
Inspiration
Product video creation is one of the most time-consuming bottlenecks in e-commerce. A single 30-second product promo video typically requires a scriptwriter, a photographer, a video editor, and days of turnaround — making it inaccessible to small sellers and independent creators.
We asked: What if an AI team could do all of this in under 10 minutes?
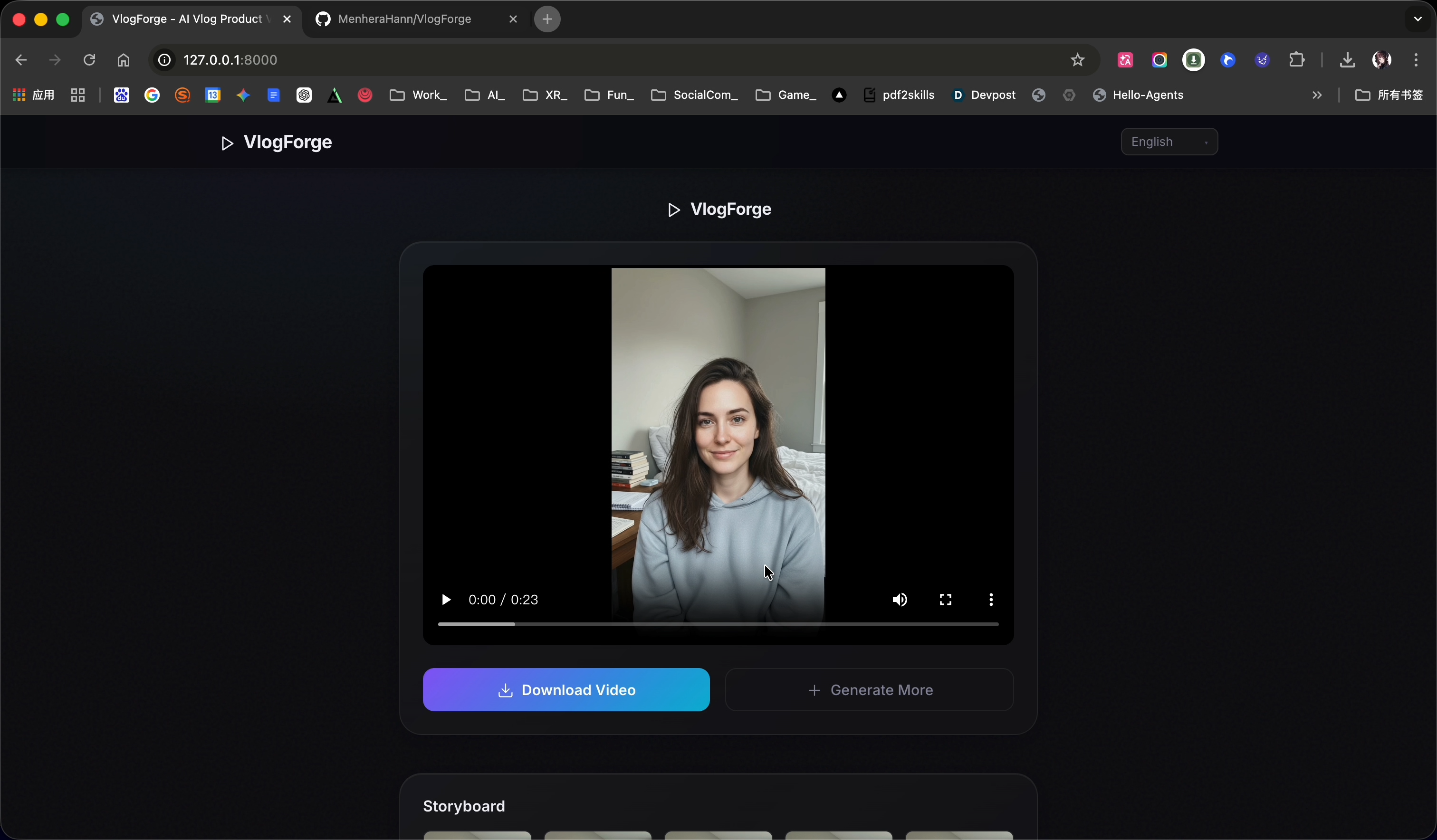
VlogForge was born from that question — a fully automated AI video production pipeline where four specialized Gemini-powered agents collaborate to transform a product photo and a one-sentence description into a polished, narrated vertical video ad.
