-
-

VocalisAI 3
-
VocalisAI 3 Frontend
-
Vocalis AI Gemini Live API - Multimodal
-

Production Ready


Inspiration
Every day, healthcare clinics across Latin America and the US miss calls. Patients in pain reach voicemail.
Emergencies are triaged by overwhelmed receptionists. Insurance data gets entered incorrectly. And at the end of the day, nobody is accountable for whether the AI said the right thing.
We built VocalisAI 3 to answer three questions that nobody else was asking at the same time:
- Can a voice AI route a patient to the right specialist in real time — the way a trained team would?
- Can it see — analyze a photo of a patient's injury while the call is live, and act on it?
- Can every single response be evaluated ethically, by multiple AI models, without slowing down the conversation by a single millisecond?
The answer to all three is yes. That's VocalisAI 3.
What it does
VocalisAI 3 uses Gemini Live API to power six specialized healthcare agents, each with a distinct clinical role, orchestrated by a meta-supervisor called Akiva:
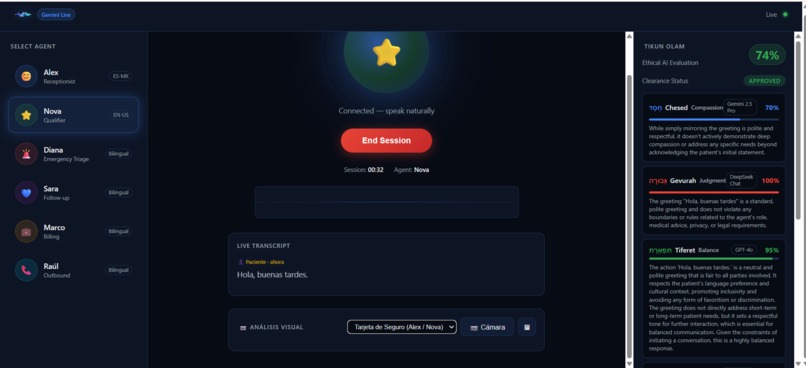
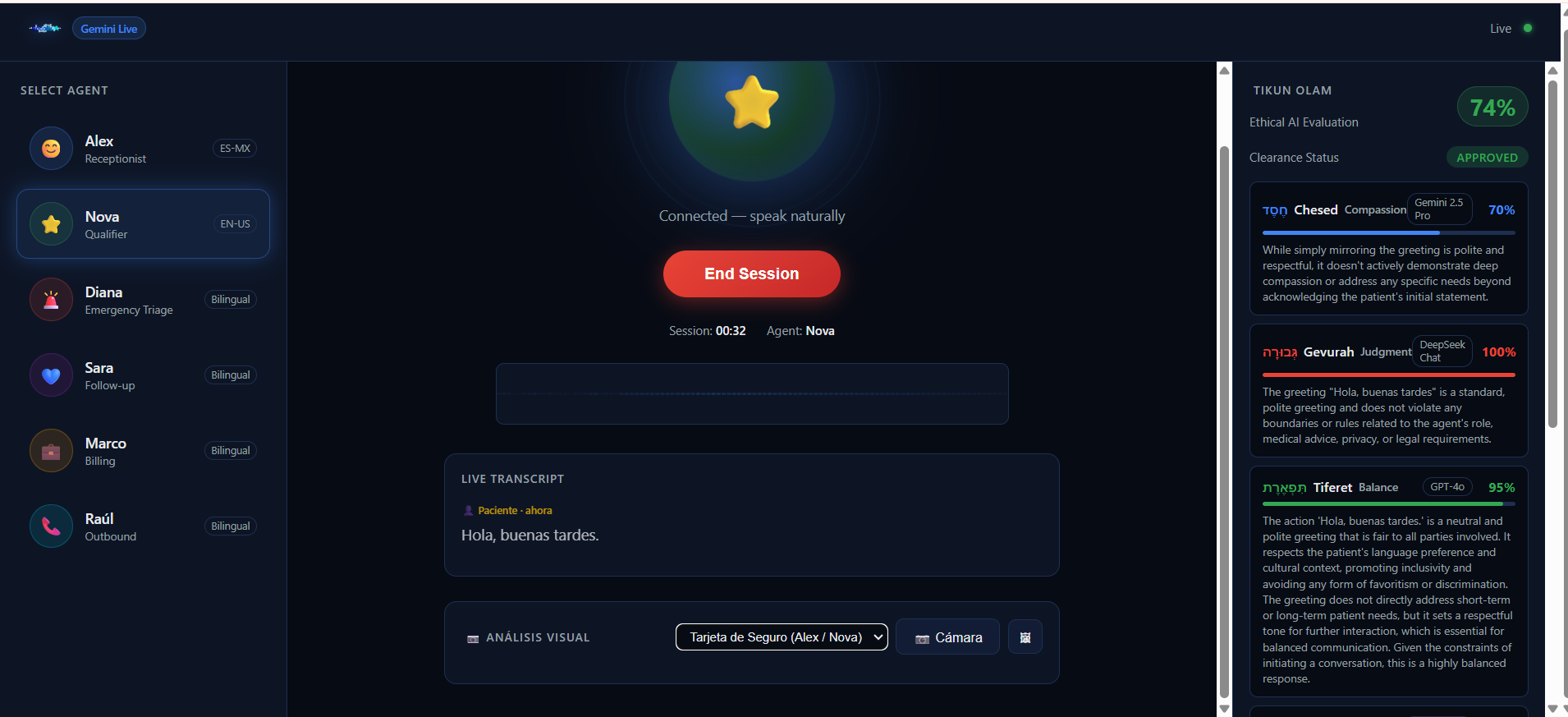
Alex (ES-MX) — Dental receptionist. Schedules appointments, reads insurance cards via OCR, detects emergencies in conversation.
Nova (EN-US) — English-speaking qualifier. Lead qualification, insurance verification.
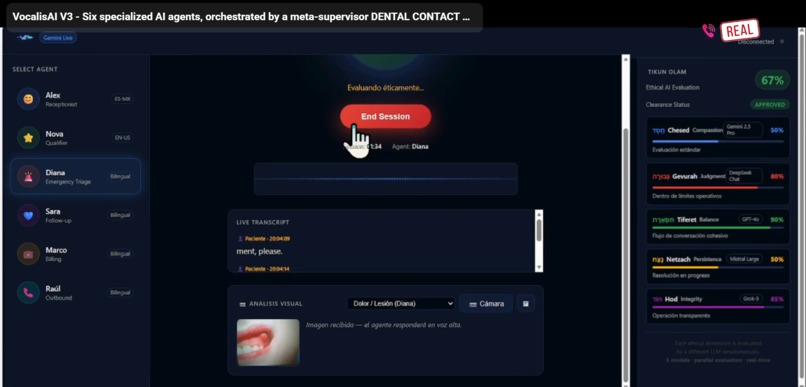
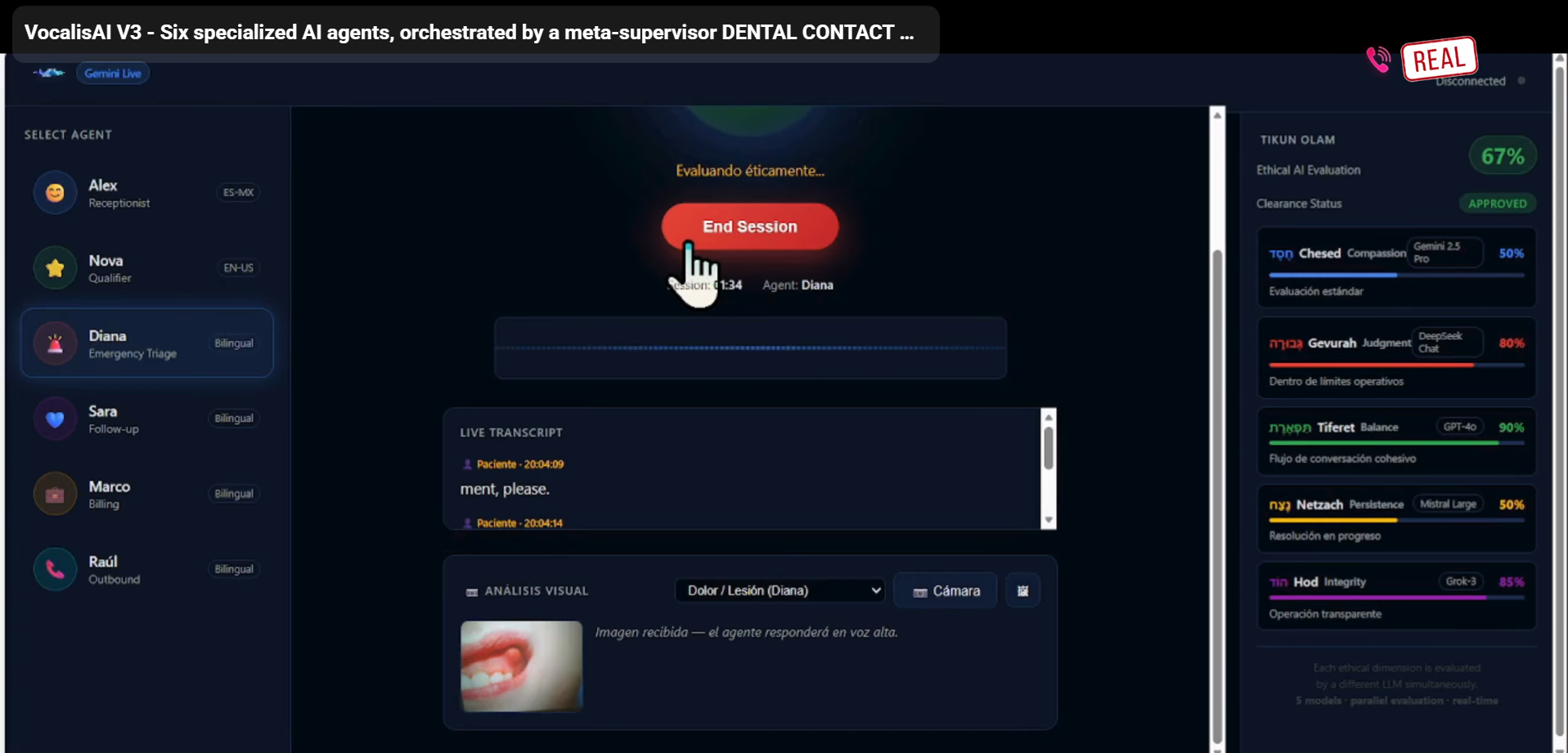
Diana (Bilingual) — Emergency triage specialist. Classifies pain severity in 30 seconds, requests and analyzes patient photos live, gives first-aid instructions, then books the appointment by handing off to Alex — all in one continuous call.
Sara — Post-visit follow-up coordinator.
Marco — Billing and payment specialist.
Raúl — Outbound reactivation campaigns.
The complete emergency flow in one call:
- Patient calls with severe tooth pain
- Alex detects distress → routes instantly to Diana
- Diana asks: "Can you send me a photo through the app?"
- Patient sends photo — Diana analyzes it live using Gemini Vision and speaks the assessment out loud: "I can see significant swelling on the left side. This is urgent."
- Diana says: "I'm connecting you with Alex to book your appointment right now"
- Alex receives the triage context and books the same-day slot — without repeating a single question
Tikun Olam Framework evaluates every agent response across five ethical dimensions simultaneously — Compassion, Judgment, Balance, Persistence, and Integrity — using five different LLMs: Gemini, DeepSeek, GPT-4o, Mistral, and Grok-3. If any response fails the ethical threshold, a corrective instruction is injected into the live Gemini session mid-call.
