-
-
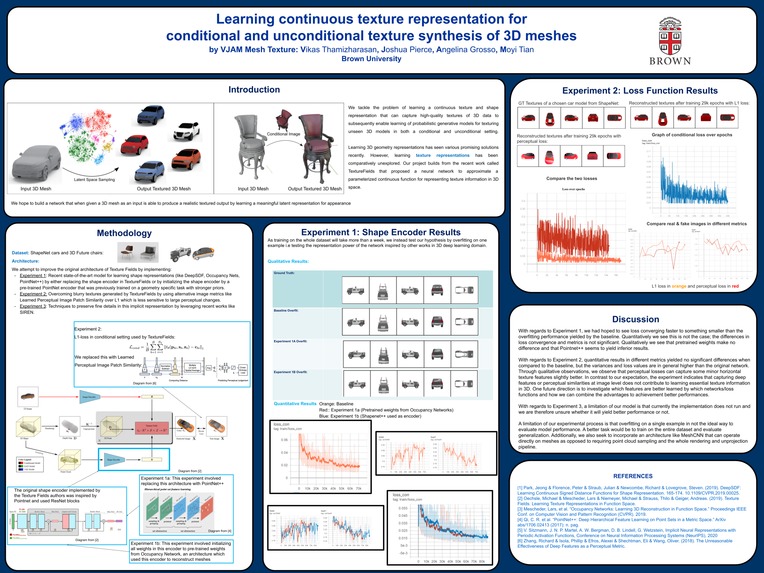
Final Poster

Link to Report and Poster:
https://drive.google.com/drive/folders/1JdhV4eeBJWe39aHnnyULdXeK8emzsdAj?usp=sharing
Link to Presentation:
Link to Code (Github):
https://github.com/vikasTmz/DeepTexture/
Old
Project Proposal:
https://docs.google.com/document/d/16Q4TFA0P68jeubrTiXg_Pg4GmG_r7SJckC1gc84bUMY/edit?usp=sharing
Project Check #1:
https://docs.google.com/document/d/1WORFHrXa6QjJeFUb985Z_xxgs0QdROVuMBpXJBuMuQ4/edit?usp=sharing
Project Check #2:
https://docs.google.com/document/d/1_S5nldyvXArzcM4zRLuDRYhnqxDdIYQQj-XMAEL-VKg/edit?usp=sharing
Built With
- 3d-future
- gan
- google-cloud
- graphics
- implicit
- neural
- python
- pytorch
- texture


Log in or sign up for Devpost to join the conversation.