## What it does
VlogForge orchestrates a 4-agent pipeline that mimics a real production team:
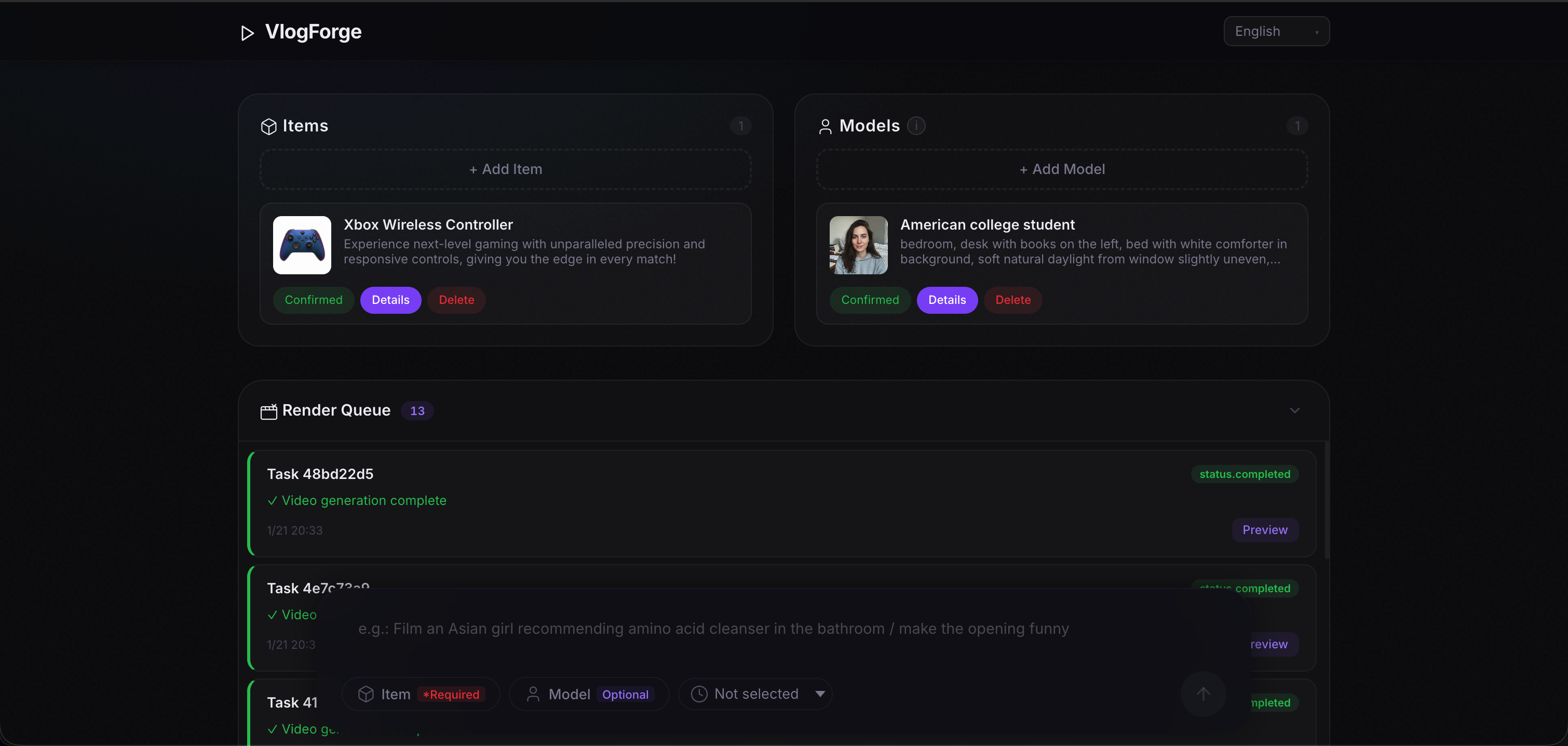
- ADA (Asset Designer) — Analyzes product photos, generates structured profiles via smart questionnaires, and creates reference images using Gemini 2.5 Flash + Nano Banana Pro.
- DA (Creative Director) — Writes the full video script with built-in self-evaluation, then orchestrates the entire downstream pipeline using Gemini 2.5 Flash.