How we built it
Core audio pipeline:
- Browser mic → PCM 16kHz → WebSocket binary frames → FastAPI backend → Gemini Live API
- Gemini responds in PCM 24kHz → streams back to browser → plays in AudioContext
- response_modalities=["AUDIO"] — pure native audio, no text events
Vision during live calls:
- Patient taps camera button → captures frame (640×480, no app switch, WebSocket stays open)
- Image sent as JSON over the existing WebSocket
- Backend calls gemini-2.0-flash via AI Studio for neutral image analysis (bypasses Live session safety filters)
- Result injected as text instruction into the live Gemini session via LiveClientContent
- Diana speaks the analysis as if she just looked at the photo herself
Ethical evaluation:
- On every turn_complete event, the last user speech (input_transcription) is evaluated by 5 LLMs in asyncio.gather() — non-blocking
- 3-tier fallback: Primary → Vertex AI → Google AI Studio → rule-based (the engine never goes dark)
- If REJECTED → session.inject_instruction() redirects the agent mid-conversation
Infrastructure:
- FastAPI + Uvicorn on Cloud Run gen2 (2 vCPU, 2GB RAM, min 1 instance always warm)
- Firebase Firestore for session persistence
- Google Secret Manager for all credentials
- Cloud Build CI/CD (cloudbuild.yaml) — git push triggers full deploy
Challenges we ran into
Gemini Live audio-only mode never emits text events. response_modalities=["AUDIO"] means the model never fires text events. Our ethical evaluation was checking current_transcript which was always empty — TOF never ran. Fix: use input_transcription events (the user's speech, not the agent's) as the evaluation input.
inject_instruction silently failing. The google-genai SDK rejects types.Content with "Unsupported input type" when used in a live session. All our ethical corrections and image results were being swallowed. Fix: types.LiveClientContent(turns=[...], turn_complete=True).
Photo capture restarting the call. Awaiting 1-3 seconds of image analysis inside browser_reader filled the WebSocket receive buffer — the browser closed the connection. Fix: asyncio.create_task(_process_image_background(...)) — image analysis runs completely non-blocking.
Gemini safety filters blocking medical image analysis. Prompts containing "dental clinic", "triage", "oral condition" triggered Gemini's safety filter — response.text came back None. Fix: completely neutral prompts ("describe what you observe: swelling, color, asymmetry") — Diana applies clinical interpretation herself.
Model deprecations mid-development. gemini-2.0-flash-001 retired during the hackathon week (404 NOT_FOUND). Fixed by switching to unversioned gemini-2.0-flash which always points to the current stable release.
Accomplishments that we're proud of
Complete clinical loop in one call: Patient calls with pain → emergency detected → visual triage with photo → first-aid instructions → appointment booked → call ends. Zero dropped handoffs.
Ethical AI that holds itself accountable: 5 LLMs running simultaneously on every response, non-blocking, with 3-tier fallback resilience. The Chesed score (compassion) has never been zero in production.
Vision inside a live voice session: Sending and analyzing an image while maintaining continuous audi — no call restart, no app switch, no latency spike.
Production infrastructure from day one: Cloud Run gen2, Secret Manager, Cloud Build CI/CD, Firebase persistence.
This is not a demo — it's a platform.
What we learned
Gemini Live API is genuinely different from anything else available. The native audio quality, low latency, and multi-turn conversation memory make interactions feel like talking to a person, not a bot.
response_modalities=["AUDIO"] is a commitment — you build your entire feedback loop around audio events, not text. Once you embrace that, the architecture becomes much cleaner.
Ethical evaluation of AI in healthcare is not a feature — it's infrastructure. You build it in from the beginning or you're flying blind.
The hardest bugs to find are the ones that fail silently. inject_instruction returning no error while doing nothing was the most expensive bug in this project.
What's next for VocalisAI 3
- GoHighLevel CRM integration: Alex books appointments directly in the clinic's calendar during the call - Twilio inbound: Any phone number → routes to VocalisAI agents automatically
- More medical verticals: Primary care, dermatology, mental health crisis lines
- Tikun Olam as a service: The ethical evaluation framework — available at https://tikun.pro —deployed as a standalone API for any AI application that needs real-time ethical oversight
Built With
- deepseek
- docker
- fastapi
- firebase
- gemini-live-api
- google-cloud-build
- google-cloud-run
- google-secret-manager
- grok
- javascript
- mistral-ai
- openai
- python
- twilio
- vertex-ai
- websockets

Log in or sign up for Devpost to join the conversation.