analysis (The "Secret Sauce"): This is where Gemini shines. We feed both the audio segment and the corresponding video frames to Gemini.
- We ask Gemini to act as a "Dubbing Director".
- It analyzes the scene to determine the correct translation (handling context-dependent words like Japanese pronouns) and the emotional parameters for the voice generation.
- Adaptive Translation: Gemini rewrites the translation to match the timing of the original speaker, aiming for isochrony (matching the length of the spoken phrase).
- Synthesis: The system generates the final audio using these emotion-rich prompts and merges it back into the video.
Challenges we faced
- The "Robotic" Barrier: Getting a TTS engine to sound truly "sad" or "excited" based on code was difficult. We had to heavily fine-tune our prompts to get Gemini to output precise instructions for the audio generator.
- Synchronization: Aligning the translated audio (Spanish) with the original video (Japanese/English) is mathematically complex, as Spanish tends to use more syllables. We used Gemini to summarize and adapt phrases to fit the time constraints. $$T_{duration} \approx S_{syllables} \times R_{rate}$$ We had to optimize the rate ($R$) dynamically to fit the gap ($T$).
What we learned
We learned that multimodality is key to translation. You cannot accurately translate a movie script without seeing the movie. Gemini's ability to process video and text together allowed us to solve ambiguities that would have stumped a text-only model.


Log in or sign up for Devpost to join the conversation.