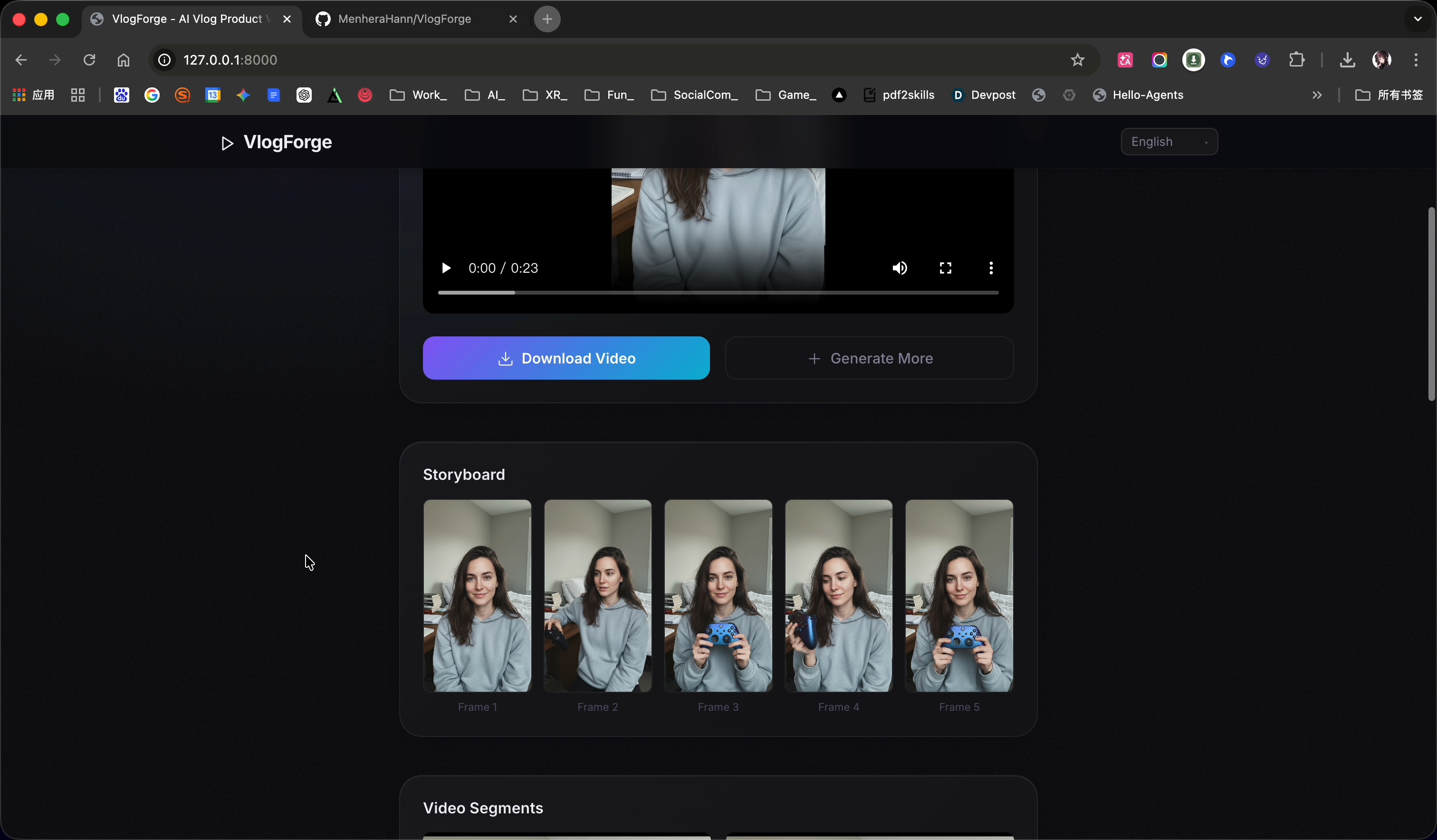
- VA (Visual Director) — Generates N+1 storyboard keyframes in parallel from reference images via Nano Banana img2img.
- VGA (Video Editor) — Produces video segments using Veo 3.1 Preview's first-frame/last-frame mode, with MSE-based smart trimming.
The final output is a seamless, voice-narrated 18–60s vertical video with consistent character appearance, fixed-camera composition, and natural speech pacing — ready to post.
## How we built it
### Architecture: Sequential Stages, Parallel Within
The pipeline follows a strict 4-stage flow:
$$\text{ADA} \xrightarrow{\text{assets}} \text{DA} \xrightarrow{\text{script}} \text{VA} \xrightarrow{\text{storyboard}} \text{VGA} \xrightarrow{\text{segments}} \text{FFmpeg} \rightarrow \text{final.mp4}$$
Between stages, execution is sequential (each stage depends on the
previous output). Within stages 2 and 3, generation is fully parallel —
all storyboard frames and all video segments are produced concurrently with
asyncio.Semaphore(3) for rate limiting. This achieves ~3x speedup over
sequential generation while avoiding cumulative drift.
### Key Technical Innovations
Self-Check Loop — DA doesn't just generate a script; it scores its own output across 4 dimensions (person accuracy, product fidelity, scene context, overall quality) on a 1–5 scale. If any dimension falls below the threshold, it automatically re-generates with targeted feedback:
$$\text{if } \min(s_{\text{person}}, s_{\text{product}}, s_{\text{scene}}, s_{\text{quality}}) < 4 \implies \text{retry with feedback}$$
Frame Chain Continuity — Adjacent video segments share a boundary frame. We enforce a hard constraint:
$$\text{Segment}n.\text{frame_end} \equiv \text{Segment}{n+1}.\text{frame_start}$$
This is validated at the prompt level before any generation begins, with automatic retry on violation.
Smart Trim — Veo 3.1 sometimes "drifts" past the target end frame. We solve this by extracting frames from the video tail, computing MSE against the target image, and surgically trimming at the best-match point:
$$\text{trim_point} = \arg\min_{t} \text{MSE}\big(\text{frame}(t),\ \text{target_image}\big)$$
Voice Anchor — DA generates a detailed voice profile (gender, age, tone, pace, accent) that is prepended to every Veo prompt, ensuring cross-segment voice consistency without any post-processing.
Parallel-but-Consistent Storyboards — VA generates all frames independently from the same reference images (not chained from each other), anchored by a shared style guide. This avoids the cumulative appearance drift that plagues sequential img2img chains.
### Tech Stack
- Backend: Python 3.12, FastAPI, asyncio
- AI Models: Gemini 2.5 Flash (text), Nano Banana / Nano Banana Pro (image), Veo 3.1 Preview (video) — all via Vertex AI
- Video Processing: FFmpeg (stitching, smart trimming, overlap removal)
- Storage: Local + Google Cloud Storage dual-write pattern
- Deployment: Cloud Run with GCS persistence
- Frontend: Vanilla HTML/CSS/JS SPA with 6-language i18n, SSE real-time progress
## Challenges we ran into
Veo tail-frame drift — Veo 3.1 often generates beyond the target end frame, creating visible "jumps" between concatenated segments. Our MSE-based smart trim was the breakthrough solution after many failed attempts with fixed-length trimming.
Cross-segment consistency — Getting the same person to look identical across independently generated video segments was extremely difficult. We solved it through three layers: (a) shared reference images for all VA frames, (b) VA system instructions enforcing pixel-level replication, and (c) voice anchor ensuring consistent narration voice.
Frame chain validation at scale — Ensuring N+1 keyframes are all unique yet adjacent pairs are identical required a carefully designed validation + retry system with multiple fallback tiers.
Composition lock — The fixed-camera, upper-body-only constraint sounds simple but required enforcement at every layer: DA script prompts, VA frame instructions, and VGA Veo descriptions all had to independently enforce the same composition rules.
GCS dual-write for Cloud Run — Cloud Run's stateless containers meant every generated artifact needed to be persisted to GCS in real-time, while still keeping local file access for FFmpeg processing. The dual-write pattern with graceful fallback was essential.
## What we learned
- Agentic self-evaluation is powerful — Letting the DA score its own output and retry with feedback dramatically improved script quality without any human intervention.
- Parallel generation beats sequential — Breaking the chain dependency in storyboard generation was counterintuitive but eliminated drift and tripled throughput.
- Constraints make better videos — The fixed-camera, vertical-only, upper-body-only constraints actually improved output quality by giving the AI models a clear, narrow target to optimize for.
- The last 10% is 90% of the work — Getting a working prototype took days; making it production-ready (cancel support, error recovery, safety filters, GCS persistence, i18n) took weeks.
## What's next for VlogForge
- Real-time preview with streaming video generation
- Multi-take selection — generate multiple versions of each segment and let users pick the best
- Music and sound effects integration
- Horizontal video support for YouTube/desktop platforms

Log in or sign up for Devpost to join the conversation.